
شو يعني معالجة البيانات؟ 🤔🧹
الداتا اللي بتيجينا من "الواقع" عمرها ما بتكون نظيفة أو جاهزة للاستخدام فوراً.
- التعريف: هي مجموعة تقنيات بنستخدمها عشان ننظف، نحول، ونجهز "الداتا الخام" (Raw Data) لتصير صالحة للتحليل والذكاء الاصطناعي.
- ليش ضرورية؟ لأن الداتا اللي بنجمعها غالباً بتكون ناقصة، فيها أخطاء، أو مش منسقة. خوارزميات الـ ML بتفترض إن الداتا نظيفة وموزعة صح، وأي خلل بالداتا رح يضرب دقة الموديل.
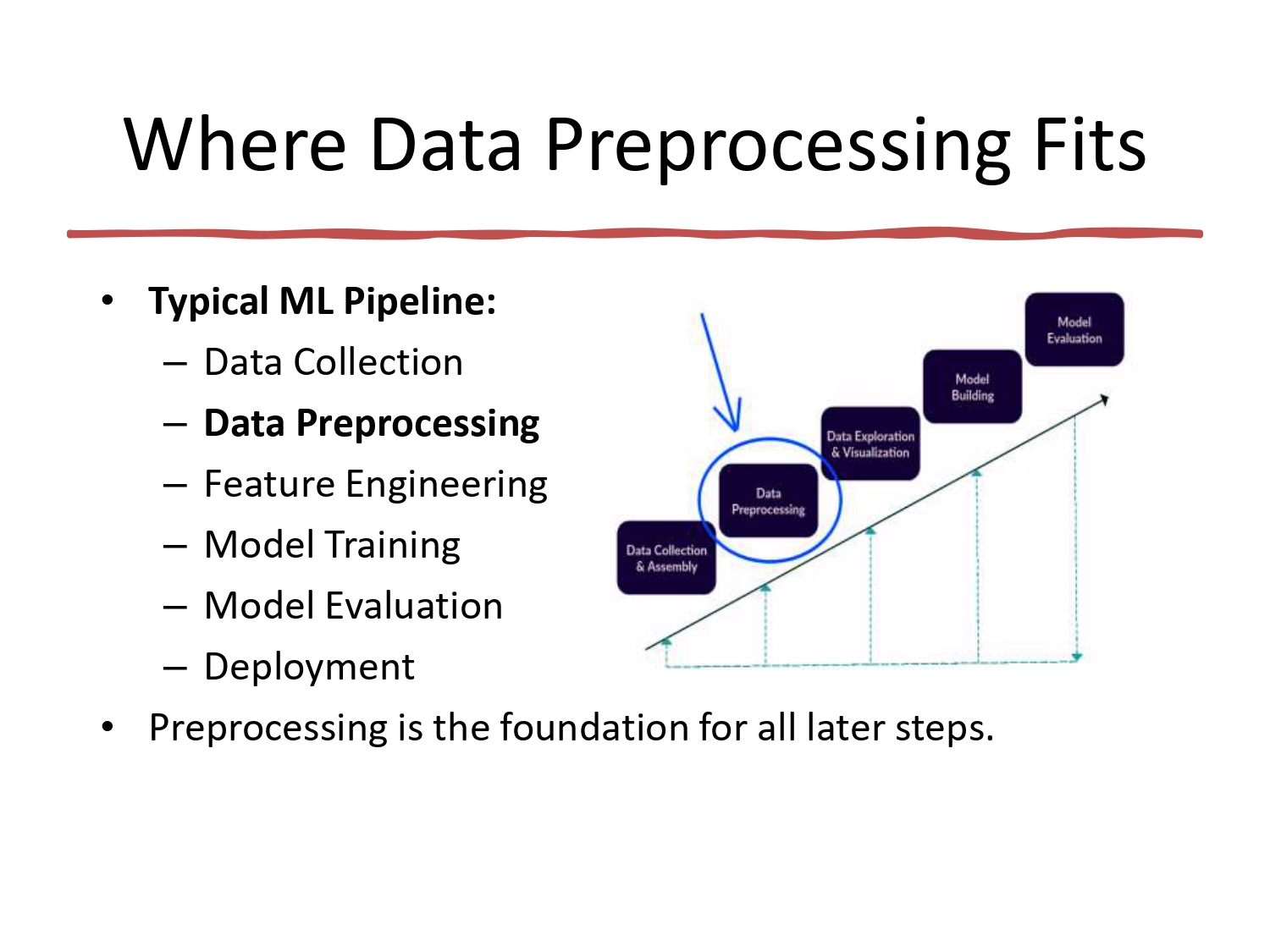
موقعها في خط الإنتاج 🏭📍
معالجة البيانات هي الجسر بين جمع الداتا وبين بناء الموديل.
أي مشروع ذكاء اصطناعي بمر بهي الخطوات:
جمع الداتا ⬅️ المعالجة (Preprocessing) ⬅️ هندسة الميزات ⬅️ التدريب ⬅️ التقييم.
تذكر دائماً: المعالجة هي الأساس، إذا الأساس خربان، الموديل كله رح يكون فاشل.
جمع الداتا ⬅️ المعالجة (Preprocessing) ⬅️ هندسة الميزات ⬅️ التدريب ⬅️ التقييم.

