تخيل حالك بتطلع على صورة شارع.. أنت مش بس شايف "سيارة" و "شجر" و "رصيف"، أنت قاعد بتشوف حدود كل إشي
بالظبط.
في الـ Semantic Segmentation، إحنا ما بنكتفي بوضع صندوق (Box) حول الصورة،
إحنا بنسأل كل بكسل: صاحبي، أنت لمين تابع؟
🎬 القصة: كيف الكمبيوتر بفهم "كل بكسل" لمين برجع؟
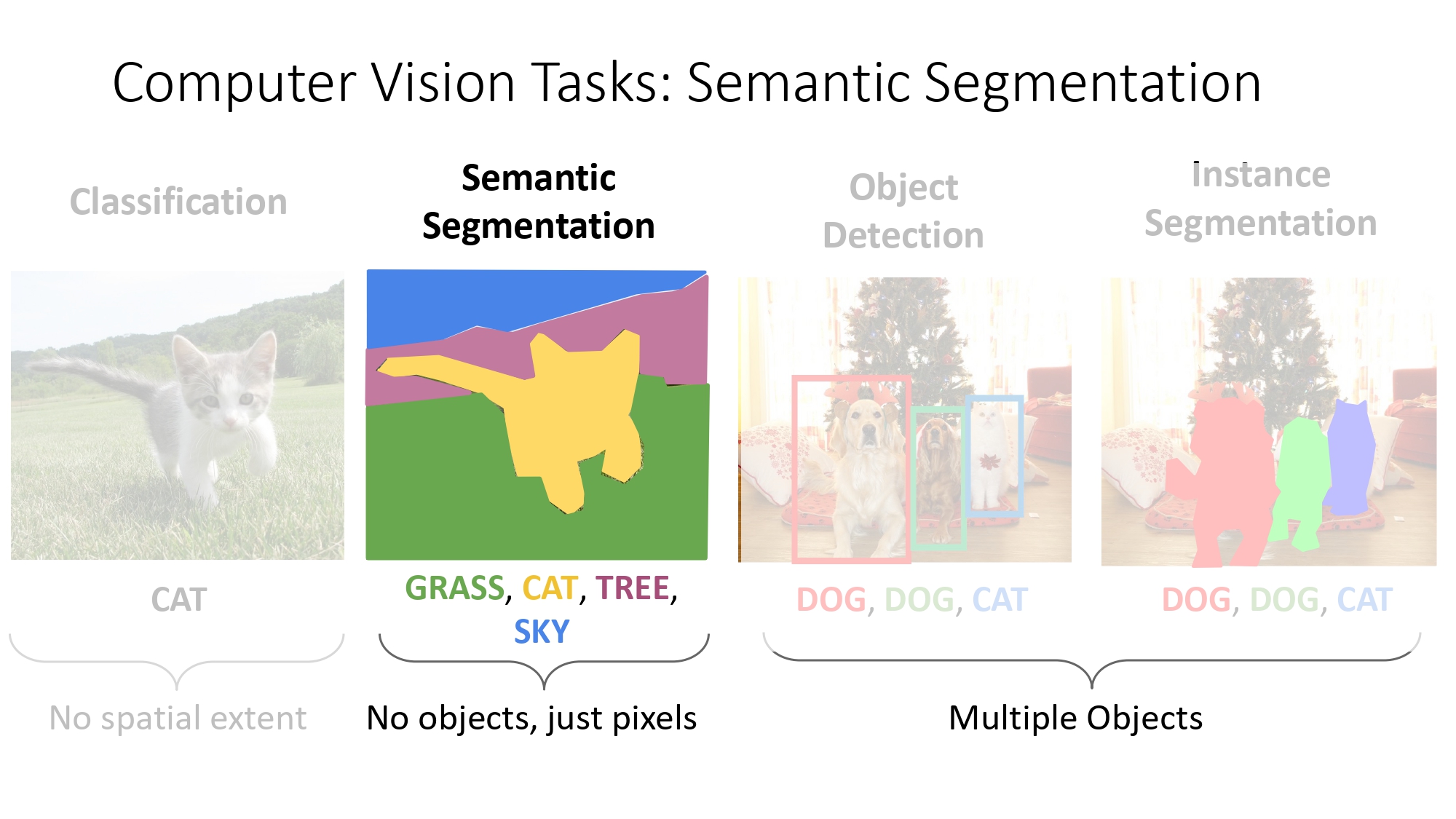
مقارنة بين مهام رؤية الحاسوب
عشان نفهم الـ Semantic Segmentation صح، لازم نشوف شو بفرق عن غيره:
- Classification: بس بحكيلك شو في بالصورة (مثلاً: "في بقرة").
- Semantic Segmentation: بلون كل بكسل حسب صنفه، بس ما بفرق بين بقرة وبقرة ثانية (كلهم بعتبرهم "بقر").
- Object Detection: برسم مربع حول كل بقرة وبميزهم عن بعض بـ Bounding Box.
- Instance Segmentation: هاض الأقوى؛ بلون كل بكسل وبميز كل "جسم" لحاله (بقرة رقم 1 غير عن بقرة رقم 2).

شو يعني تجزئة دلالية؟
ببساطة، إحنا بدنا نعطي تصنيف لكل بكسل في الصورة. المخرج تبعنا بكون
صورة بنفس حجم المدخل، بس كل بكسل فيها اله قيمة بتمثل الصنف تبعه (شجر، طريق، سماء، إلخ).
ملاحظة مهمة: إحنا ما بنهتم بـ "عدد" الأشياء، بنهتم بس بـ "نوع" المادة أو الجسم اللي بمثله البكسل.
ملاحظة مهمة: إحنا ما بنهتم بـ "عدد" الأشياء، بنهتم بس بـ "نوع" المادة أو الجسم اللي بمثله البكسل.
