تخيل حالك قاعد بمحل قهوة، وصاحب المحل بده يعرف ليش الناس بتطلب "سبانش لاتيه" الصبح أكثر من
"الأمريكانو".. هو هون عنده بيانات (طلبات الزبائن)، بس مش عارف شو يعمل
فيها.
زمان كان الموضوع يعتمد على "الحدس" أو الخبرة.. بس اليوم، كمية البيانات اللي بنشرها بالعالم صارت مهولة
جداً. الـ Data Science هو السحر اللي بمسك هاي البيانات "الفوضوية" وبحولها
لـ معلومات ذهبية بتساعدنا نتخذ قرارات صح.
ليش داتا سينس؟ وكيف بلشت الحكاية؟

أهلاً بك في عالم البيانات !
شوف هاي الصورة اللي بالسلايد، بتلخص لك "الفوضى" اللي بتعيشها لما تبلش رحلتك.. من الـ Cleaning Data والتخلص من الـ Nulls،
لغاية ما توصل للـ Analysis Time وتطلع بالنتائج.

شو ناويين ندرس؟
ركز معي بالنقاط هون:
- End-to-End Lifecycle: يعني رح نتعلم القصة من "طقطق للسلام عليكم"، من فهم المشكلة لغاية ما نشغل الموديل.
- Preprocessing & Feature Engineering: هاذ "مطبخ" البيانات، هون بننظف وبنجهز المقادير الصح.
- Data Driven Storytelling: وهذا أهم إشي؛ إنك تحكي "قصة" من ورا الأرقام، مش بس ترمي جداول وجرافات!
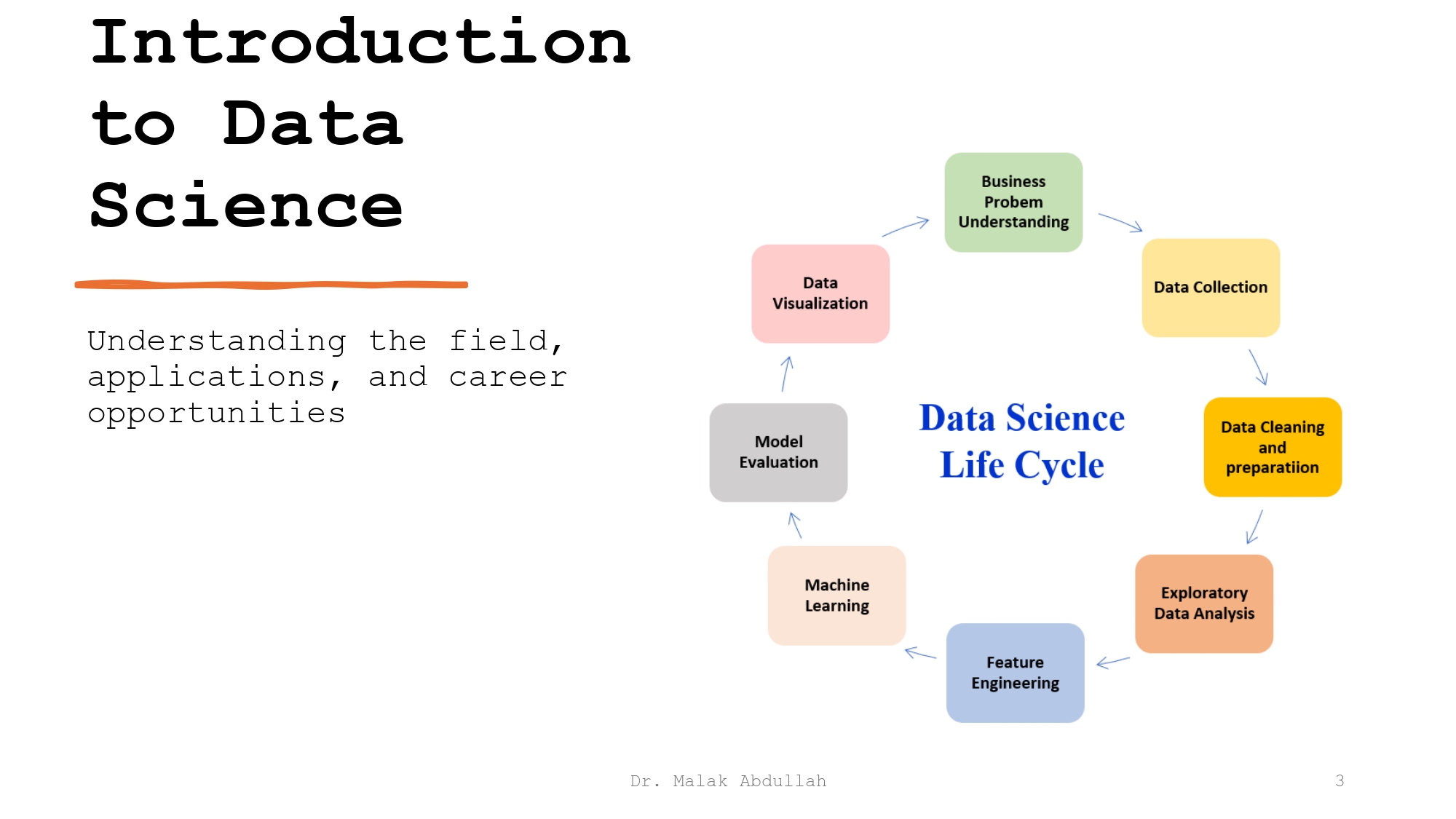
الدائرة السحرية (Life Cycle) بالتفصيل:
1. Business Problem Understanding:
أهم خطوة! هون بنقعد مع صاحب الشغل ونفهم شو المشكلة اللي بتوجعه.. هل بده يزيد مبيعات؟ ولا بده
يعرف ليش الزبائن بيتركوه؟ بدون فهم المشكلة، كل الشغل بكون عالفاضي.
2. Data Collection:
