


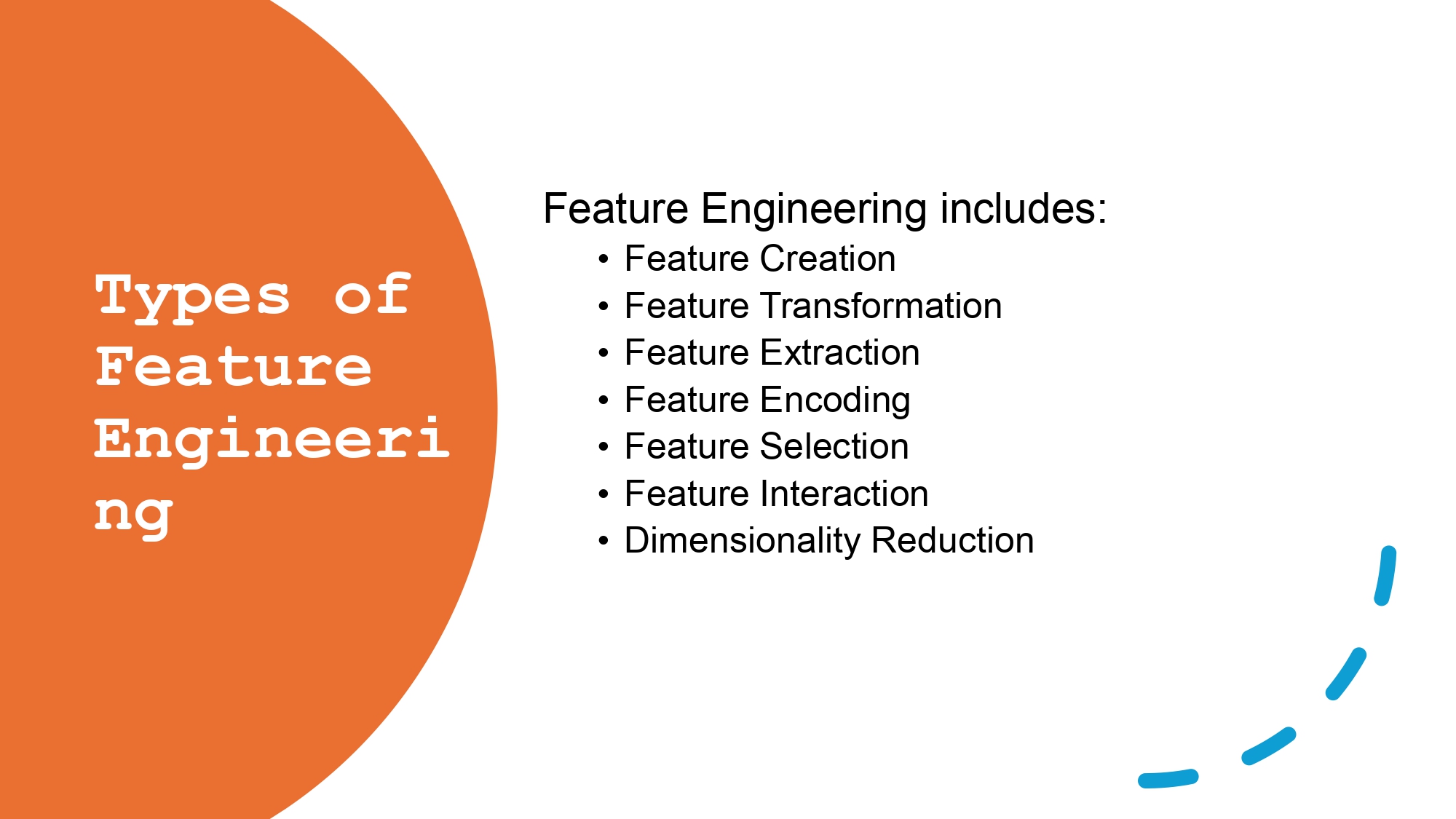

مثلاً: العمر = السنة الحالية - سنة الميلاد. أو BMI = الوزن / مربع الطول.
df["age"] = df["current_year"] - df["birth_year"]
df["total_price"] = df["quantity"] * df["unit_price"]