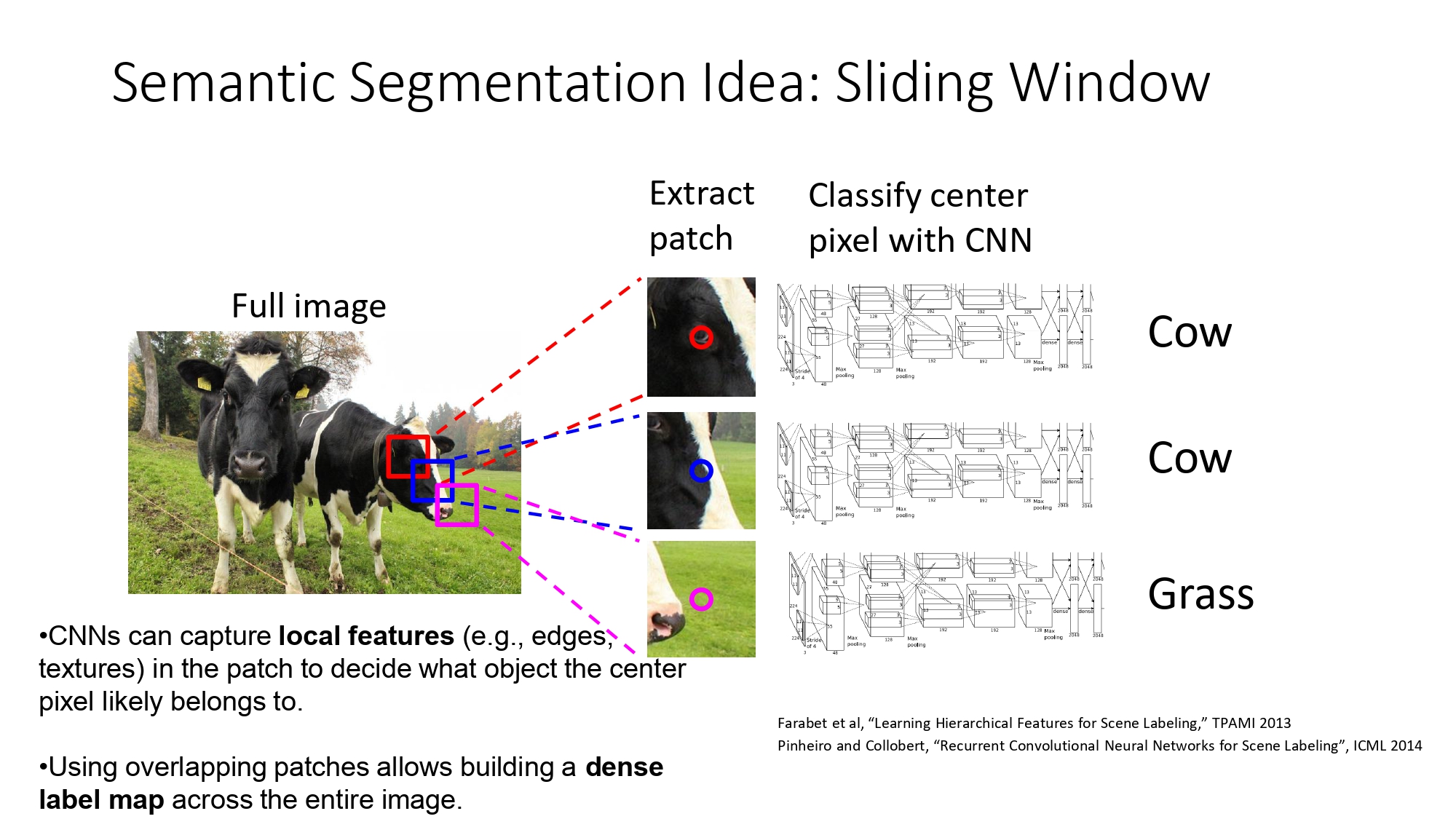
المحاولة الأولى: فكرة الـ Sliding Window
فكروا زمان إنهم يحلوا المشكلة بطريقة بدائية:
ليش هاي الطريقة فاشلة؟ لأنها بطيئة جداً! تخيل تقعد تعيد الـ Convolution لكل بكسل في الصورة.. الحسابات رح تكون هائلة وغير منطقية.
- بنمشي على الصورة مربع صغير (Patch) ورا الثاني.
- بندخل هاض المربع على شبكة تصنيف عادية عشان نعرف شو الصنف تبع "البكسل اللي بالنص".
ليش هاي الطريقة فاشلة؟ لأنها بطيئة جداً! تخيل تقعد تعيد الـ Convolution لكل بكسل في الصورة.. الحسابات رح تكون هائلة وغير منطقية.

الثورة: Fully Convolutional Networks (FCNs)
بدل ما نقصقص الصورة لمربعات صغيرة (Patches) ونتغلب ببطء الـ Sliding Window، إجا الحل العبقري: ليش ما نصمم شبكة كاملة من طبقات الـ Convolution بس؟
هيك بنقدر ندخل الصورة كاملة، ونطلع التوقعات لكل البكسلات بضربة وحدة (Forward Pass واحد). بس يا فرحة ما تمت، هاض المبدأ واجه مشكلتين جوهريات:
تذكر: معظم الشبكات القوية (زي ResNet) بتبلش بتصغير حجم الصورة بسرعة عشان تخفف الضغط الحسابي، هون إحنا لسا مش عارفين كيف نصغر ونرجع نكبر!
هيك بنقدر ندخل الصورة كاملة، ونطلع التوقعات لكل البكسلات بضربة وحدة (Forward Pass واحد). بس يا فرحة ما تمت، هاض المبدأ واجه مشكلتين جوهريات:
1. مشكلة الـ Receptive Field (مساحة الرؤية)
عشان البكسل الواحد في المخرج "يفهم" شو اللي حوله، لازم يكون "شايف" مساحة كافية من الصورة الأصلية. في الـ Conv العادي، هاي المساحة بتكبر ببطء شديد مع كل طبقة زيادة (المعادلة بتبين إنها $1+2L$). يعني عشان البكسل يشوف مساحة كبيرة، بدك عدد هائل من الطبقات!2. الحسابات مكلفة جداً (Expensive Computations)
لما تعمل Convolution على صورة بدقة عالية (High Res) وتضل تحافظ على نفس حجم الصورة طول الشبكة، الذاكرة والمعالج رح ينفجروا من كثر الحسابات.تذكر: معظم الشبكات القوية (زي ResNet) بتبلش بتصغير حجم الصورة بسرعة عشان تخفف الضغط الحسابي، هون إحنا لسا مش عارفين كيف نصغر ونرجع نكبر!
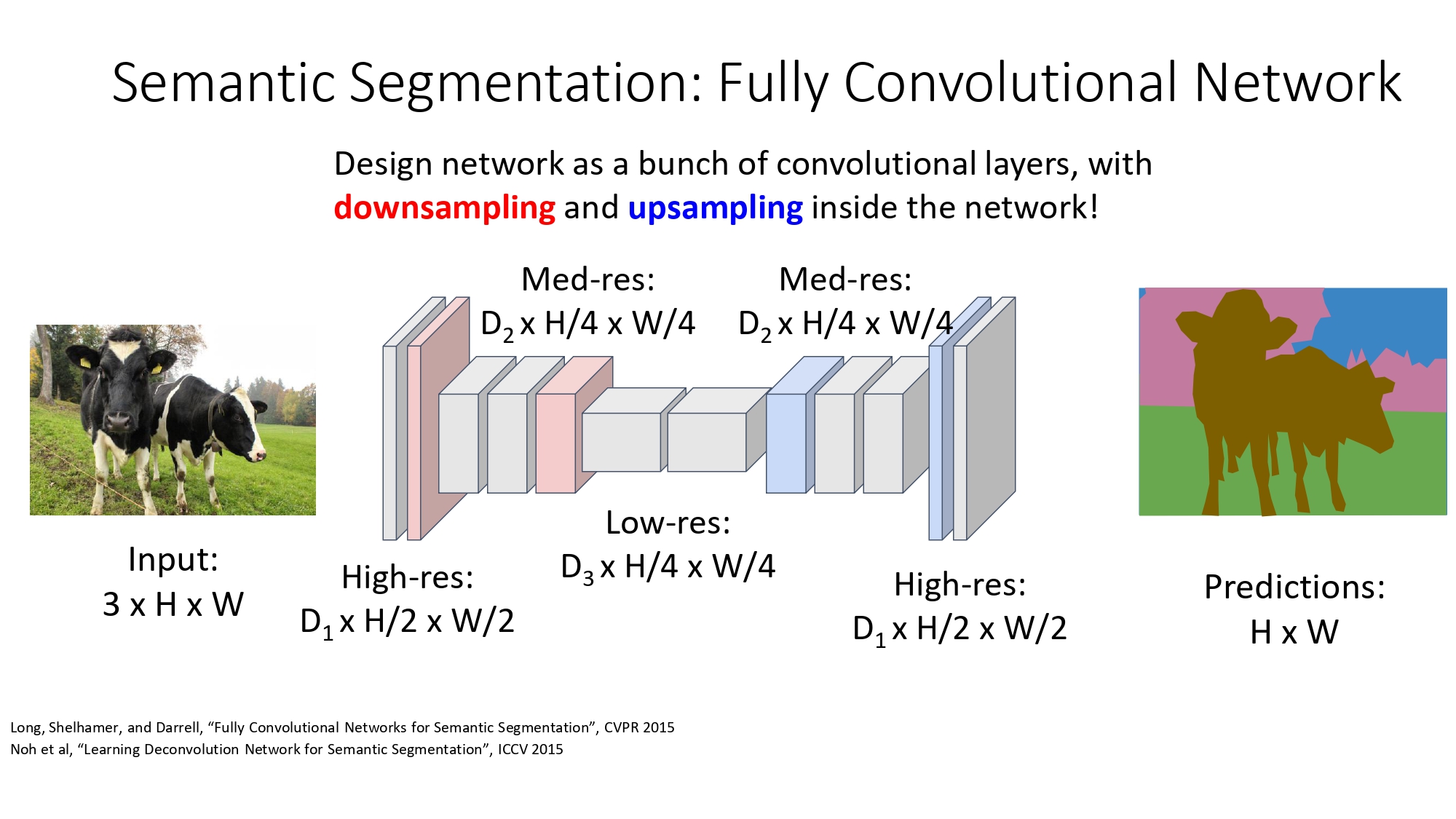
الفكرة: صغّر.. بعدين كبّر! (Upsampling)
عشان نحل مشكلة التكلفة، بنعمل إشي اسمه In-Network Upsampling:
السؤال هو: كيف بنكبر الصورة مرة ثانية؟
- بنصغر الصورة بالتدريج (عن طريق Stride Conv أو Pooling) عشان نقلل الحسابات.