شو بدنا نحقق من كل هالتعب؟ 🎯✨
إحنا مش بس "بنسلي حالنا" وبنغير بالداتا، إحنا عندنا أهداف استراتيجية:
- تحسين الجودة (Quality): يعني الداتا تكون دقيقة وموثوقة، مش أرقام عشوائية بتطلع موديل "أهبل".
- التعامل مع النقص (Missing values): الخانات الفاضية هي أكبر عدو للموديل، لازم نعرف كيف نعبيها أو نتصرف معها بدون ما نخرب النتائج.
- التحويل الرقمي (Conversion): الموديل "ما بعرف يقرأ"، هو بس بحسب. فلازم نحول النصوص والرموز لأرقام يفهمها الخلاط تبعنا.
- المساواة (Scaling): تخيل ميزة قيمها بالآلاف وميزة قيمها من 0 لـ 1، الموديل رح "ينعجق" ويفكر الأولى أهم بس لأن أرقامها كبيرة. إحنا بنوحد المقاييس عشان تكون المنافسة شريفة (Fair Learning).
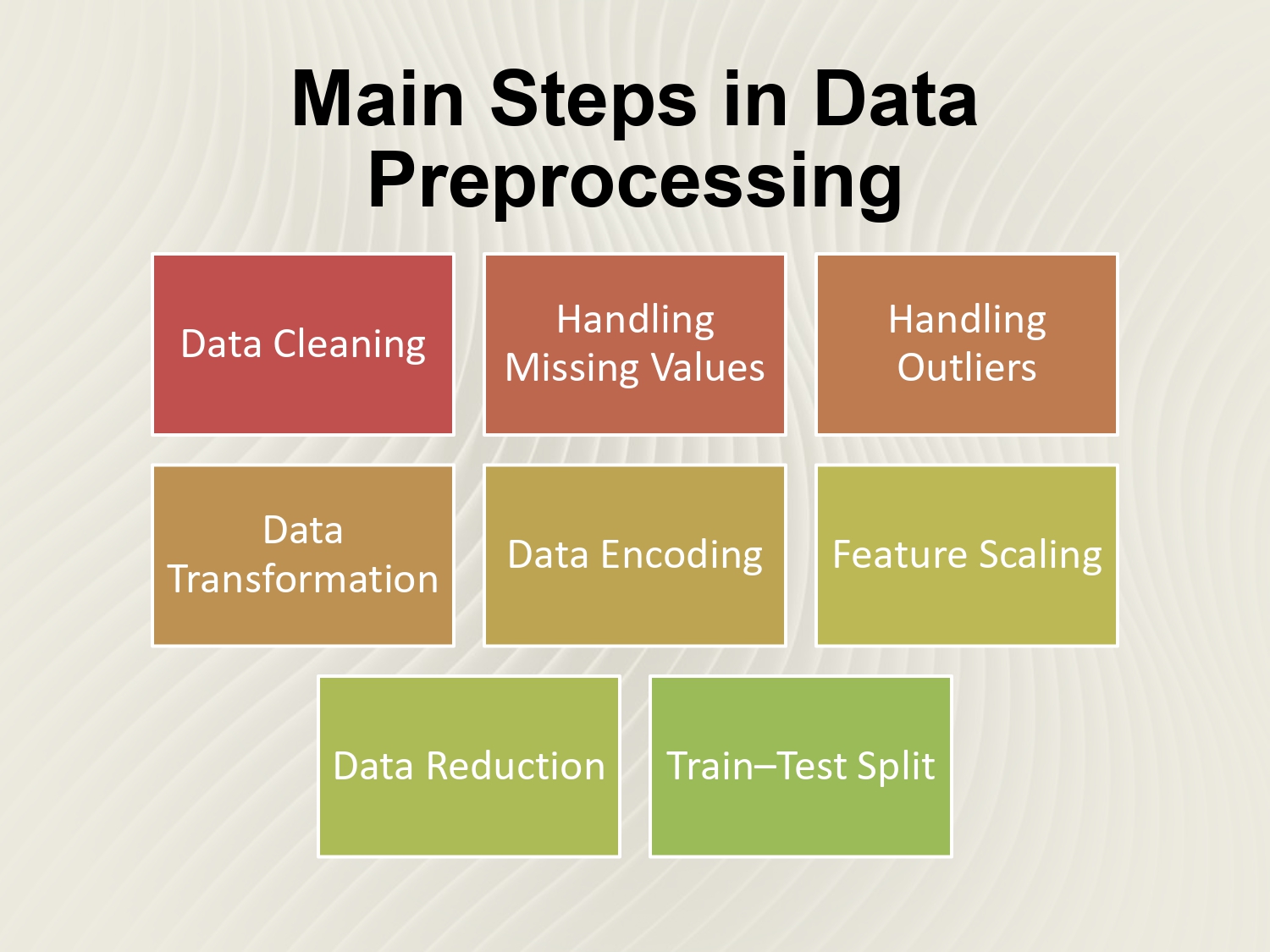
الـ 8 خطوات الأساسية بالترتيب 🗺️�
عشان نطلع داتا "بتشرح الصدر"، لازم نمر بهي الخطوات الثمانية:
1. Data Cleaning: تنظيف "الضجيج" والأخطاء الواضحة من الداتا ست.
2. Handling Missing Values: شو نعمل بالخانات الفاضية؟ نعبيها
ولا نحذفها؟
3. Handling Outliers: التعامل مع "القيم الشاذة" (زي واحد عمره
200 سنة) اللي بتخرب الحسابات.
4. Data Transformation: تحويل شكل الداتا (زي الـ Log transform)
لتناسب الموديل أكثر.
5. Data Encoding: تحويل النصوص (Categorical Data) لأرقام
بيفهمها الكمبيوتر.
6. Feature Scaling: توحيد المقاييس عشان ما في ميزة "تفرعن" على
الثانية بس لأن أرقامها كبيرة.
7. Data Reduction: إذا الداتا ضخمة بزيادة، بنحاول نختصرها بدون
ما نفقد المعلومات المهمة.
8. Train-Test Split: التقسيم الأخير، جزء للتدريب وجزء عشان
نمتحن الموديل فيه.