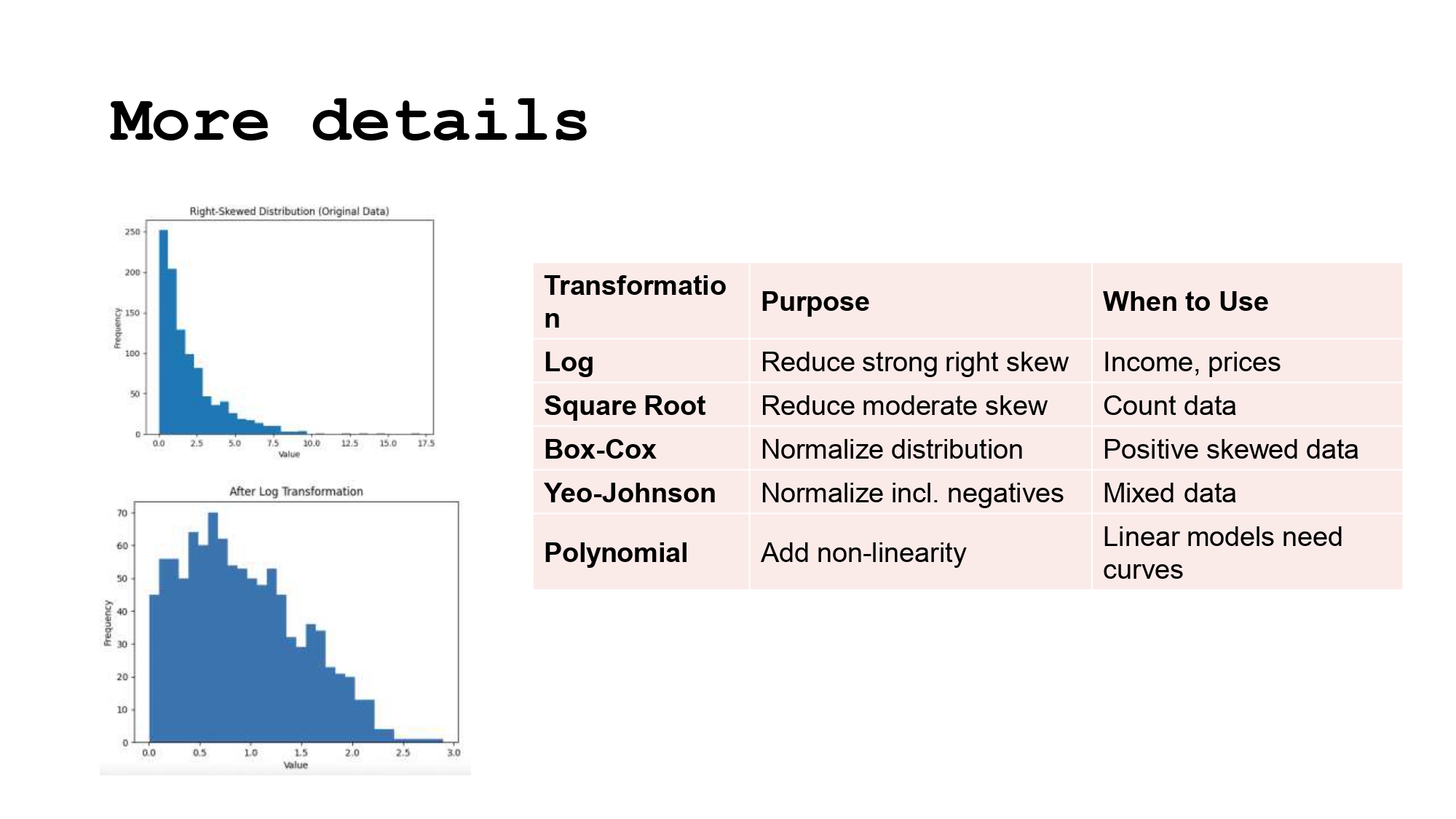
- Log Transformation: للداتا اللي فيها شحطة قوية لليمين (زي الرواتب).
- Square Root: للداتا المتوسطة الشحطة.
df["salary_log"] = np.log(df["salary"])

