تذكروا لما كنا نحكي عن الـ CNN وكيف كانت بتمشي بفلتر صغير على الصورة؟ هاي
الطريقة كانت الملكة لسنين طويلة. بس في سنة 2020، إجا حدا وحكا: ليش ما نعامل الصورة كأنها نص؟
في هاض الشابتر، رح نشوف كيف بنقطع الصورة لقطع (Patches)، وبنعطي كل قطعة
هويتها، وبنخليها "تسولف" مع باقي القطع عشان تفهم الصورة الكبيرة. هاض التحول هو اللي خلى الذكاء الاصطناعي
يوصل لمستويات خرافية اليوم.
هاض الشابتر هو "الموضة" الحالية في عالم الـ AI!
القصة: لما الكمبيوتر بطل يشوف الصورة بكسلات، وصار يقرأها قراءة!

بداية الرحلة
اليوم بدنا نحكي عن الـ Vision Transformer، أو اختصاراً ViT. هاض المودل هو اللي قلب الموازين وخلى تقنيات معالجة اللغات (زي
GPT) تدخل بقوة في معالجة الصور.

شو هو الـ ViT اصلاً؟
ببساطة، الـ ViT هو تطبيق لمعمارية الـ Transformer على تصنيف الصور. عشان يشتغل، لازم نعرف أربع نقاط رئيسية:
- تقطيع الصورة: بنقص الصورة لمربعات صغيرة بنسميها Patches.
- التمثيل الرقمي (Embedding): بنحول كل مربع لمجموعة أرقام (Vector) يفهمها الكمبيوتر.
- المعلومات المكانية: بنضيف أرقام بتعرف الكمبيوتر "وين هاض المربع مكانه بالصورة" (Positional Information).
- الـ Self-Attention: الميكانيكية السحرية اللي بتخلي كل قطعة "تركز" على القطع الثانية المهمة عشان تفهم شو بالصورة.
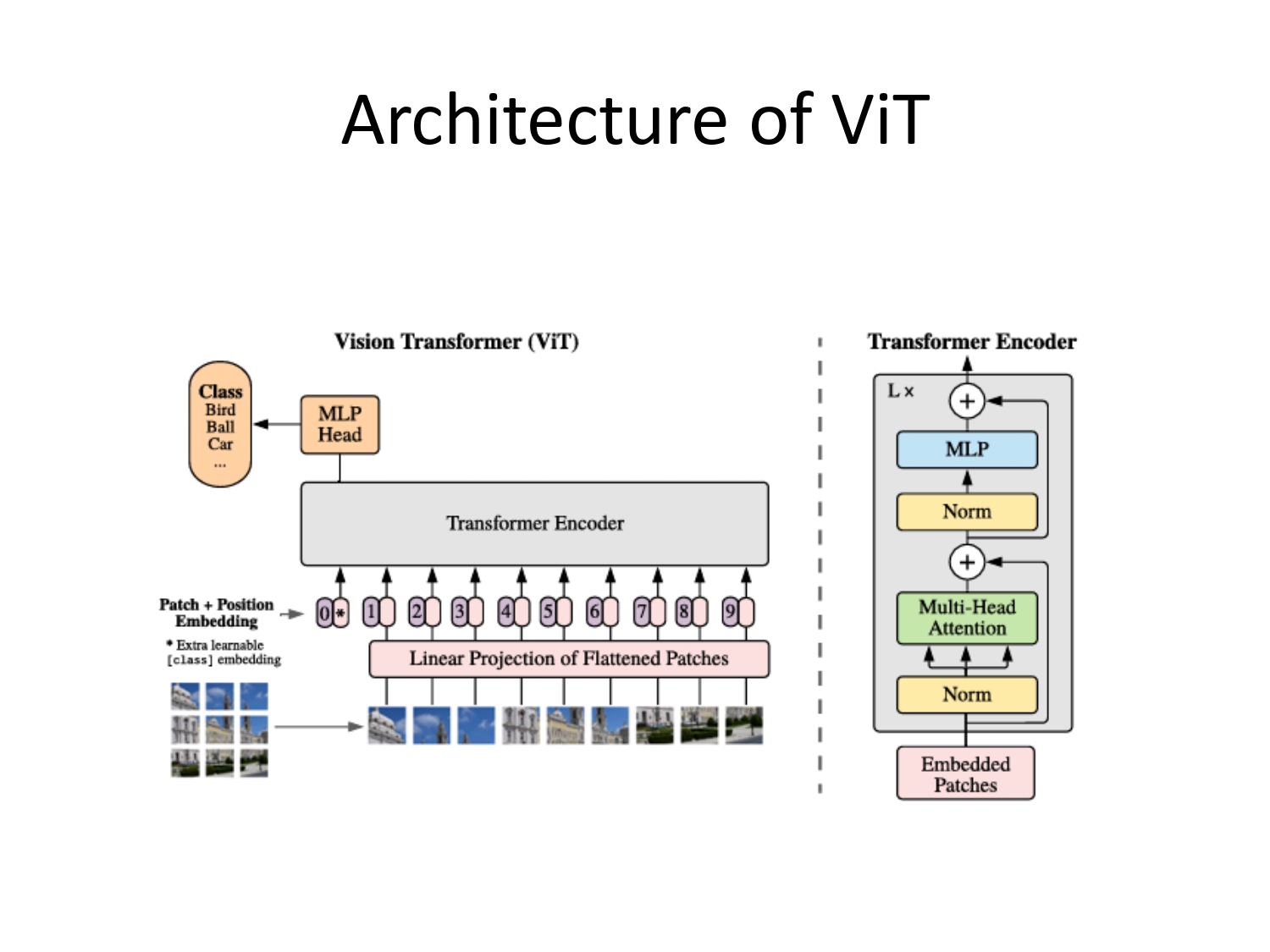
نظرة على "الهيكل" العظمي للمودل
شوف هالصورة معي، هاي بتلخص كل العملية:
- بتبلش الصورة تنقسم لـ Patches.
- بتحولوا لـ Linear Projection (يعني بنمط مطهم لخط واحد).
- بنضيف عليهم [class] token (هاض أهم واحد، هو اللي بجمع الخلاصة).
- بيدخلوا كلهم على الـ Transformer Encoder اللي فيه Multi-Head Attention وطبقات MLP.
- بالآخر، الـ MLP Head بحكيلك الصورة شو فيها (سيارة، عصفور، إلخ).