أولاً: تنظيف البيانات (Cleaning) 🧼🚿
هي عملية اكتشاف وتصحيح (أو حذف) البيانات الفاسدة، غير الدقيقة، أو غير المكتملة.
الهدف: نضمن إن الداتا متسقة (Consistent)، خالية من "الضجيج" (Noise)، وصحيحة مية بالمية قبل ما تدخل عالخلاط.

مشاكل شائعة وحلولها 🛠️🚑
شو هي الأشياء اللي بنظفها؟
- Duplicate records: سجلات مكررة (نفس الشخص مسجل مرتين).
- Invalid values: قيم مستحيلة (زي العمر يكون -5).
- Inconsistent units: وحدات مختلفة (ناس مسجلة وزنها بالكيلو وناس بالباوند).

الحل الجذري: الحذف (Deletion) ✂️🗑️
أسهل طريقة (بس مش دايماً أحسن طريقة) هي الحذف:
- Listwise Deletion: بنحذف "السطر" كله إذا فيه ميزة وحدة ناقصة. (سهل بس بضيع داتا كثير).
- Pairwise Deletion: بنحذف القيمة الناقصة بس في التحليلات اللي بتحتاجها، وبنخلي باقي السطر.
- Column Deletion: إذا فيه "عمود" (ميزة) أغلبه فاضي، بنحذف العمود كامل من الداتا ست.

معالجة القيم المفقودة (Missing Values) 🕳️🔍
القيم المفقودة هي ببساطة "خانات فاضية" في الداتا ست، وهي من أكبر المشاكل اللي بتواجهنا.
ليش النقص مشكلة بوجع الرأس؟
- معظم خوارزميات الـ ML "بتصفن" وما بتعرف تتعامل مع القيم الفاضية وبتعطيك Error.
- بتخرب التحليل الإحصائي وبتعطي نتائج مائلة (Biased).
- بتقلل من الحجم الفعلي للداتا اللي بنقدر نعتمد عليها.
أنواع النقص (عشان نعرف كيف نعالجها):
- MCAR (Completely at Random): النقص "صدفة محضة"، ماله علاقة بأي معلومة ثانية (مثلاً ورقة ضاعت هباءً).
- MAR (At Random): النقص اله علاقة بداتا ثانية إحنا شايفينها (مثلاً: الشباب غالباً ما بجاوبوا على أسئلة المشاعر بس بجاوبوا على غيرها).
- MNAR (Not at Random): النقص اله علاقة بنفس المعلومة اللي ناقصة (مثلاً: اللي راتبه فوق الـ 5000 ما بحب يسجل راتبه).

تقنية التعويض (Imputation) 💉🩹
بدل ما نرمي السجل كامل في الزبالة ونخسر معلومات الطلاب الثانية، بنستخدم الـ Imputation وهي عملية استبدال الفراغ بقيم "تقديرية" ذكية.
ليش هاي الطريقة بطلة؟
- بتخلي حجم الداتا ست زي ما هو وما بنخسر عدد السجلات.
- بتمنع ضياع المعلومات المفيدة اللي موجودة في باقي الأعمدة لنفس السجل.
- بتقلل الانحياز (Bias) اللي ممكن يصير لو حذفنا الداتا عشوائياً.