- بنرجع نكبرها مرة ثانية في نهاية الشبكة عشان نطلع مخرج بنفس حجم المدخل.
السؤال هو: كيف بنكبر الصورة مرة ثانية؟
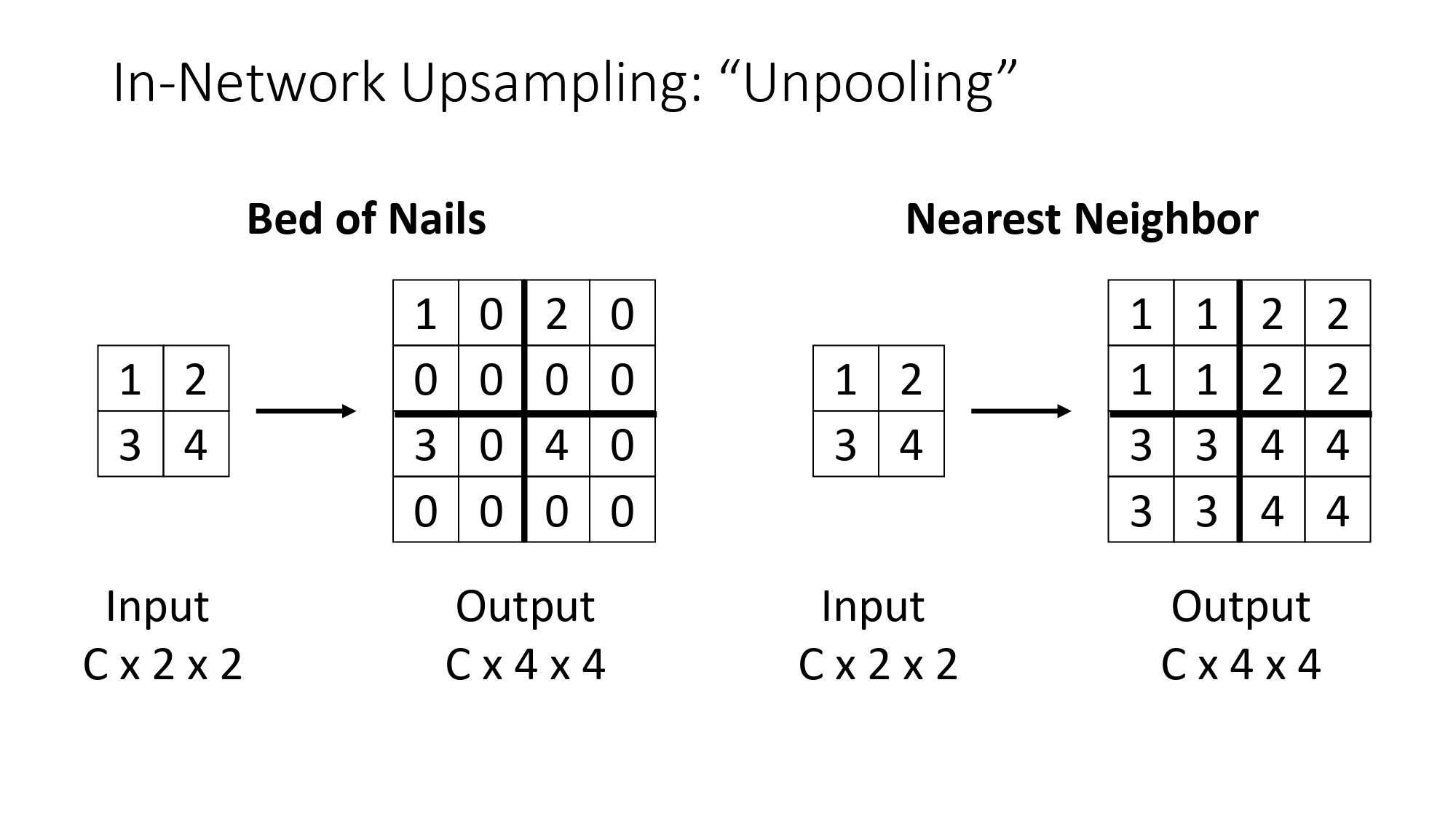
طرق التكبير: Bed of Nails & Nearest Neighbor
هاي أبسط الطرق عشان نرجع نكبر الـ Feature Map:
- Bed of Nails: بنحط قيمة البكسل في مكان واحد وبنخلي الباقي أصفار. تخيلها زي مسامير مثبتة في لوح، والباقي فاضي.
- Nearest Neighbor: بنكرر قيمة البكسل في كل الفراغات اللي حوله. يعني البكسل الواحد بصير مجموعة بكسلات بنفس القيمة.