خطوات العمل بالترتيب
عشان ما نضيع، هاي هي الخطوات الخمسة اللي بتصير جوا:
- 1. التقطيع: بنقص الصورة لقطع، مثلاً كل قطعة $16 \times 16$ بكسل.
- 2. التسطيح (Flatten): بنحول المربع الصغير لخط واحد من الأرقام وبنعمله Embedding.
- 3. الترقيم: بنضيف الـ Positional Encoding عشان نعرف مين جنب مين.
- 4. التغذية: بندخل هالتسلسل من القطع على الـ Transformer Encoder.
- 5. التصنيف: بناخد المخرج تبع الـ [CLS] token بس، وهو اللي بحكم على الصورة.

الثلاثي المرح: Q، K، و V
ركز معي هون لأن هاض هو "مخ" الـ Transformer. كل قطعة بالصورة بتتحول لـ 3 شغلات:
ملاحظة: هاي الـ $Q, K, V$ بنطلعهم من خلال طبقات قابلة للتعلم بنسميها Linear Projections ($W_q, W_k, W_v$).
- Q (Query): "السؤال" اللي القطعة بتسأله لغيرها (مثلاً: "في حدا فيكم بشبه عين القطة؟").
- K (Key): "المفتاح" أو الهوية تبعت القطعة (مثلاً: "أنا بكسلات بمثل فرو رمادي").
- V (Value): "المعلومة" الحقيقية اللي رح تتمرر لو السؤال جاوبه صح.
ملاحظة: هاي الـ $Q, K, V$ بنطلعهم من خلال طبقات قابلة للتعلم بنسميها Linear Projections ($W_q, W_k, W_v$).