طرق عبي الفراغ: من البسيط للمتقدم 🧠🛠️
التعويض اله أكثر من مدرسة، وحسب نوع الداتا بنختار:
الطرق الشائعة (Common):
- Mean Imputation: بنحط المتوسط الحسابي (للداتا الرقمية).
- Median Imputation: بنستخدم الوسيط (ممتاز لما يكون فيه قيم شاذة "شاطحة").
- Mode Imputation: بنستخدم الأكثر تكراراً (للأشياء النصية أو التصنيفات).
- Constant Value: بنحط قيمة ثابتة من عندنا (زي 0 أو "Unknown").
الطرق المتقدمة (Advanced):
- KNN Imputation: بنشوف أقرب سجلات مشابهة وبناخذ متوسطهم.
- Regression Imputation: بنستخدم موديل يتوقع القيمة بناءً على الميزات الثانية.
- Multiple Imputation: بنعمل أكثر من نسخة للداتا عشان نضمن الدقة واليقين.
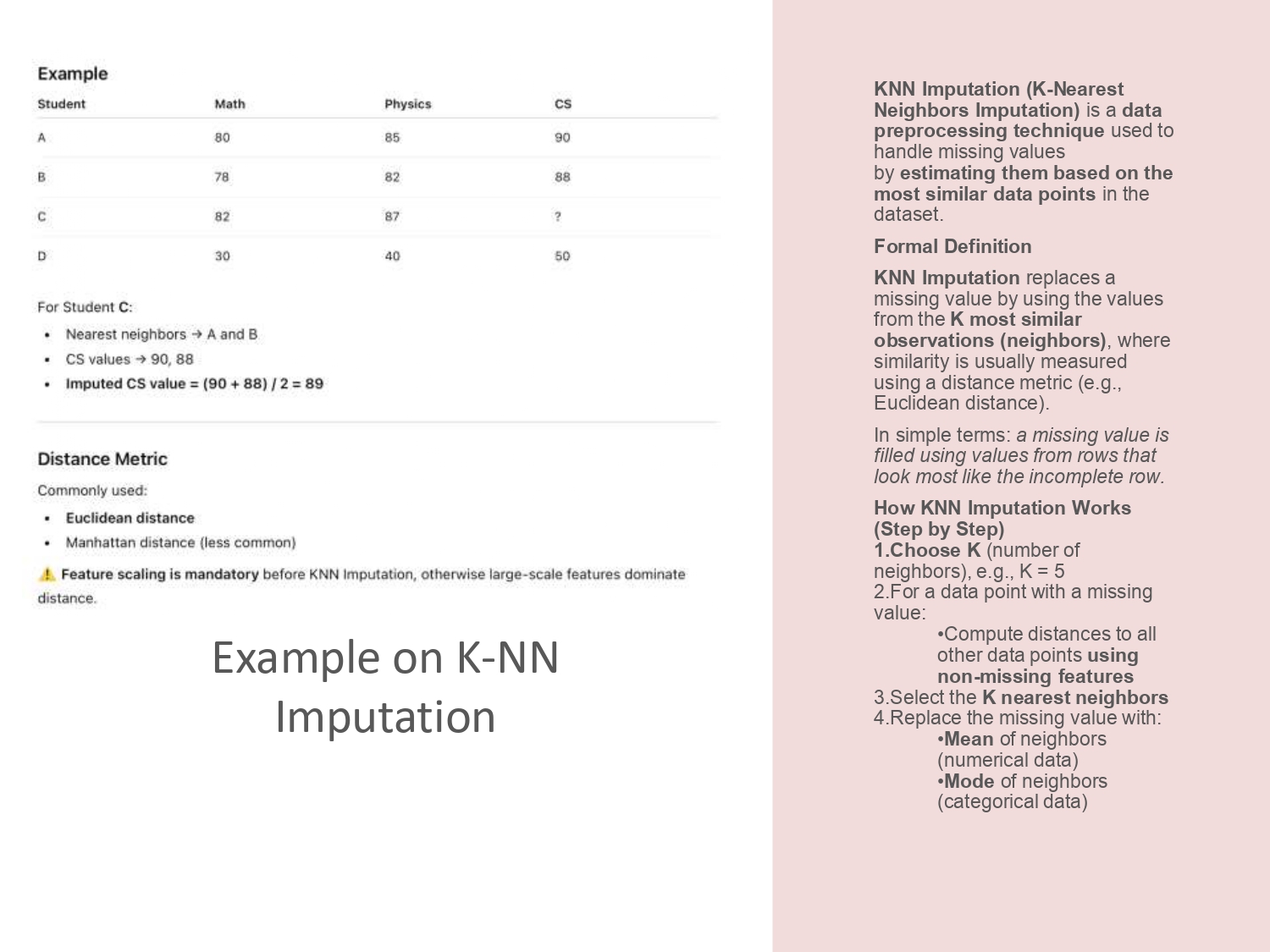
مثال عملي: كيف الـ KNN بيحل الأزمة؟ 🤝👬
تخيل عندنا الطالب (C) مش معروفة علامته بالـ CS، بس بنعرف علاماته بالماث والفيزياء.
خطوات الحل ببساطة:
- بنحدد عدد الجيران K (مثلاً K=2)، يعني بدنا نشوف أقرب طالبين للشب C.
- بنحسب المسافة (Distance) بين C وباقي الطلاب بناءً على المادتين المعروفات.
- بطلع معنا إن (A و B) هم الأقرب اله (جيرانه).
- بناخذ علاماتهم بالـ CS وبنطلع المتوسط: (90 + 88) / 2 = 89.
- هيك عبينا الفراغ بـ 89 بناءً على "صحابه" الشاطرين بالموالين.
⚠️ تنبيه هام: لازم تعمل Feature
Scaling قبل ما تستخدم KNN، وإلا الميزة اللي أرقامها كبيرة رح تسحب الحسابات
لعندها وتخرب المسافة!

القيم الشاذة (Outliers) 🪐🚀
الـ Outliers هي داتا "شاطحة" بعيد جداً عن أغلبية الناس في
الداتا ست.
ليش لازم "نصيدهم" ونعالجهم؟
- بأثروا بقوة على المتوسط (Mean) وبخلوه مضلل.
- بشوشوا القواعد اللي بحاول الموديل يتعلمها فبتقل دقته.
- مرات بكونوا "غلطة" (زي راتب 50000 بدل 500)، ومرات بكونوا "فرصة" (زي كشف عملية نصب).
كيف بنكشفهم؟
- بطرق إحصائية زي Z-score أو الـ IQR (مربع الربيعات).
- بالرسم البياني زي الـ Box plots والـ Scatter plots، بطلعوا كنقطة بعيدة عن "العجقة".

كيف نتعامل مع (Outliers)؟ 🤠 Lasso
بعد ما كشفناهم، لازم نقرر شو نعمل فيهم. عندنا 4 استراتيجيات أساسية:
1. Removal (الحذف): بنحذفهم بس إذا كنا متأكدين إنهم "غلطة"
(Data Entry Error).
2. Capping (Winsorization): بدل ما نحذف القيمة، بنخليها "على
الحفة"، يعني أي شي فوق الـ 95% بنثبته عند قيمة الـ 95%. (زي اللي بضرب "بريك" عند حد معين).
3. Transformation: بنغير شكل الداتا (زي الـ Log) عشان نلم القيم
البعيدة ونقربها من المركز.
4. Robust Models: بنستخدم موديلات "عندها مناعة" ضد القيم الشاذة
وما بتأثر فيها كثير، زي الـ Random Forest.
⚠️ قاعدة ذهبية: إياك تحذف Outlier بدون ما تفهم مصدره، ممكن يكون
هو أهم معلومة بالداتا!