مرحلة "اللم".. هون بنجمع البيانات من كل مكان؛ من قواعد بيانات الشركة، من النت، أو حتى من ملفات
اكسل قديمة.
3. Data Cleaning and Preparation:
بتاخذ 80% من وقتنا! هون بنشيل البيانات الغلط، وبنرتب الداتا عشان تكون جاهزة للتحليل. زي اللي
بنقي العدس قبل ما يطبخه!
4. Exploratory Data Analysis (EDA):
مرحلة الاستكشاف.. بنرسم جرافات وبنشوف العلاقات بين المتغيرات. هون بنبلش نلمح "القصة" اللي
مخبيتها الأرقام.
5. Feature Engineering:
هون "الفن".. بنبتكر متغيرات جديدة من البيانات الموجودة عنا عشان نساعد الموديل يفهم أحسن (مثلاً:
نحسب العمر من تاريخ الميلاد).
6. Machine Learning:
هون "المختبر".. بنختار الخوارزمية الصح، وبندربها على البيانات عشان تتعلم وتصير تقدر تتوقع
المستقبل.
7. Model Evaluation:
بدنا نتأكد من شغلنا.. بنختبر الموديل ببيانات جديدة عشان نعرف كم نسبة الدقة وهل فعلاً بحل
المشكلة؟
8. Data Visualization:
النهاية السعيدة.. بنحول كل هاي التعقيدات لصور وجرافات سهلة ومفهومة للمدراء، عشان يتخذوا القرار
الصح.

الخلاصة.. شو هو هالعلم؟
هو مجال "عابر للقارات" (Interdisciplinary) هدفه استخراج "الرؤى" (Insights) من قلب الداتا.
بيعتمد على 3 أعمدة أساسية (شوف الرموز بالسلايد):
بيعتمد على 3 أعمدة أساسية (شوف الرموز بالسلايد):
- 📉 Statistics: عشان نفهم التوزيع والاحتمالات.
- 🤖 Machine Learning: عشان نخلي الكمبيوتر "يتحزر" بذكاء.
- 🧠 Domain Expertise: تكون فاهم بالمجال اللي بتطبق فيه (طب، بنوك، تسويق).

