تخيل إنك واقف قدام لوحة فنية ضخمة، وبدك تطلع منها بس "الخطوط العريضة". مش رح تقدر تشوف كل التفاصيل
مرة وحدة، رح تضطر تمشي "عدسة مكبرة" على كل شبر باللوحة وتركز..
هاض بالظبط هو الـ Convolution. هو الفلتر اللي بمشي على الصورة "بكسل بكسل"،
وبقرر هاض الجزء مهم ولا لأ. بدون هالعملية، الكمبيوتر بظل شايف الصورة "عجقة" أرقام، بس مع الـ Convolution، ببلش يفهم وين الحواف، وين الزوايا، وكيف بميز وجهك عن رغيف
الخبز!
🎬 القصة: كيف الكمبيوتر "بفرز" اللي شايفه؟

كل شي حولنا هو "إشارة":
كلمة Signal معناها تمثيل للمعلومات كدالة بتتغير مع الزمن أو المكان أو
التردد.
- Analog Signal: إشارة مستمرة (زي الموجات الصوتية في الطبيعة).
- Digital Signal: إشارة رقمية، بنحصل عليها لما نعمل Sampling للإشارة الأصلية عشان يفهمها الكمبيوتر.
- 1-D: زي الصوت (Audio) ونبضات القلب.
- 2-D: زي الصور الرمادية (Grayscale).
- 3-D: زي الصور الملونة (RGB).

تشريح الصورة الرقمية:
الكمبيوتر بشوف الصور بطريقتين حسب النوع:
- Gray-scale image (2D): قناة وحدة، وكل بكسل فيه رقم بيعبر عن شدة الإضاءة (من 0 لـ 255).
- RGB image (3D): ثلاث قنوات (أحمر، أخضر، أزرق)، بنعامل كل وحدة فيهم كأنها صورة رمادية لحالها.
📍 قاعدة الحساب: عشان نعرف مساحة التخزين (Bits)، بنستخدم
المعادلة:
b = M × N × k × C
حيث M, N الأبعاد، k عدد البتات، و
C عدد القنوات.
💡 مثال بالأرقام: تخيل لو عندنا صورة ملونة (RGB) حجمها 100x100 بكسل،
وبنستخدم 8 بت لكل بكسل في كل قناة:
الحسبة بتصير: 100 (H) × 100 (W) × 8 (k) × 3 (C) = 240,000 Bits.
الحسبة بتصير: 100 (H) × 100 (W) × 8 (k) × 3 (C) = 240,000 Bits.

وين بنستخدم الـ Convolution؟
الـ Convolution مش بس للصور، هي عملية رياضية بتدخل في أغلب مجالات
التكنولوجيا الحديثة:
- Signal Processing: هي الأساس في معالجة الإشارات بكل أنواعها (Audio, Radar, Sonar). بتساعدنا نعمل Filtering للموجات ونشيل الـ Noise (التشويش) ونطلع الميزات المهمة من الإشارة.
- Natural Language Processing (NLP): في معالجة اللغات، بنستخدم الـ 1D Convolutions فوق النصوص والكلمات عشان مهام مثل Sentiment Analysis (فهم شعور الكاتب) وتصنيف النصوص.
- Speech Recognition: أنظمة التعرف على الكلام بتعتمد على الـ CNNs عشان تسحب ميزات الصوت وتحلل الترتيب الزمني للكلمات بدقة.
- Image Processing: هون بنعمل العمليات اللي بنشوف نتائجها بالعين، زي كشف الحواف (Edge Detection)، زيادة الحدة (Sharpening)، أو تنعيم الصورة (Blurring).
- Computer Vision: الملك في هاض المجال! الـ Convolution هي العملية الأساسية في كل شبكات الـ CNNs اللي بتخلي الكمبيوتر يقدر يعمل Object Detection (تحديد الأجسام) و Tracking (تتبع الحركة).