ليش بنضرب في V بالآخر؟
العملية بسيطة بس ذكية:
- بنضرب الـ $Q$ في الـ $K$ عشان نطلع "علامات التشابه" (Attention Scores).
- بنستخدم الـ Softmax عشان نخلي مجموعهم 1 (يعني بنوزع الاهتمام كنسب مئوية).
- الضرب في V: هاي هي الخطوة اللي بتجمع "الفائدة". إحنا بنضرب النسبة اللي طلعناها في محتوى القطعة ($V$)، هيك بنكون أخدنا الخلاصة من كل القطع المهمة.

مثال عملي: القطة والسجادة
تعال نطبق المثال اللي بالصورة:
عندنا 4 قطع (Patches):
عندنا 4 قطع (Patches):
- Patch 1: رأس القطة.
- Patch 2: جسم القطة.
- Patch 3: السجادة.
- Patch 4: الحيط.

الخطوة الأولى والثانية: حساب النتائج
تخيل إن "رأس القطة" (Patch 1) هو اللي قاعد بسأل بقية القطع:
- بناخد الـ $Q_1$ تبعه وبنعملها Dot Product مع كل الـ $K$ للقطع الباقية ($K_1, K_2, K_3, K_4$).
- رح يطلع عندنا نتائج ($S_1, S_2, S_3, S_4$).

الخطوة الثالثة: الخلاصة الموزونة
هون بنحسب الـ Output النهائي لرأس القطة كـ "سؤال":
تذكر: هاي العملية بتنعاد لكل بكسل (أو قطعة) في الصورة، يعني كل قطعة بتعرف كل اللي حولها.
$$Output_1 = S_1 \cdot V_1 + S_2 \cdot V_2 + S_3 \cdot V_3 + S_4 \cdot V_4$$
إحنا فعلياً "جمعنا" معلومات من كل القطع، بس أعطينا وزن ثقيل للقطع اللي بتخص القطة، وأهملنا تقريباً
القطع اللي ما الها دخل.
تذكر: هاي العملية بتنعاد لكل بكسل (أو قطعة) في الصورة، يعني كل قطعة بتعرف كل اللي حولها.

ليش الـ V بالذات؟ (تعميق)
لأن الـ $V$ هو اللي فيه "العفش" أو المحتوى الحقيقي للقطعة.
الـ $Q$ والـ $K$ شغلهم بس "دلالين"؛ بحكولك وين تطلع ومين مهم. بس لما تقرر وين تطلع، بدك تاخد المعلومة، وهي هاي الـ V vectors. إحنا بنجمع المعلومات وبنعملها Summarize بذكاء.
الـ $Q$ والـ $K$ شغلهم بس "دلالين"؛ بحكولك وين تطلع ومين مهم. بس لما تقرر وين تطلع، بدك تاخد المعلومة، وهي هاي الـ V vectors. إحنا بنجمع المعلومات وبنعملها Summarize بذكاء.

البطل الخفي: الـ [CLS] Token
الـ [CLS] Token هو قطعة "إضافية" زيادة عن قطع الصورة، بنحطها أول
التسلسل.
- جمع المعلومات: هو ملوش صورة، بس وظيفته إنه يسأل كل القطع الثانية وياخد منهم الخلاصة.
- الهوية الشاملة: بنهاية الطبقات، هاض الـ Token بصير يمثل "الصورة ككل" مش بس قطعة منها.
- التصنيف: إحنا بنكب كل مخرجات القطع الثانية، وبناخد بس الـ Output تبع هاض الـ Token عشان ندخله على المصنف النهائي.

اللمسات الأخيرة
بعد الـ Attention، بتمر المعلومات بخطوات روتينية بس ضرورية:
- Multi-head Attention Layer: عشان نشوف الصورة من أكثر من زاوية (مش بس زاوية وحدة).
- Add & Norm: بنضيف القيم الأصلية (Residual) وبنعملها تنظيف (Normalization) عشان الشبكة ما تضيع.
- Feed-forward MLP: طبقة عصبية عادية عشان تعالج البيانات اللي طلعت.
- Class Prediction: بناخد مخرج الـ [CLS] وبنوديه للـ MLP Head اللي بحكيلنا النتيجة النهائية.