الـ Pipeline (الماسورة الذكية):
الـ Pipeline هو "خط الإنتاج" اللي بيمشي فيه الشغل.. هو نظام مرتب
ومؤتمت (Automated) ببلش بجمع البيانات وبنتهي بموديلات جاهزة للتشغيل.
ليش مهم؟ عشان يضمن لنا 3 شغلات :
ليش مهم؟ عشان يضمن لنا 3 شغلات :
- ✅ Data Quality: دايماً نضمن نظافة الداتا.
- ✅ Reproducibility: إذا رجعت شغلت الخط كمان مرة، تطلع نفس النتائج.
- ✅ Scalability: يقدر يتحمل بيانات ضخمة بدون ما ينهار!

المكونات الأساسية للعبة:
هاي هي "العدة" اللي لازم تكون معك دايماً:
- Data Collection: كيف تلم الداتا صح.
- Data Wrangling: تنظيف "المصايب" الموجودة بالبيانات.
- EDA: تحليل استكشافي عشان تفهم شو القصة.
- Feature Engineering: تجهيز "الميزات" القوية للموديل.
- Model Building: بناء وتدريب الموديل الذكي.
- Deployment: تشغيل الموديل في العالم الحقيقي وتفسير نتايجه.

ليش وجع الراس هاض كله؟ ليش علم البيانات مهم؟
شوف يغالي، الموضوع مش بس كود وأرقام، الموضوع هو "قوة":
⚖️ Helps in decision-making:
بدل ما المدير يقرر "بناءً على إحساسه"، بقرر بناءً على حقائق.
الأرقام ما بتكذب!
🧠 Automates tasks:
ليش نخلي موظف يسوي شغلة مكررة؟ بنخلي الـ AI يسويها عنه بلمح البصر
وبدقة أعلى.
📈 Improves efficiency:
بنفهم الزبون شو بده بالظبط، وبنحسن تجربته، وبنقلل الهدر بالوقت والمصادر.
💰 Generates business value:
بالآخر، الشركات بدها تزيد أرباحها. علم البيانات هو اللي بكشف "فرص ذهبية" ما حدا شايفها غير
الموديل.

ليش لازم يكون عنا "Pipeline" مرتب؟ (النصف الأول)
a) Efficiency:
أتمتة العمليات بتوفر وقت وجهد خرافي. بدل ما تقعد إنت تنظف الداتا بإيدك كل يوم، الخطوة هاي بتصير
تلقائية.
b) Consistency:
الخطوات ثابتة، والنتائج دايماً موثوقة. مش اليوم يطلع معك شكل وبكرة شكل!
c) Reproducibility:
هاذ حجر الأساس بالعلم. لو أي حدا ثاني أخذ نفس الداتا والبايب لاين تبعك، لازم يطلع معه نفس نتيجتك
بالظبط.
d) Scalability:
لو صار عندك بدل مليون سجل، مليار سجل.. البايب لاين الصح بتحمل الضغط وما بنفجر بوجهك! 🚀

تكملة فوائد البايب لاين.. ركز هون!
e) Error Reduction:
البشر بغلطوا، بس الكود (إذا انكتب صح) ما بغلط. الأتمتة بتقلل فرص الأخطاء اليدوية "البايخة".
f) Flexibility:
الدنيا بتتغير، وبدك تغير مصدر البيانات؟ عادي، بتعدل جزء صغير بالبايب لاين بدون ما تهدم كل اللي
بنيته.
g) Resource Optimization:
البايب لاين بيعرف كيف يستغل "قوة الكمبيوتر" صح بالسحب والتدريب، خصوصاً بالـ Hyperparameter tuning.
h) Effective Collaboration:
لما التيم كله يشتغل على نفس البايب لاين، بصير الكل فاهم شو بصير، وبقدروا يطوروا على شغل بعض
بسهولة.

مراحل الشغل (الجد بلش هون)
هون السلايد بقلك إنه البايب لاين بيتكون من عدة مراحل محورية، وكل مرحلة لها دورها "البطولي" في تحويل
الداتا الخام لذهب.
ملاحظة: الـ Architecture ممكن يختلف من مشروع لثاني، بس المراحل اللي رح نشوفها بالسلايدات الجاية هي "أبجدية" علم البيانات اللي ما بحيد عنها حدا.
ملاحظة: الـ Architecture ممكن يختلف من مشروع لثاني، بس المراحل اللي رح نشوفها بالسلايدات الجاية هي "أبجدية" علم البيانات اللي ما بحيد عنها حدا.