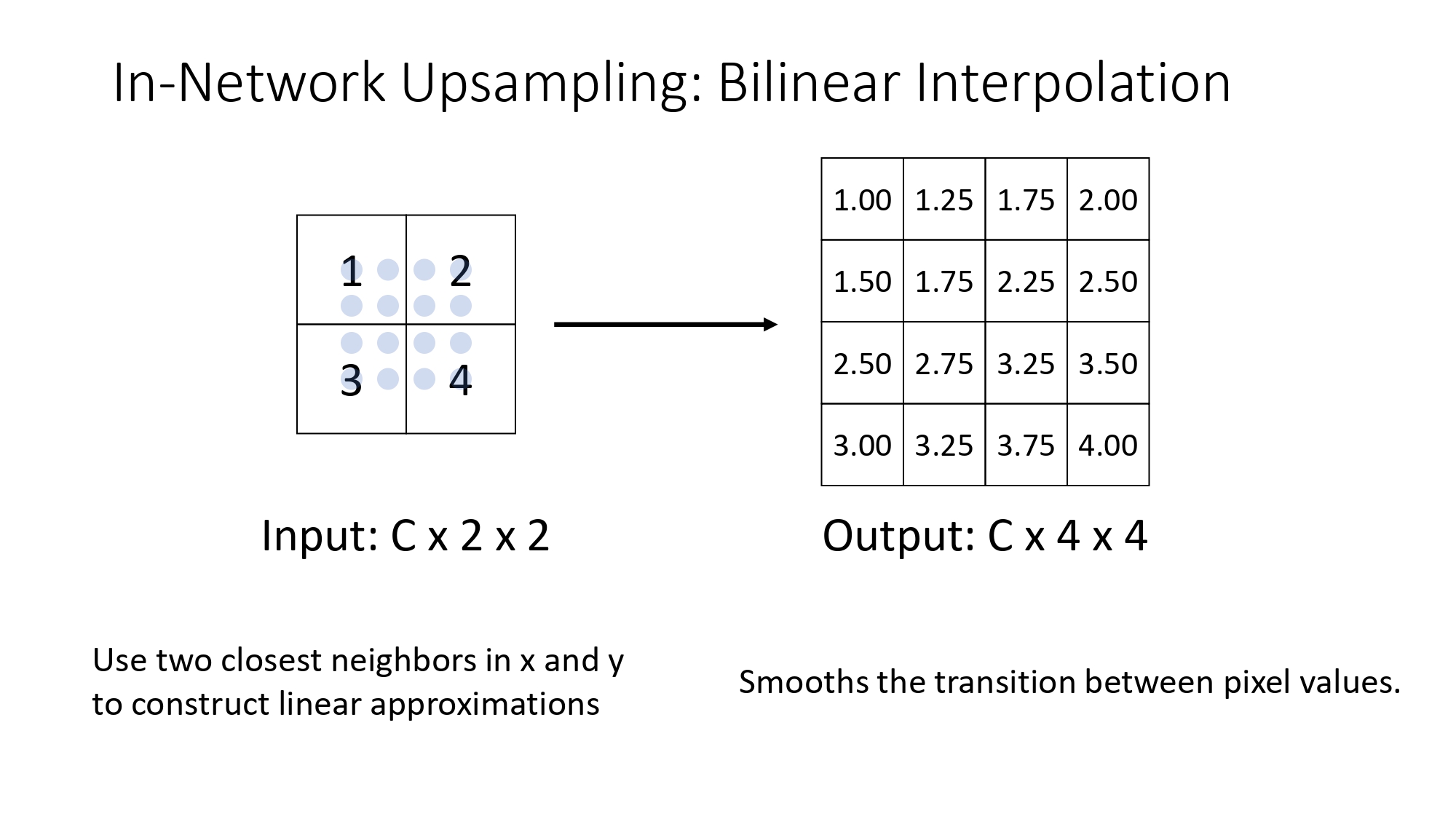
الطريقة الأنعم: Bilinear Interpolation
بدل ما نكرر نفس القيمة، بنستخدم أقرب جارين إلك (في محور $x$ ومحور
$y$) عشان نحسب قيم وسيطة بين البكسلات.
النتيجة: انتقالات ناعمة (Smooth Transitions) بين البكسلات، وبتبطل الصورة مبكسلة بشكل حاد. زي ما بتشوف بالمربع اللي على اليمين بالصورة، القيم بتتغير بالتدريج (1.25, 1.50, إلخ).
النتيجة: انتقالات ناعمة (Smooth Transitions) بين البكسلات، وبتبطل الصورة مبكسلة بشكل حاد. زي ما بتشوف بالمربع اللي على اليمين بالصورة، القيم بتتغير بالتدريج (1.25, 1.50, إلخ).
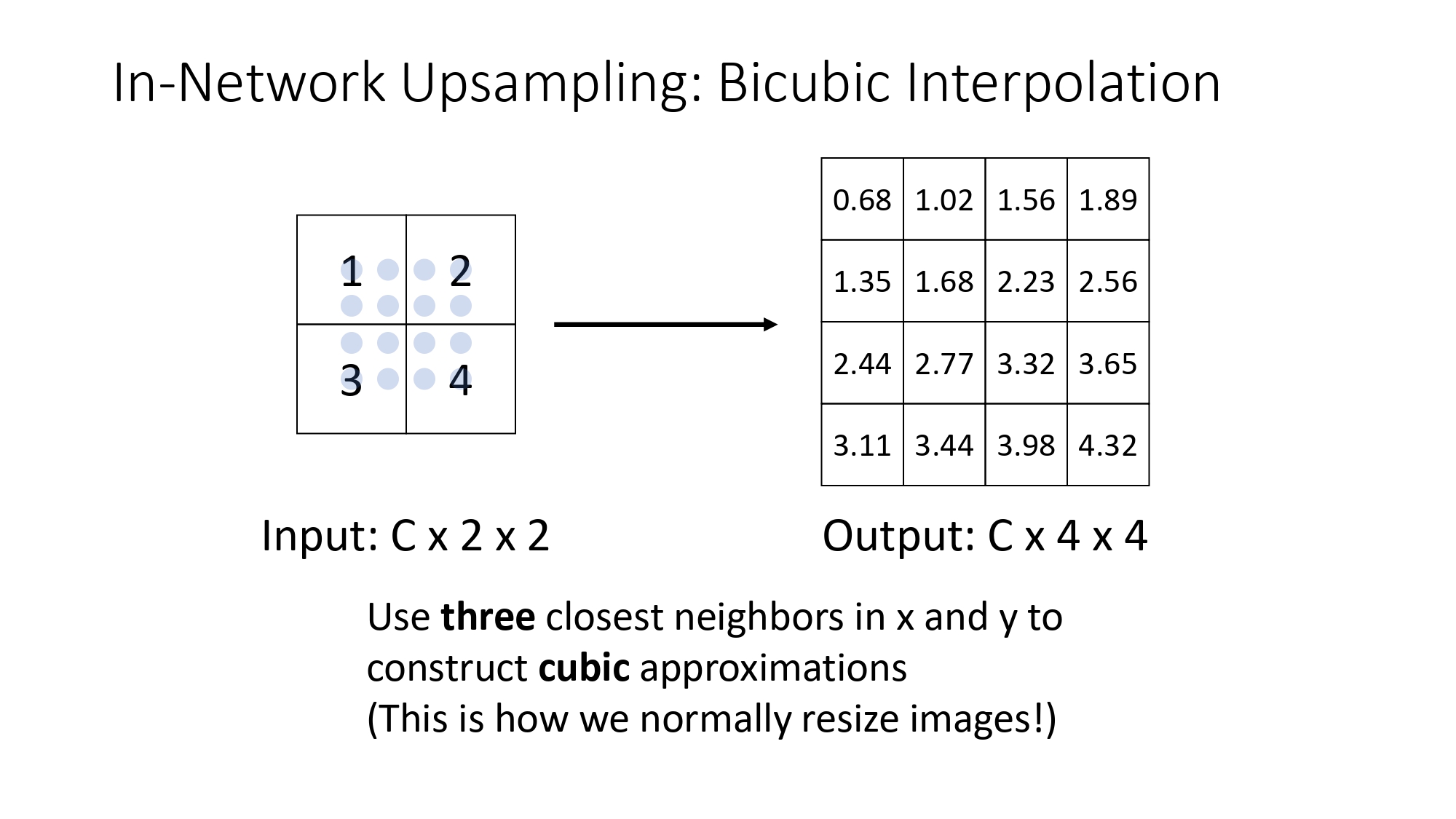
المستوى الأعلى: Bicubic Interpolation
هون بنرفع المستوى وبنستخدم أقرب 3 جيران لكل بكسل، وبدل المعادلة
الخطية البسيطة بنستخدم معادلة Cubic (تكعيبية).
من باب العلم: هاي هي الطريقة اللي بيستخدمها الكمبيوتر والمتصفح عندك بالوضع الطبيعي لما تيجي تعمل Resize لأي صورة. هي الأفضل من ناحية الجودة في الطرق "الثابتة".
من باب العلم: هاي هي الطريقة اللي بيستخدمها الكمبيوتر والمتصفح عندك بالوضع الطبيعي لما تيجي تعمل Resize لأي صورة. هي الأفضل من ناحية الجودة في الطرق "الثابتة".