تحويل الداتا (Data Transformation) 🧬🌀
هون إحنا بنطبق عمليات رياضية عشان نخلي الداتا "أسهل للهضم" بالنسبة للموديل.
ليش بنعمل هيك؟
- الموديلات بتحب التوزيع الطبيعي (Normal Distribution).
- بقلل الـ Skewness (لما تكون الداتا "مايلة" لجهة واحدة).
- بثبت التباين (Variance) عشان ما تضيع الدقة.
أشهر العمليات:
- Log Transformation: سحري في تقليل انحراف الداتا الضخمة (زي الرواتب).
- Square Root: بنستخدمه للداتا اللي بتعبر عن "عد" (Counts).
- Power Transform: زي طريقة Box-Cox اللي بتدور على أحسن تحويل رياضي ممكن.

تحويل النصوص لأرقام (Encoding) 🔡➡️🔢
الخوارزميات ما بتفهم يعني "سيارة" أو "بيت"، لازم نحول كل شي لأرقام.
أنواع الميزات النصية:
- Nominal: ما فيها ترتيب (زي اللون: أحمر، أخضر.. ما في لون "أكبر" من لون).
- Ordinal: فيها ترتيب واضح (زي المستوى الدراسي: بكالوريوس < ماستر < دكتوراه).
طرق التحويل الأساسية:
- Label Encoding
- One-Hot Encoding
- Ordinal Encoding
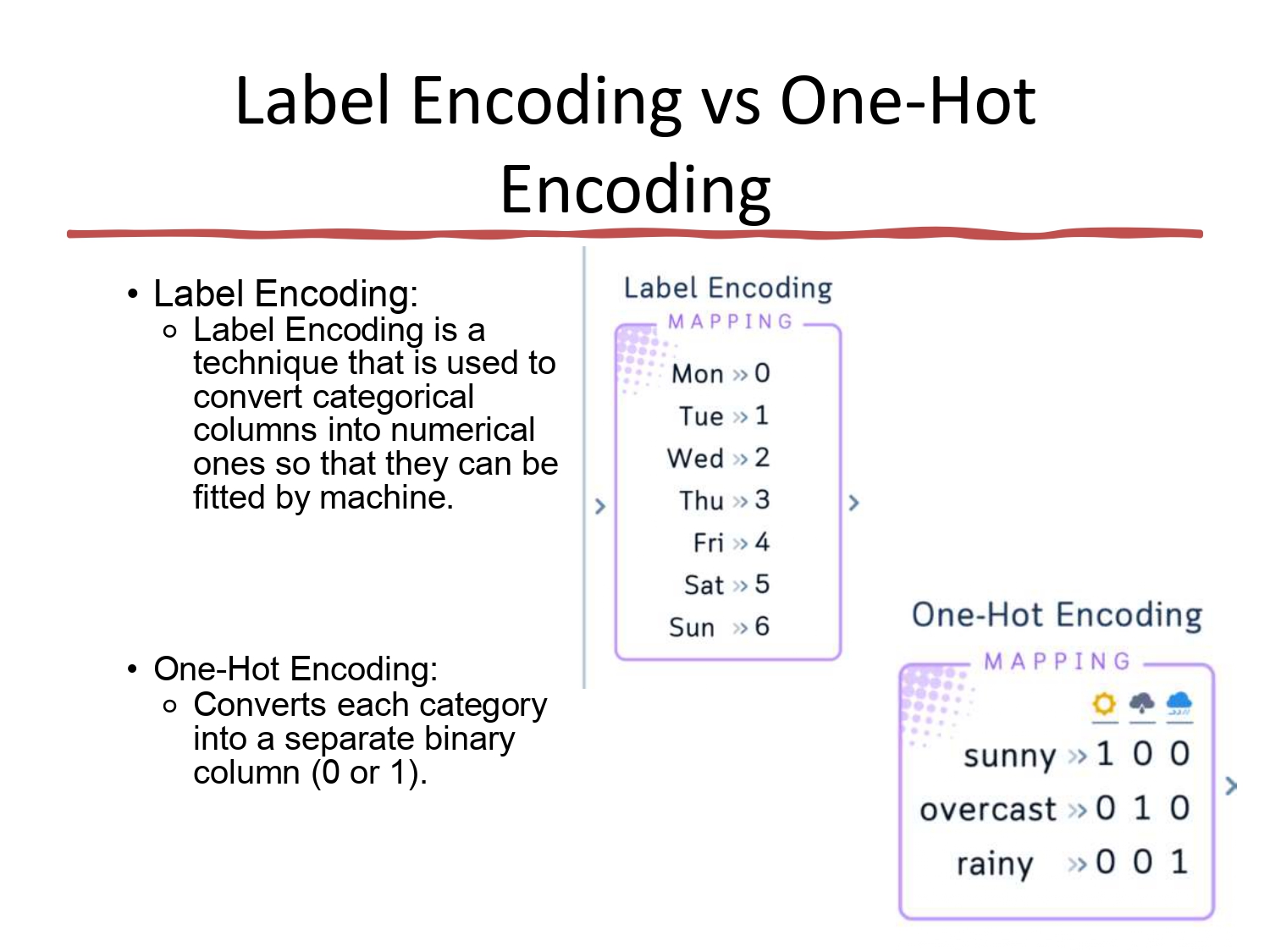
المواجهة الكبرى: Label vs One-Hot ⚔️
Label Encoding: بنعطي كل اسم رقم (0, 1, 2...).
مثلاً: الأيام (أحد=0، اثنين=1...).
⚠️ خطر: الموديل ممكن يفهم إن الاثنين (1) "أكبر" من الأحد (0)، وهذا غلط في ميزات زي "المدينة".
مثلاً: الأيام (أحد=0، اثنين=1...).
⚠️ خطر: الموديل ممكن يفهم إن الاثنين (1) "أكبر" من الأحد (0)، وهذا غلط في ميزات زي "المدينة".
One-Hot Encoding: بنعمل عمود جديد لكل قيمة، وبنحط (1) عند
القيمة الصحيحة و (0) عند الباقي.
مثلاً: الطقس بصير (مشمس [1,0,0]، غائم [0,1,0]...).
✅ ميزة: هيك الموديل ما بيفترض وجود ترتيب وهمي.
مثلاً: الطقس بصير (مشمس [1,0,0]، غائم [0,1,0]...).
✅ ميزة: هيك الموديل ما بيفترض وجود ترتيب وهمي.