مراحل البايب لاين (الجزء الأول):
هون بنبلش بالتفاصيل المهمة جداً:
a) Data Collection:
البداية من جمع البيانات.. ممكن نستخدم Kaggle أو نسحب من APIs. المهم نجمع "المواد الخام" صح.
b) Data Preprocessing:
شغل "المطبخ".. بنعالج القيم المفقودة (Missing data) وبنعمل Normalization للداتا.
c) Data Exploration (EDA):
مرحلة "السونار".. بنفهم العلاقات بين الأرقام ونطلع رؤى أولية قبل التدريب الثقيل.
d) Feature Engineering:
صناعة "الميزات".. بنختار أنسب المتغيرات اللي بتخلي الموديل تبعنا أذكى ما يمكن.

مراحل البايب لاين (الجزء الثاني):
بنكمل المراحل باتجاه "التشغيل" الفعلي:
f) Model Optimization:
تحسين الموديل.. بنلعب بالـ Hyperparameters عشان نوصل لأعلى دقة
ممكنة.
g) Model Deployment:
تجهيز الموديل "للواقع".. بنشغله في بيئة العمل الحقيقية وبنبدأ نراقبه.
h) Automation & Orchestration:
"المايسترو".. بنخلي كل العمليات المكررة تمشي لحالها وبسهولة وبدون تدخل يدوي دائم.
i) Tools & Frameworks:
اختيار "العدة".. بنستخدم المكتبات اللي بتناسب مشروعنا (زي بايثون، سكاي ليرن، إلخ).

اللمسات النهائية (الجودة):
عشان شغلك يكون "بروفيشنال" وما يضيع عالفاضي:
j) Best practices & Documentation:
التوثيق هو "كاتالوج" شغلك.. لازم توثق كل خطوة عشان غيرك يعرف شو سويت وكيف يكمل.
k) Testing & Validation:
الاختبار الصارم.. لازم نتأكد إن الموديل دايماً بيعطي نتائج صحيحة وموثوقة.
l) Scalability & Performance:
القدرة على النمو.. لازم البايب لاين يتحمل ضغط البيانات الكبيرة ويتطور معها.

وين بنشوف علم البيانات في حياتنا؟
التطبيقات الحقيقية بتسمع فيها كل يوم:
- 🏥 Healthcare: توقع الأمراض وتشخيصها بدقة وصناعة دواء مخصص.
- 💰 Finance: كشف الاحتيال المالي وتقييم مخاطر القروض بالبنوك.
- 🎯 Marketing: تقسيم الزبائن وفهم شو بدهم قبل ما يطلبوا هم!
- 🛒 E-commerce: اقتراح المنتجات (زي نون وأمازون) وتوقع الطلب.

وين ممكن تشتغل بهذا المجال؟ 💼
عالم البيانات كبير، وفي كثير "تخصصات" ممكن تختارها حسب ميولك:
Data Scientist: "الكل في واحد".. بيحلل، بيبني موديلات، وبطلع
بحلول للمشاكل.
Data Analyst: "صائد الرؤى".. بيركز أكثر على تحليل الـ Historical data وطلع تقارير.
ML Engineer: "المهندس الميكانيكي للموديلات".. بيركز على هندسة
الموديلات وتطويرها بشكل تقني بحت.
Data Engineer: "السباك".. هو اللي بيبني المواسير والـ Pipelines اللي بتمشي فيها الداتا.

خارطة طريق أي مشروع ناجح 🗺️
عشان ما تضيع، لازم تمشي على Workflow واضح ببلش من جمع البيانات وبخلص
بالـ Deployment.
في السلايدات الجاية رح نفكك هاي المراحل السبعة وحدة وحدة بالتفصيل.