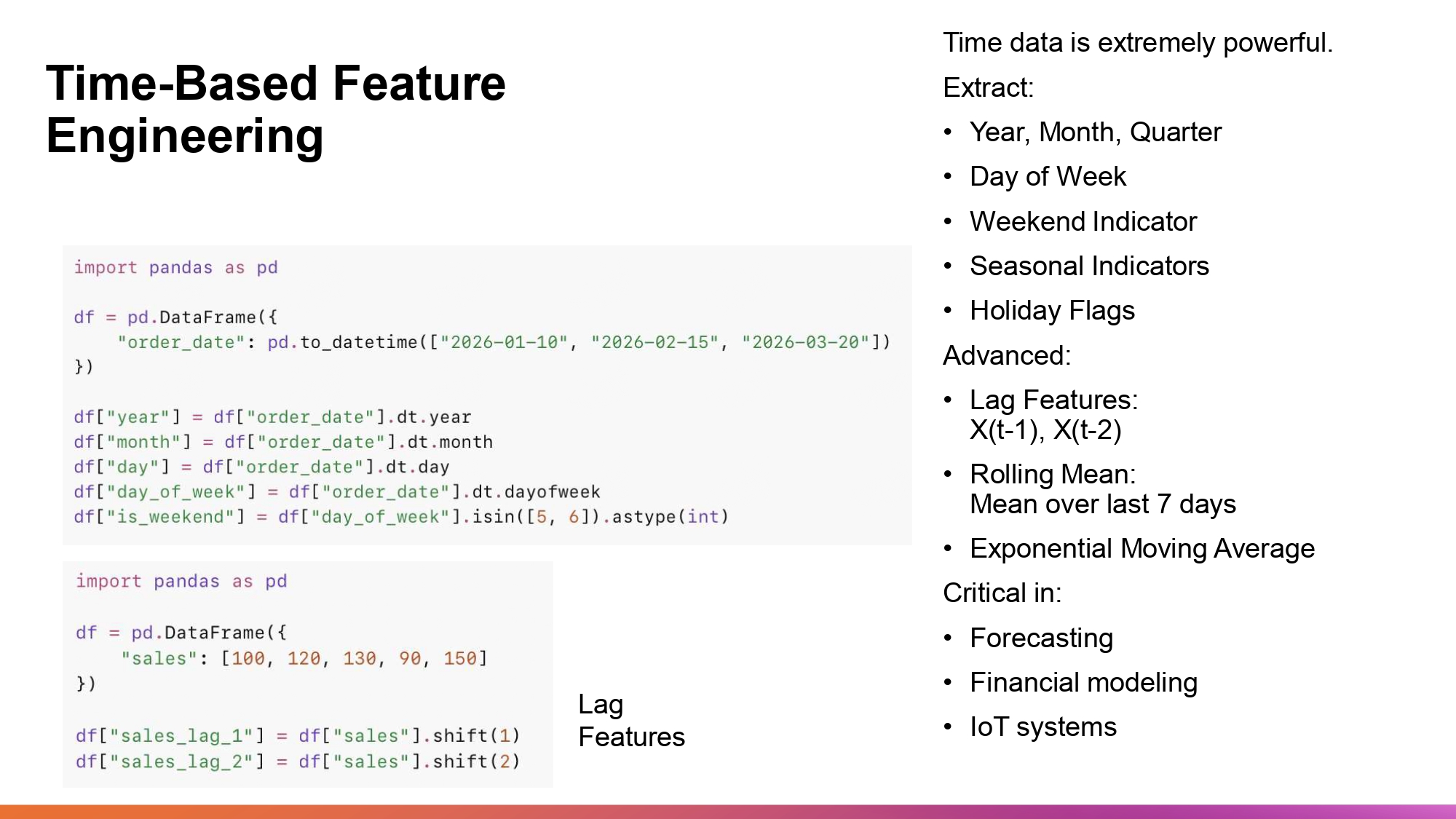
مهم جداً في Forecasting والأنظمة المالية.

هاض الإشي بساعد الموديلات البسيطة (زي الخطي) إنها تفهم علاقات معقدة وغير خطية.
df["income_edu"] = df["income"] * df["education_years"]


* ملاحظة: الموديلات الشجرية (Random Forest) ما بفرق معها السكيلنج.

Filter Methods
بنشوف الارتباط (Correlation) بين المتغيرات والهدف. سريعة ومفيدة بالبداية.
Wrapper Methods
بنجرب الموديل على مجموعات مختلفة من المتغيرات وبنشوف مين أحسن (زي RFE). دقيقة بس بدها وقت.
Embedded Methods
الموديل نفسه وهو بيتدرب بقرر مين المهم (زي Lasso أو Tree Importance).

عشان هيك الـ Feature Engineering هو المنقذ من هاي اللعنة.

الداتا ساينست "البروفيسور" هو اللي بقعد مع أهل الخبرة بالمجال عشان يفهم شو لازم يستخرج.


الحل؟ دائماً اعمل Split للداتا وبعدين اعمل FE على الـ Train فقط!

Data Understanding
افهم الداتا والبزنس صح قبل ما تلمس الكود. قعدة مع أهل الخبرة بتوفر عليك تعب أيام.
Data Preprocessing
نظف الداتا، عالج القيم المفقودة، وظبط الـ Outliers. هاي مرحلة "تجهيز الأرضية".
Train-Test Split
افصل داتا الاختبار (Test) وحطها في "خزنة". هاي أهم خطوة عشان تمنع الغش (Leakage).
Feature Engineering (train only)
هون الشغل الثقيل (Encoding, Scaling). لازم تتعلم هاض الإشي بس من داتا التدريب وتطبقه عمياني عالباقي.
Feature Selection
مش كل إشي طلعته مفيد. نقي أحسن الميزات اللي بتعطي "أثر" حقيقي للموديل وشيل الـ Noise.
Model Training
هسا الموديل ببلش يتعلم من الأنماط اللي جهزناها بكل الخطوات اللي قبل.
Cross-Validation
امتحن الموديل امتحان تجريبي متكرر عشان تتأكد إنه "فهمان" مش بس "باصم" داتا التدريب.
Final Evaluation
آخر خطوة: بنطلع الداتا اللي بالخزنة (Test) وبنشوف الموديل كيف بشتغل على داتا حقيقية عمره ما شافها.



# إعداد خطة المعالجة للمتغيرات الرقمية
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# إعداد خطة المعالجة للمتغيرات الكلامية
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# دمج العمليات في محول واحد
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# بناء الموديل النهائي
model = Pipeline(steps=[
('preprocessor', preprocessor),
('regressor', LinearRegression())
])
هيك بتضمن إن كل الـ FE والـ Scaling بصير "صح" ومعموله Clean code.

- ✔ هي عملية تكرارية (Iterative).
- ✔ تعتمد 100% على فهمك للمجال (Domain-driven).
- ✔ الموديلات العظيمة بتنبني على ميزات عظيمة، مش بس خوارزميات معقدة.