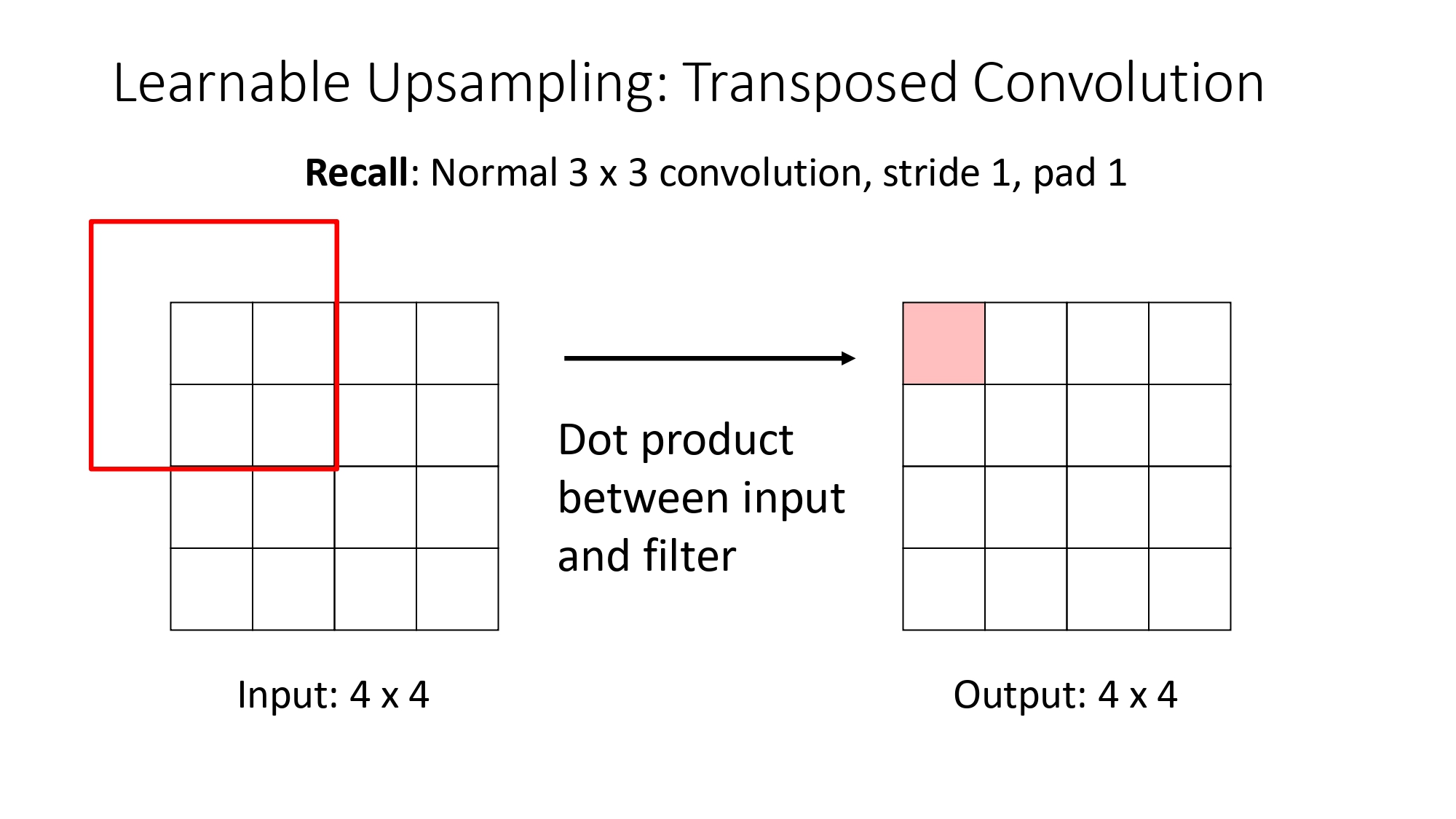
تذكير: كيف بشتغل الـ Convolution العادي؟
عشان نفهم الـ Transposed، لازم نتذكر العادي:
- إحنا بنمشي بـ فلتر (Kernel) فوق الصورة.
- بكل خطوة، بنعمل Dot Product بين الفلتر والجزء اللي تحته من الصورة عشان نطلع بكسل واحد في المخرج.
- إذا كان الـ Stride > 1، فإحنا قاعدين نختصر الحجم، وهاض بنسميه Learnable Downsampling.
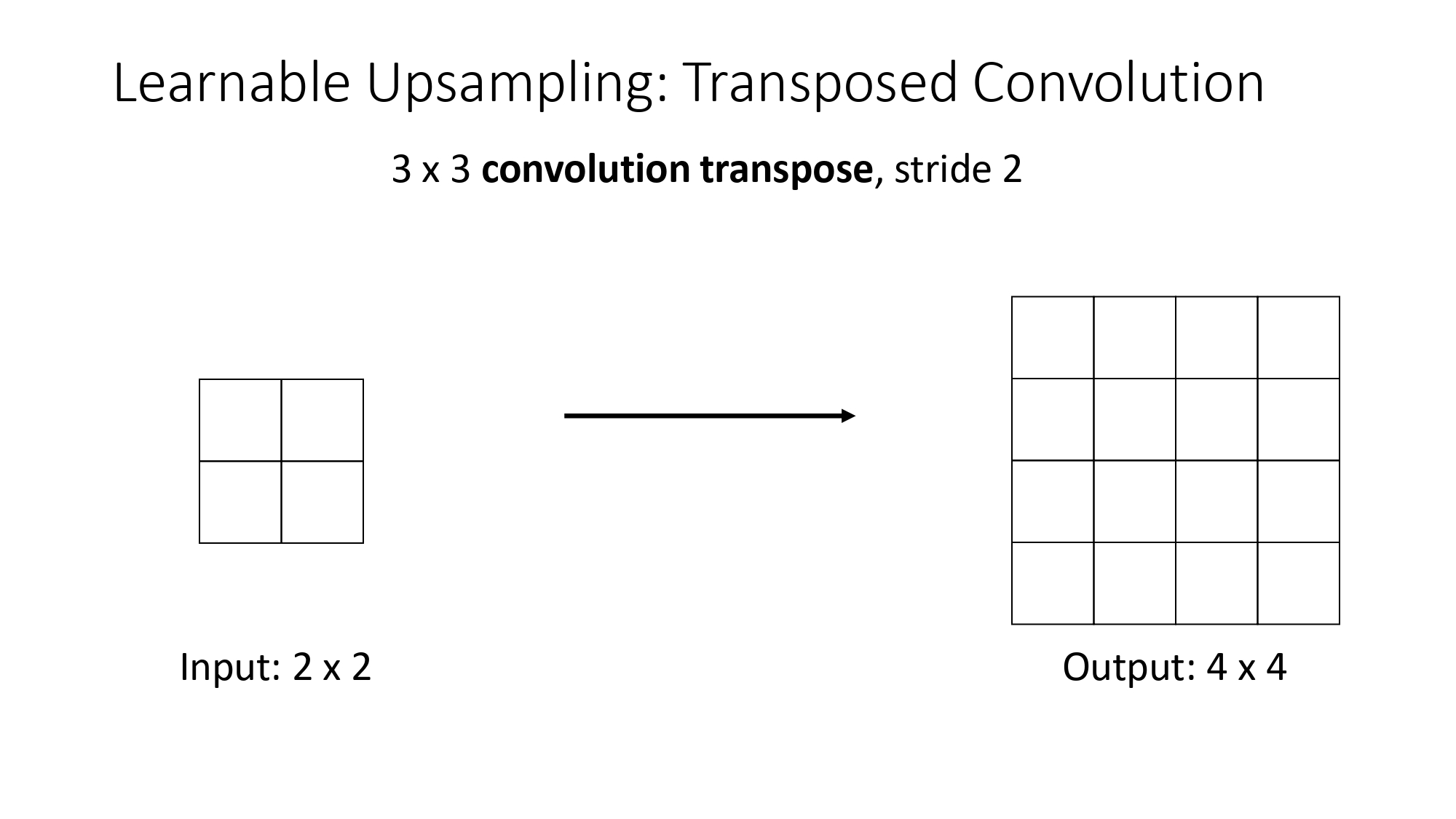
القلبة: الـ Transposed Convolution
هون إحنا بنعمل العكس تماماً! بدل ما نجمع منطقة ونطلع بكسل، بناخد بكسل
واحد ونفرشه على منطقة كاملة:
المبدأ (Weighting): بناخد قيمة البكسل من المدخل الصغير، وبنضربها بـ كل خلايا الفلتر. الناتج بكون مصفوفة بنفس حجم الفلتر بنحطها في المخرج الكبير.