الخطوة 1: شو المشكلة أصلاً؟ 🤔
قبل ما تكتب ولا سطر كود، لازم تفهم "البزنس" شو بده.
Understand Business Problem: ليش أصلاً بدنا نعمل هذا المشروع؟
شو المشكلة اللي بنحلها؟
Success Metrics: كيف رح نعرف إننا نجحنا؟ لازم نحدد أرقام وأهداف
واضحة.

الخطوة 2: تجميع "العدة" (البيانات) 📥
هون بنبلش نجمع الداتا من كل مكان ممكن:
Sources: قواعد بيانات (SQL)،
APIs، أو حتى "قحط" بيانات من المواقع (Web
Scraping).
Tools: استخدام مكتبات فخمة زي Pandas و BeautifulSoup عشان نسحب
الداتا.
الخطوة 3: التنظيف والترتيب 🧹
أكثر خطوة بتاخد وقت (حوالي 80% من وقت المشروع!).
Cleaning: معالجة القيم الناقصة (Nulls)، شطب التكرار، وتعديل الأرقام الشاذة (Outliers).
Feature Scaling: توحيد مقاييس الداتا عشان الموديل ما يتخربط (زي
تحويل الطول من سم لمتر).

الخطوة 4: مرحلة الاستكشاف (EDA) 🔍
هون كأننا بنصور الداتا "أشعة".. بدنا نفهم خباياها:
Patterns & Correlations: شو المتغيرات اللي بتأثر على بعض؟ ومين
أهم شي بالداتا؟
Visualization: استخدام الرسومات البيانية عشان نوضّح الصورة
للعيون.
الخطوة 5: بناء الموديل 🤖
الآن بنعطي الداتا "للعقل الإلكتروني" عشان يقدر "يتعلم":
Selecting the Model: بنختار الخوارزمية المناسبة (تصنيف، تنبؤ
بأرقام، أو تجميع).
Training & Optimizing: بنبلش ندرب الموديل ونعدل فيه لغاية ما
يصير أداؤه ممتاز.

الخطوة 6: كيف أداء الموديل؟ 📈
مش بس إننا عملنا موديل خلصنا.. لازم نعرف هو قديش "شاطر":
Performance Metrics: بنقيس الدقة (Accuracy)، والـ Precision والـ Recall.
Hyperparameter Tuning: "تغيير عيارات" الموديل عشان نحصل على
أحسن نسخة منه.
الخطوة 7: الموديل صار جاهز للشغل 🚀
آخر خطوة هي إننا نطلع بالموديل للعلن:
Deployment: تشغيل الموديل باستخدام Flask أو FastAPI عشان الناس تستخدمه.
Monitoring: مراقبة أداء الموديل وتحديثه باستمرار لأنه الداتا
بتتغير مع الوقت.

شو لازم تتعلم عشان تكون "سفاح" بالمجال؟ 💪
الخلطة السحرية لـ Data Scientist ناجح هي:
- 🐍 Programming: بايثون بالدرجة الأولى، و SQL.
- 📊 Statistics: عشان تفهم الأرقام وتعرف إذا كانت النتائج "صدفة" ولا حقيقة.
- 🧠 ML & DL: قلب التخصص النابض.
- 🎨 Data Viz: القدرة على عرض النتائج بشكل "فنان".
- 🗣️ Communication: لأنك لازم تشرح نتائجك لناس مش تقنيين.
ملخص الرحلة كاملة 🔄
شايف الرسمة؟ هاي هي الدائرة اللي رح تلف فيها.. من العلم بالتحدي لغاية الوصول لحل مبني على بيانات
حقيقية وبدقة عالية. تذكر دايماً إنها رحلة مستمرة مش مجرد خط مستقيم.

شو اتعلمنا لغاية هسا؟ 📋
✅ علم البيانات هو تخصص بيجمع مجالات كثيرة والهدف منه حل المشاكل.
✅ لازم يكون عندك مهارات تقنية (برمجة) ومهارات تحليلية (إحصاء).
✅ في أكثر من وظيفة وشغل ممكن تدخل فيه بهذا المجال.

العدة والمكتبات: نظرة عامة 🛠️
هون مبلشين قسم جديد وجامد.. بدنا نحكي عن "الأسلحة" اللي رح نستخدمها في معركة البيانات.
مش بس إنك تعرف شو هي، المهم تعرف متى تستخدم كل وحدة فيها. السلايد هاذ هو "الفهرس" لكل الأدوات اللي
رح نمر عليها.