أمثلة تطبيقية: شو أختار؟ 🤔💡
عشان نثبت المعلومة، شوف هاي الأمثلة:
الجنس (Male, Female): بنستخدم Label
Encoding (0 أو 1) لأنها بس قيمتين.
المدينة (عمان، إربد، الزرقاء): بنستخدم One-Hot Encoding عشان ما نحسس الموديل إن عمان "أحسن" من إربد
حسابياً.
المستوى التعليمي: بنستخدم Ordinal
Encoding (توجيهي=1، بكالوريوس=2...) عشان نحافظ على "رتبة" الترتيب لأنها مهمة هون.

توحيد المقاييس (Feature Scaling) 📏⚖️
تخيل عندك "العمر" (بين 0-100) و "الراتب" (بين 500-5000). الموديل رح ينعجق ويفكر إن الراتب أهم بمية
مرة بس لأن أرقامه أكبر!
ليش الـ Scaling ضروري؟
- Distance models (زي KNN): حساب المسافة بين النقط رح يعتمد عالراتب وينسى العمر تماماً.
- Gradient Descent: الموديل بوصل للحل أسرع بكثير لما تكون كل القيم في نفس المدى.
- بيمنع سيطرة الميزات اللي أرقامها كبيرة على الميزات اللي أرقامها صغيرة.

أهم 3 طرق للتوحيد 🛠️📊
عشان نوحد المقاييس، عنا 3 مدارس أساسية:
1. Min-Max Scaling (Normalization):
بنخلي كل القيم تنحصر بين (0 و 1).
صيغتها: (X - X_min) / (X_max - X_min).
ممتازة للـ Neural Networks بس بتتأثر بالقيم الشاذة.
صيغتها: (X - X_min) / (X_max - X_min).
ممتازة للـ Neural Networks بس بتتأثر بالقيم الشاذة.
2. Standardization (Z-score):
بنخلي المتوسط (Mean) 0، والتباين 1.
صيغتها: (X - mean) / std.
الأكثر استخداماً وبتنفع مع معظم الخوارزميات.
صيغتها: (X - mean) / std.
الأكثر استخداماً وبتنفع مع معظم الخوارزميات.
3. Robust Scaling:
هاي الطريقة هي "البطلة" لما يكون عنا Outliers كثيرة.
بتعتمد على الـ Median والـ IQR بدل المتوسط، فعشان هيك ما بتتأثر .
بتعتمد على الـ Median والـ IQR بدل المتوسط، فعشان هيك ما بتتأثر .

زبدة الموضوع: متى أختار شو؟ 🥣🆚
Normalization:
استخدمها لما ما يكون عندك Outliers، ولما بدك الداتا تكون محصورة
بدقة بين 0 و 1 (مفيدة جداً بالـ Neural Networks).
Standardization:
هي "الخيار الآمن". بنستخدمها لما يكون فيه شوية Outliers،
وللخوارزميات زي SVM و Linear
Regression لأنها بتفترض داتا متوزعة حول الصفر.
✅ نصيحة: إذا مش عارف شو تختار، ابدأ بالـ Standardization، غالباً رح تعطيك نتائج ممتازة.
اختصار الداتا (Data Reduction) 📉📦
لو عندك داتا عملاقة بزيادة، مش دائماً كثرتها "هيبة". الهدف هون نصغر حجم الداتا بدون ما نفقد جوهرها.
ليش نختصر؟
- Dimensionality Reduction: كثرة الميزات (Features) بتخلي الموديل يوقع بالـ Overfitting (يحفظ مش يفهم).
- بقلل الوقت والجهد اللي بياخذه الكمبيوتر في الحسابات.
- بيخلي الموديل أسهل في الفهم والتفسير.
كيف بنعمل هيك؟
- Feature Selection: نختار بس أهم الميزات.
- PCA: ندمج الميزات مع بعض بطريقة ذكية.
- Sampling: ناخذ عينة ممثلة بدل ما ناخذ كل الداتا.

اختيار الميزات (Feature Selection) 💎🔍
كل معلومة بالداتا "إلها وزنها". لازم نختار بس اللي بيفيدنا في التوقع.
طرق الاختيار:
✅ النتيجة: موديل أسرع، أدق، وبعيد عن العجقة الزايدة.
- Filter Methods: بنستخدم إحصائيات (زي الـ Correlation) عشان نشوف مين أقوى ميزة بتأثر عالهدف.
- Wrapper Methods: بنجرب الموديل على مجموعات مختلفة من الميزات ونشوف أنو وحدة بتعطي أعلى دقة.
- Embedded Methods: الموديل نفسه وهو بيتدرب "بينقي" أحسن الميزات (زي الـ Lasso و الـ Decision Trees).