شو الـ Stride هون؟ في الـ Transposed Conv، الـ Stride بحدد قديش الفلتر "بمشي" في المخرج مش في المدخل. إذا الـ Stride = 2، فإحنا بنبعد المخرجات عن بعضها بـ 2 بكسل.
المبدأ (Weighting): بناخد قيمة البكسل من المدخل الصغير، وبنضربها بـ كل خلايا الفلتر. الناتج بكون مصفوفة بنفس حجم الفلتر بنحطها في المخرج الكبير.
شو الـ Stride هون؟ في الـ Transposed Conv، الـ Stride بحدد قديش الفلتر "بمشي" في المخرج مش في المدخل. إذا الـ Stride = 2، فإحنا بنبعد المخرجات عن بعضها بـ 2 بكسل.
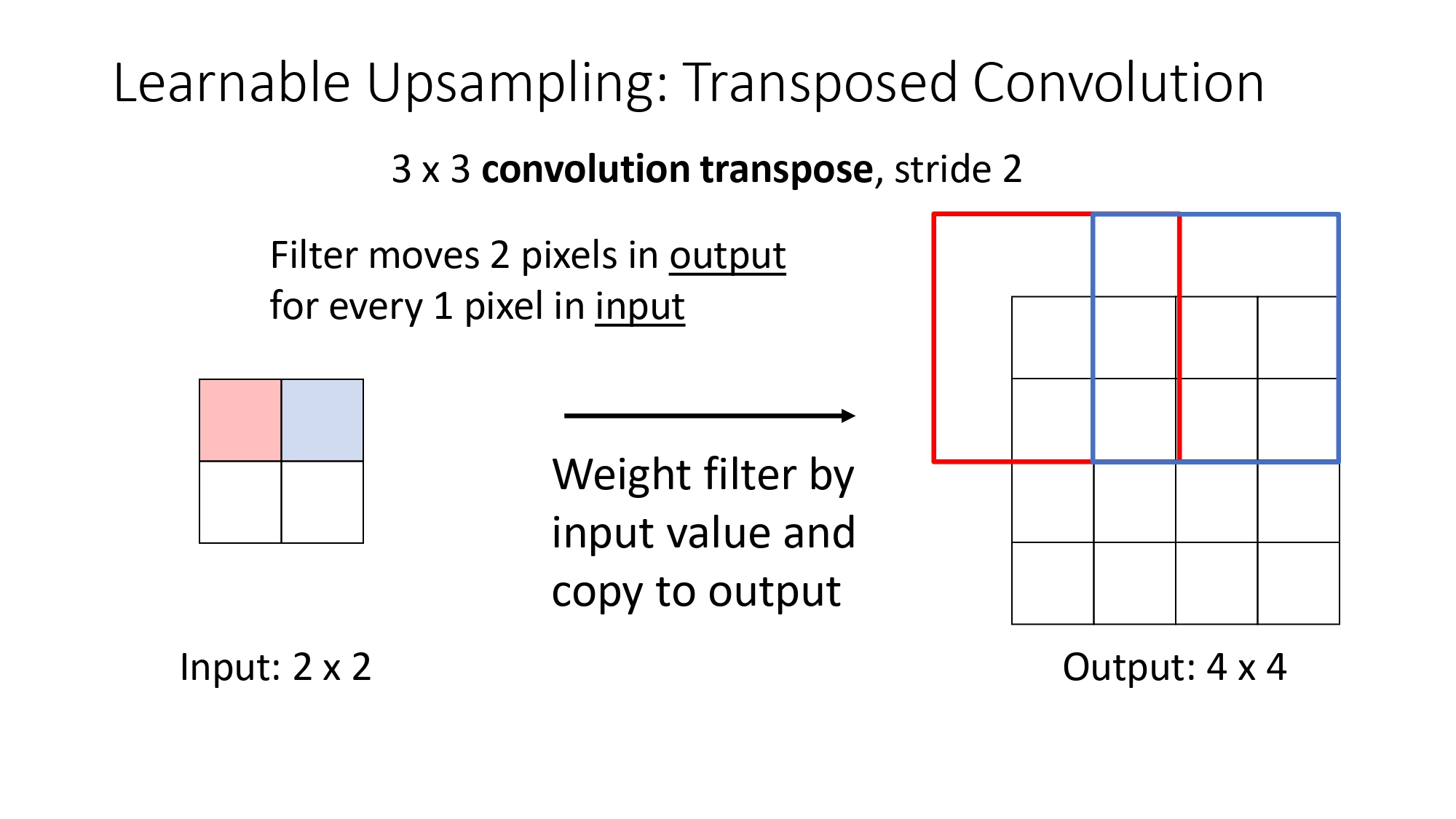
شو بصير بالمناطق المشتركة (Overlap)؟
لما نفرش الفتحات جنب بعضها، أكيد رح يكون في تداخل بين المناطق. الحل
بسيط وذكي:
ليش اسمه "قابل للتعلم" (Learnable)؟ لأن قيم الفلتر نفسه مش ثابتة زي ما كنا بنعمل بالـ Bilinear Interpolation. هون، الشبكة هي اللي بتتعلم شو أحسن أرقام تكون بالفلتر عشان تكبّر الصورة بأدق شكل ممكن خلال الـ Training.
بكل بساطة، إحنا بنجمع (Sum)قيم البكسلات في مناطق التداخل. هاض
الجمع بساعد الشبكة إنها تتعلم انتقالات ناعمة وما يكون في تقطيع
بالصورة.
ليش اسمه "قابل للتعلم" (Learnable)؟ لأن قيم الفلتر نفسه مش ثابتة زي ما كنا بنعمل بالـ Bilinear Interpolation. هون، الشبكة هي اللي بتتعلم شو أحسن أرقام تكون بالفلتر عشان تكبّر الصورة بأدق شكل ممكن خلال الـ Training.