ليش بايثون بالذات؟ 🐍
بايثون هي "اللغة الأم" لعلم البيانات اليوم.
Most widely used: لأنها سهلة التعلم، وقريبة من لغة البشر، والكل
بستخدمها.
Rich ecosystem: عندها كمية مكتبات (Libraries) خرافية، شو ما خطر
ببالك بدك تعمل بالداتا، بتلاقي له "مكتبة" جاهزة بتساعدك.

شلة المكتبات الأساسية (القمة) �
شوف هاي "الخلطة" اللي ما بكمل أي مشروع بدونها:
- Pandas: هاي الكل بالكل للجداول والبيانات (DataFrames).
- NumPy: ملك الأرقام والمصفوفات الحسابية الثقيلة.
- Matplotlib & Seaborn: الفنانين اللي برسموا لنا الداتا ونشوفها بعيونا.
- Scikit-learn: المختبر اللي فيه كل خوارزميات الـ Machine Learning.
- TensorFlow & PyTorch: الوحوش بتوع الـ Deep Learning والذكاء الاصطناعي العميق.

لعبة الجداول مع Pandas 🐼
بانداس هي اللي بتخليك تتعامل مع الداتا كأنك شغال على "إكسل" بس بقوة برمجة جبارة:
DataFrames & Series: هي الهياكل الأساسية (زي الجداول والأعمدة).
Reading & Writing: بتقدر تقرأ من CSV، Excel، وحتى SQL بلمح
البصر.
Filtering & Transforming: قص، لزق، فلتر، وغير شكل الداتا زي ما
بدك.

الرياضيات السريعة مع NumPy 🔢
لما يكون عندك ملايين الأرقام، ما بينفع تستخدم "ليستات" بايثون العادية، لازمك NumPy:
- Arrays & Matrices: بتتعامل مع البيانات كمصفوفات منظمة جداً وسريعة.
- Vectorized operations: بتعمل عمليات حسابية على ملايين الأرقام مرة وحدة بدون ما تضيع وقت بالـ Loops.
- Random numbers: توليد أرقام عشوائية لإجراء التجارب.

حوّل الأرقام لصور فنية 📊
الداتا بدون رسم بتضيع.. هون الأدوات اللي بتخلينا نفهم شو بصير:
Matplotlib: هي الأساس، بتعمل منها كل أنواع الرسومات (Line, Bar,
Pie).
Seaborn: مبنية فوق ماتبلوتليب بس بتطلع رسومات "شيك" واحترافية
أكثر وبسهولة.
Plotly: لو بدك جرافات "تفاعلية" (Interactive) بتقدر تحرك الماوس
فوقها وتشوف تفاصيل.

مختبر تعلم الآلة: Scikit-learn 🤖
هاي هي المكتبة "المقدسة" لأي Data Scientist:
- Classification & Regression: فيها كل الموديلات الجاهزة للتصنيف والتنبؤ.
- Model selection & evaluation: بتساعدك تختار أحسن موديل وتقيس دقته.
- Preprocessing: فيها أدوات لتجهيز الداتا (نورمالايزيشن، تنظيف) قبل ما تدخل الموديل.

الذكاء العميق للبيانات المعقدة 🧠
لما الموضوع يوصل لصور، صوت، أو داتا ضخمة جداً، بنروح للـ Deep
Learning:
Neural networks: بناء شبكات عصبية بتحاكي دماغ الإنسان.
Transfer learning: استخدام موديلات "عبقرية" حدا غيرنا دربها،
وبنعدل عليها لتناسبنا (زي موديلات جوجل وفيسبوك).

خلاصة قسم الأدوات 🏁
تذكر دوماً:
- بايثون هي الأساس القوي.
- المكتبات اللي حكيناهم هم "صندوق العدة" تبعك.
- بدون "ممارسة" (Hands-on practice) كل هاذ بضل كلام نظري عالفاضي.. لازم تشمر عن إيديك وتبلش تكود!