تقسيم الداتا (Train-Test Split) 🍰🔪
أكبر غلط إنك تمتحن الموديل بنفس الداتا اللي درسته عليها (هيك بكون "بصيم"). لازم نقسم الداتا لجزئين:
1. Training Set: الجزء الأكبر (غالباً 70% أو 80%)، بنستخدمه
عشان الموديل يتعلم القواعد.
2. Testing Set: الجزء البرا (20% أو 30%)، بنستخدمه عشان نمتحن
الموديل ونشوف كيف رح يتصرف مع داتا "عمره ما شافها".
⚖️ النسب المشهورة: (80/20) أو (70/30) هي الرائدة في هذا المجال عشان
نضمن تقييم عادل.

تسريب الداتا (Data Leakage) 🚿⚠️
هاض هو "السم القاتل" لأي موديل. بصير لما الموديل يشوف معلومات من الـ Test
set وهو لسا في مرحلة الـ Training.
ليش بخوف؟
بخلي الموديل يعطيك "دقة وهمية" عالية جداً، بس لما تجربه بالواقع بيفشل فشل ذريع.
أسبابه وطرق الوقاية:
- Preprocessing Leakage: إنك تعمل Scaling للداتا كاملة قبل
ما تقسمها.
✅ الحل: اقسم أولاً، بعدين طبّق الـ Preprocessing على جزء التدريب فقط. - استخدام ميزات بتعتمد عالمستقبل اللي الموديل المفروض يتوقعه.

أدوات الحرب (Tools) 🛠️💻
طيب كل هالحكي وين بنطبقه؟ عندنا عمالقة في البرمجة بيسهلوا علينا كل شي:
- Python (Pandas & NumPy): الملوك في تنظيف وترتيب الجداول والعمليات الرياضية.
- Scikit-learn: المكتبة اللي فيها كل خوارزميات الـ Preprocessing جاهزة.
- SQL: ضروري جداً لسحب الداتا وتنظيفها من قواعد البيانات مباشرة.
- Spark/Airflow: للداتا الضخمة بزيادة واللي بتحتاج "مواسير" (Pipelines) معقدة.
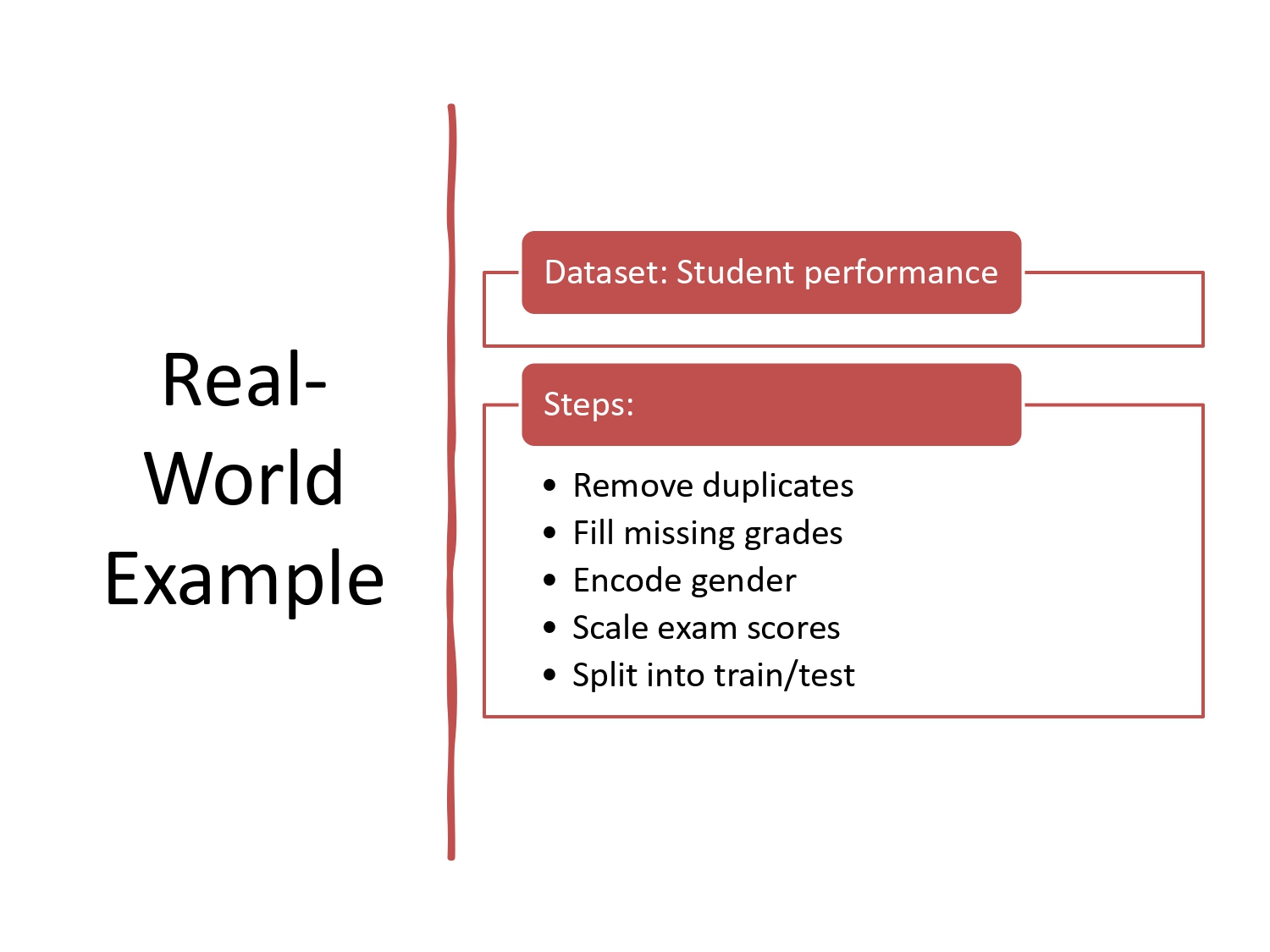
مثال واقعي: أداء الطلاب 🎓📊
لو بدنا نتوقع أداء الطلاب في الامتحان، هيك رح يمشي شغلنا:
- Remove duplicates: نحذف إذا نفس الطالب تسجل مرتين.
- Fill missing grades: إذا فيه علامة ناقصة، بنعبيها بالمتوسط مثلاً.
- Encode gender: نحول (ذكر/أنثى) لـ (0/1).
- Scale exam scores: نوحد علامات المواد (مثلاً علامة من 100 وعلامة من 20).
- Split data: بنقسمهم 80% دراسة و 20% امتحان للموديل.