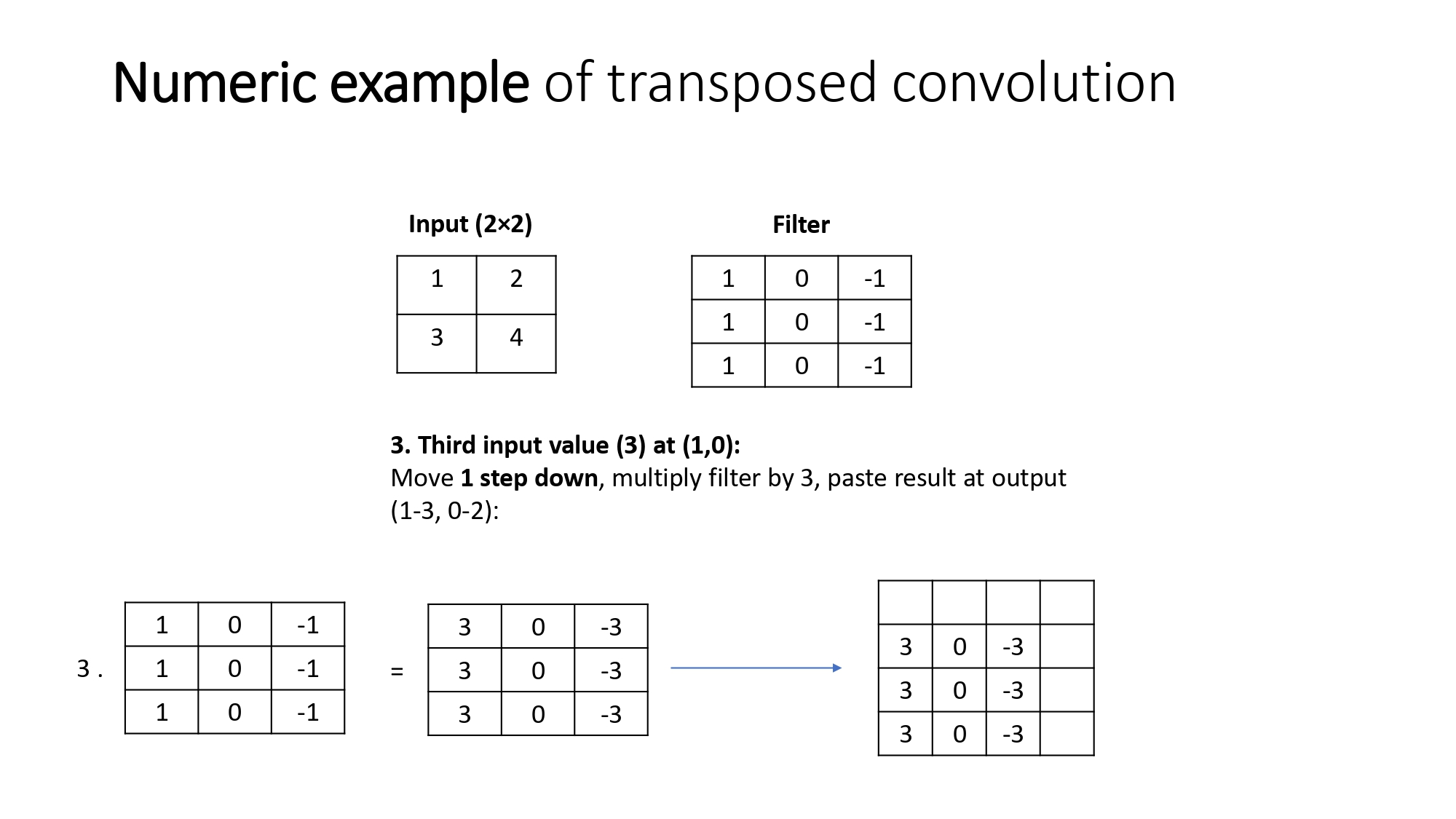
نمشي حبة حبة: مثال بالأرقام
عشان نثبت الفكرة، خلينا نمشي مع المثال اللي بالصورة (مدخل $2 \times 2$ وفلتر $3 \times 3$ بـ $Stride
= 1$):
- الخطوة الأولى: قيمة أول بكسل بالمدخل (مثلاً 1).. بنضربها بالفلتر كامل ($1 \times \text{Filter}$) وبننسخ النتيجة في الزاوية فوق يسار بالمخرج.
- الخطوة الثانية: بنمشي بكسل واحد بالمدخل، وبنضرب قيمته (مثلاً 2) بالفلتر كامل. القيمة الناتجة بنعملها Paste في المخرج بس بنزيح خطوة وحدة (حسب الـ Stride).
- الخطوة الثالثة (المهمة): في بكسلات رح "تركب فوق بعضها" (Overlap). هون إحنا ما بنختار وحدة، بنجمعهم مع بعض!هاض الجمع هو اللي بخلي الصورة تطلع "منسجمة" مش جزر معزولة.
تطبيق القانون عالمثال:
$O = (2 - 1) \times 1 - 2(0) + 3 = 4$
هاض معناه إن المخرج رح يكون $4
\times 4$، وهيك كبرنا الصورة من $2 \times 2$ لـ $4 \times 4$ بذكاء!
إذا كان عندك مدخل حجمه $4 \times 4$، واستخدمت Transposed Conv بـ Stride = 2،
و Padding = 1، وفلتر حجمه $3
\times 3$..
كم بطلع حجم المخرج (H2 & W2)؟
كم بطلع حجم المخرج (H2 & W2)؟
الحل الخطوة بخطوة:
- $I = 4, S = 2, P = 1, K = 3$
- $O = (4 - 1) \times 2 - 2(1) + 3$
- $O = (3) \times 2 - 2 + 3$
- $O = 6 - 2 + 3 = 7$

كيف بتتعلم الشبكة؟ (Backpropagation)
الآن بعد ما خلصنا الـ Forward Pass وطلعنا صورة مصنفة لكل بكسل، كيف
الشبكة بتعدل نفسها؟
- Loss Calculation: بنقارن الصورة اللي طلعت من الشبكة مع الصورة الحقيقية (Ground Truth). بنستخدم اشي اسمه Cross-Entropy Loss بس "لكل بكسل" لحاله.
- Shared Loss, Individual Updates: ركز هون! إحنا بنحسب خسارة وحدة كلية (Scalar Value) بتمثل كل الصورة، بس لما نرجع بالـ Backprop، كل "وزن" في الشبكة (سواء كان في الـ Conv أو الـ Transposed Conv) رح يتعدل حسب قديش هو شارك بخطأ المخرج.
- End-to-End: هاض المصطلح معناه إننا بنقدر ندرب الشبكة كلها من أول بكسل في المدخل لآخر بكسل في المخرج بضربة وحدة، بدون ما نحتاج تدخل بشري في النص.
المشكلة الكبرى: ضياع التفاصيل!
أكبر مشكلة في الـ FCN هي إننا لما نصغر الصورة (Downsampling)، إحنا
بنفقد المعلومات المكانية الدقيقة. حواف الأشياء بتصير مغبشة لأن الـ
Decoder ما عنده علم "وين بالضبط" كانت الحواف الأصلية.

ليش الـ FCN لحالها ما بتكفي؟
شفنا إن الـ Transposed Conv بتكبر الصورة، بس المشكلة إنها "بتخمن"
التفاصيل تخمين.
المعضلة (The Trade-off):
الحل العبقري: شبكة الـ U-Net اللي بتستخدم الـ Skip Connections عشان ترجع هاي التفاصيل الضايعة.
المعضلة (The Trade-off):
- لما ندخل جوا الـ Encoder، الشبكة بتفهم "شو" الأجسام الموجودة بذكاء عالي (Semantic Richness).
- بس بنفس الوقت، بسبب الـ Pooling، بنخسر "وين" مكانهم بالضبط (Spatial Resolution).
الحل العبقري: شبكة الـ U-Net اللي بتستخدم الـ Skip Connections عشان ترجع هاي التفاصيل الضايعة.
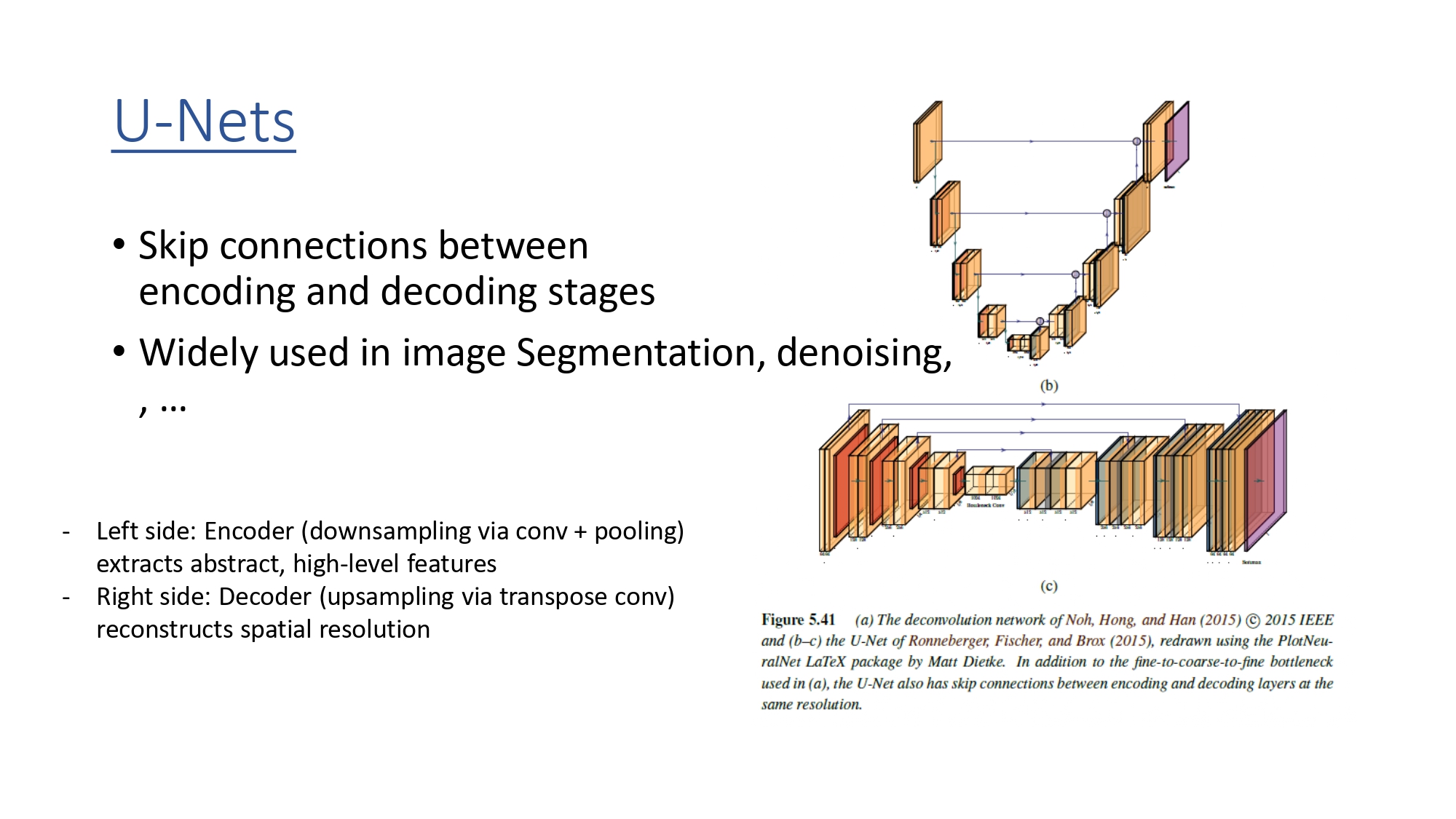
هيكل الـ U-Net: الجسر العجيب
ليش اسمها U-Net؟ لأن شكلها زي حرف U:
- الجهة اليسار (Encoder): مهمتها تضغط الصورة وتفهم المعنى. بكل مرحلة، المساحة بتصغر بس عدد الفلاتر (العمق) بيزيد.
- الجهة اليمين (Decoder): مهمتها ترجع تكبّر الصورة. هون بنستخدم الـ Transposed Conv.
- الـ Skip Connections: هي الجسور الأفقية اللي بالصورة. بناخد المخرجات من الـ Encoder وبنلزقها لزق مع اللي بقابلها في الـ Decoder.

كيف الـ Skip Connections بتغير اللعبة؟
الفكرة مش بس "ربط"، الفكرة هي Concatenation (التوصيل المتوازي):
هاذ الدمج بخلي الشبكة تطلع Segmentation Mask دقيق جداً، حوافه حادة، حتى للأجسام الصغيرة جداً اللي كانت الـ FCN العادية بتنساها.
الـ Decoder الآن صار عنده نوعين من
المعلومات بكل طبقة:
1. معلومات عميقة: جاية من الطبقة اللي تحت (بتقوله شو الجسم).
2. تفاصيل حادة: جاية من الجسر (بتقوله وين الحواف والحدود بالضبط).
1. معلومات عميقة: جاية من الطبقة اللي تحت (بتقوله شو الجسم).
2. تفاصيل حادة: جاية من الجسر (بتقوله وين الحواف والحدود بالضبط).
هاذ الدمج بخلي الشبكة تطلع Segmentation Mask دقيق جداً، حوافه حادة، حتى للأجسام الصغيرة جداً اللي كانت الـ FCN العادية بتنساها.

الخلاصة: شو بتستفيد الـ U-Net؟
في النهاية، الـ U-Net هي المعيار الذهبي حالياً في التصوير الطبي وغيره
لأنها:
- بتحافظ على Spatial Information (المعلومات المكانية).
- بتحل مشكلة العتمة والغبش (Blurriness) في المخرجات.
- بتتعلم كيف توازن بين "شو الجسم" و "وين مكانه" بضربة وحدة.
مثال واقعي: عملية جراحية بالدماغ
تخيل إنك دكتور وبدك تحدد مكان ورم خبيث في صورة رنين مغناطيسي باستخدام
الـ U-Net:
1. الـ Encoder (شوف الشاشة): الشبكة بتشوف الصورة كاملة وبتحكي "يا دكتور، أنا متأكدة إنه في ورم بالجهة اليمين". بس لأنها صغرت الصورة لتفهمها، بطلت تعرف حدوده بالضبط.
2. الـ Skip Connections (جسر الإنقاذ): الشبكة بتفتح "خط ساخن" مع الطبقات الأولى اللي لسا عندها الصورة بجودة عالية. بتقولها: "اعطيني مكان الحواف بالضبط".
3. النتيجة النهائية: الـ Decoder باخد المعنى (فيه ورم) مع الحواف الدقيقة (وين حدوده)، وبيرسم لك خريطة بكسل بكسل. هيك الدكتور بقدر يشيل الورم بدون ما يلمس الأنسجة السليمة.
1. الـ Encoder (شوف الشاشة): الشبكة بتشوف الصورة كاملة وبتحكي "يا دكتور، أنا متأكدة إنه في ورم بالجهة اليمين". بس لأنها صغرت الصورة لتفهمها، بطلت تعرف حدوده بالضبط.
2. الـ Skip Connections (جسر الإنقاذ): الشبكة بتفتح "خط ساخن" مع الطبقات الأولى اللي لسا عندها الصورة بجودة عالية. بتقولها: "اعطيني مكان الحواف بالضبط".
3. النتيجة النهائية: الـ Decoder باخد المعنى (فيه ورم) مع الحواف الدقيقة (وين حدوده)، وبيرسم لك خريطة بكسل بكسل. هيك الدكتور بقدر يشيل الورم بدون ما يلمس الأنسجة السليمة.
الخلاصة الجوهرية:
الـ U-Net دمجت بين خبرة "الدكتور الشاطر" اللي بعرف شو العلة (المعنى)، وبين دقة "الروبوت الذكي" اللي بحدد المكان بالملي بكسل.
عشان هيك هي ملكة الـ Segmentation بلا منازع!
الـ U-Net دمجت بين خبرة "الدكتور الشاطر" اللي بعرف شو العلة (المعنى)، وبين دقة "الروبوت الذكي" اللي بحدد المكان بالملي بكسل.
عشان هيك هي ملكة الـ Segmentation بلا منازع!