أخطاء القاتلة 🚫💀
تجنب هاي الأشياء عشان ما يضيع تعبك:
- تجاهل الداتا الناقصة: لا تفترض إنها مش مهمة، فراغ واحد ممكن يخرب موديل كامل.
- المبالغة بحذف الـ Outliers: مش كل قيمة بعيدة غلط، ممكن تكون هي "الكنز" اللي بيكشف حالات الاحتيال.
- الـ Encoding الغلط: تستخدم Label Encoding لميزة ما فيها ترتيب (زي أنواع السيارات).
- Data Leakage: نسيان تقسيم الداتا قبل البدء بالمعالجة.
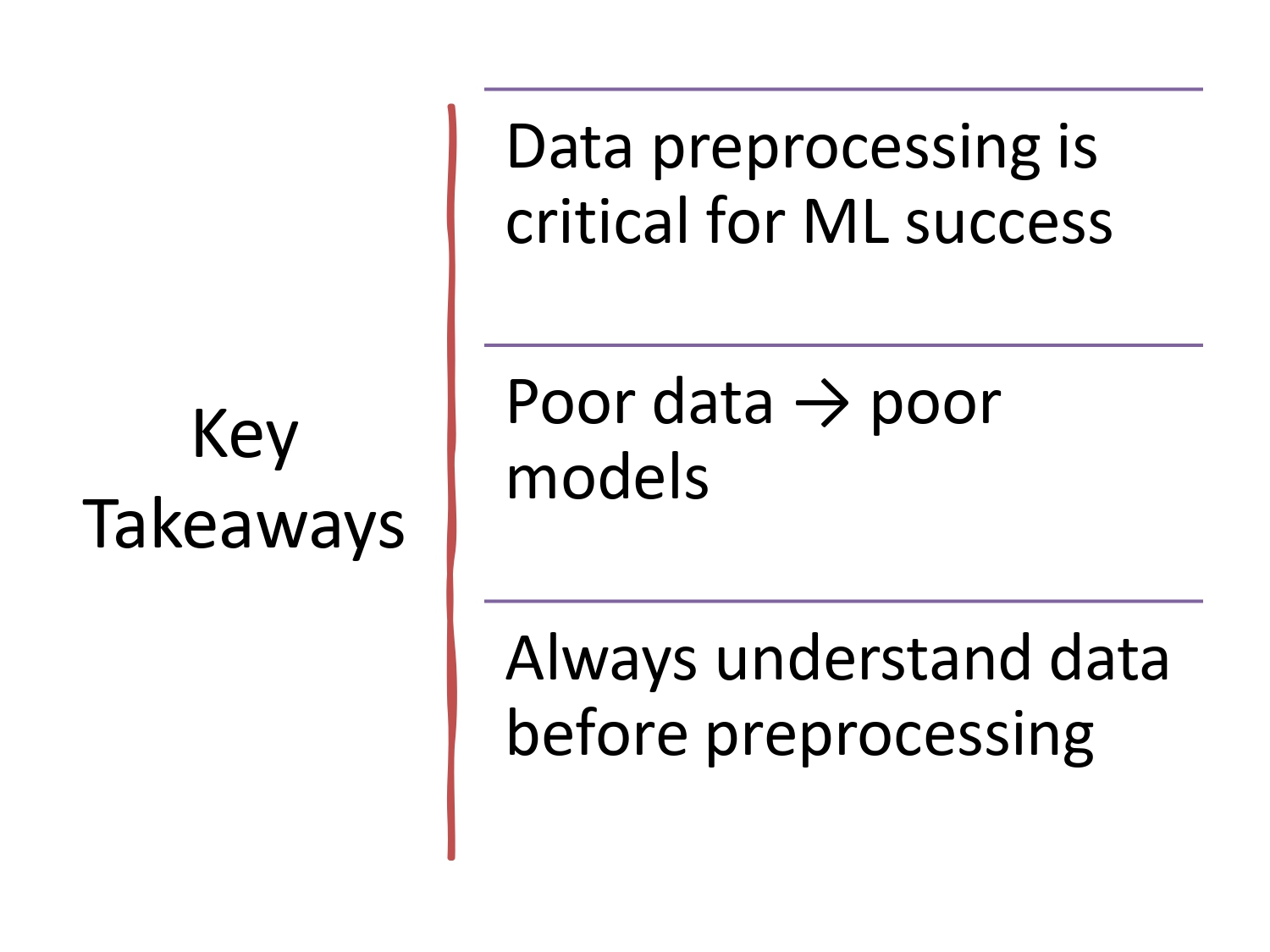
الخلاصة (زبدة الشابتر) 🍯📝
- Data Preprocessing هو حجر الأساس لأي مشروع ذكاء اصطناعي ناجح.
- داتا تعبانة = موديل تعبان (Garbage In, Garbage Out).
- لازم تفهم الداتا وتشوفها بعينك قبل ما تبلش تطبق عليها أي خوارزمية.