المعادلة الرياضية (لا تخاف منها):
هون بنبلش الجد! الصورة صارت 2D Input، والفلتر صار 2D Filter بحجم m x n.
المعادلة اللي شايفينها بتشرح كيف بنجمع حاصل ضرب البكسلات بالجيران. في نوعين من الجيران:
المعادلة اللي شايفينها بتشرح كيف بنجمع حاصل ضرب البكسلات بالجيران. في نوعين من الجيران:
- Preceding neighbours: الجيران اللي "قبل" البكسل الأساسي.
- Succeeding neighbours: الجيران اللي "بعد" البكسل الأساسي (وهاد هو المستعمل عملياً).
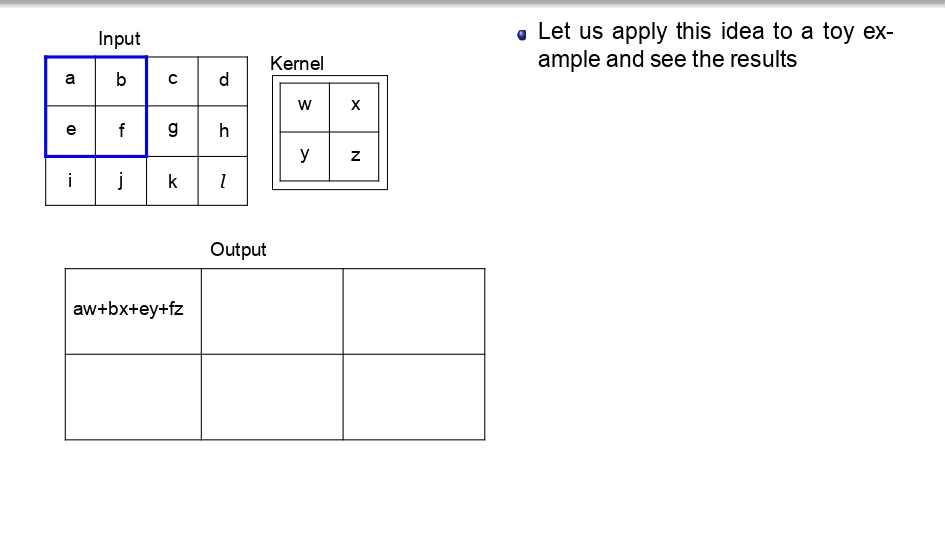
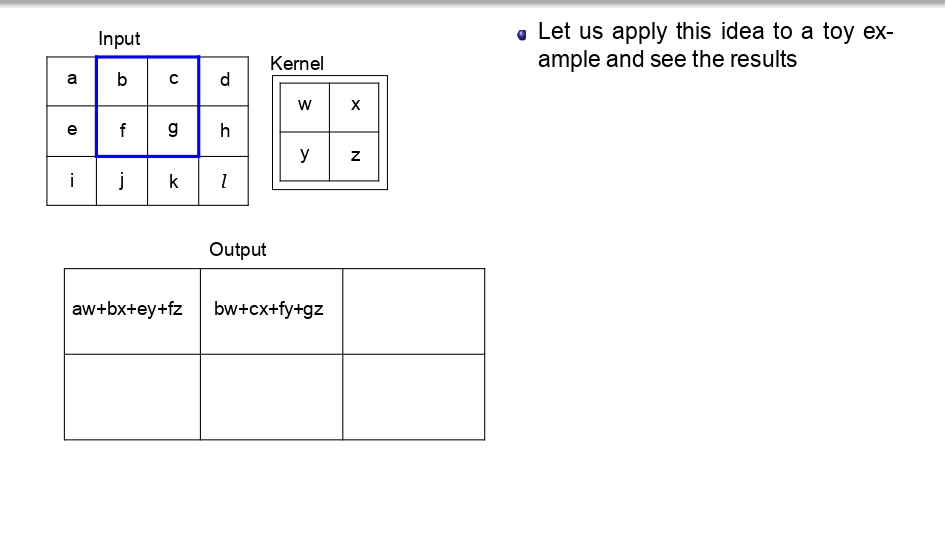
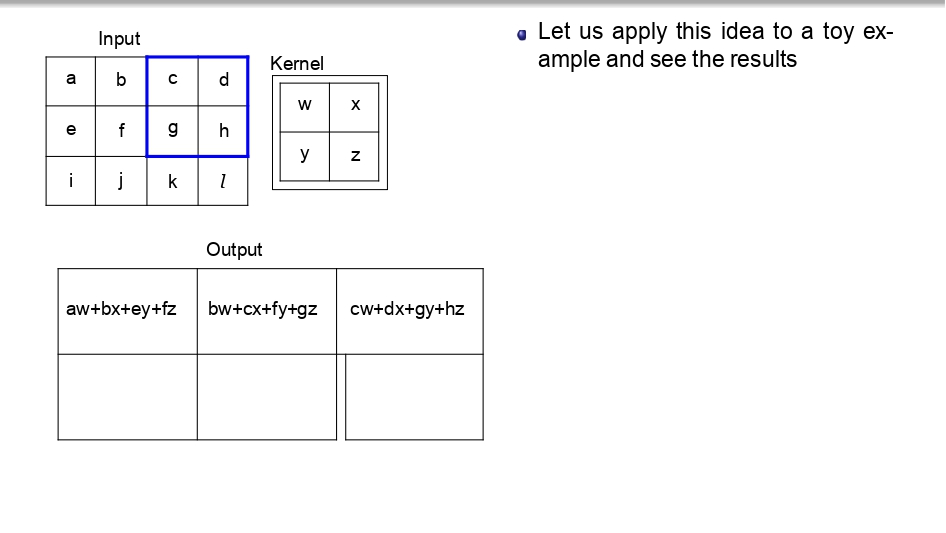
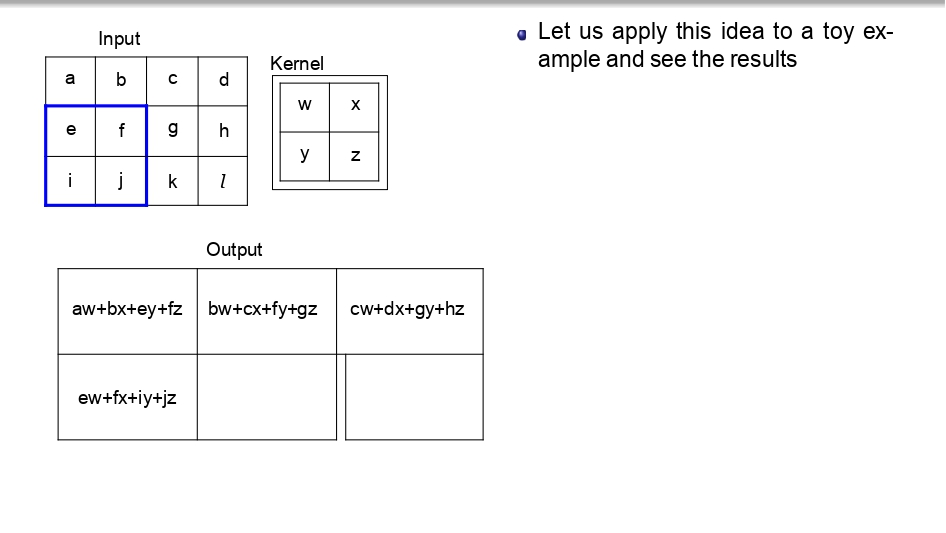
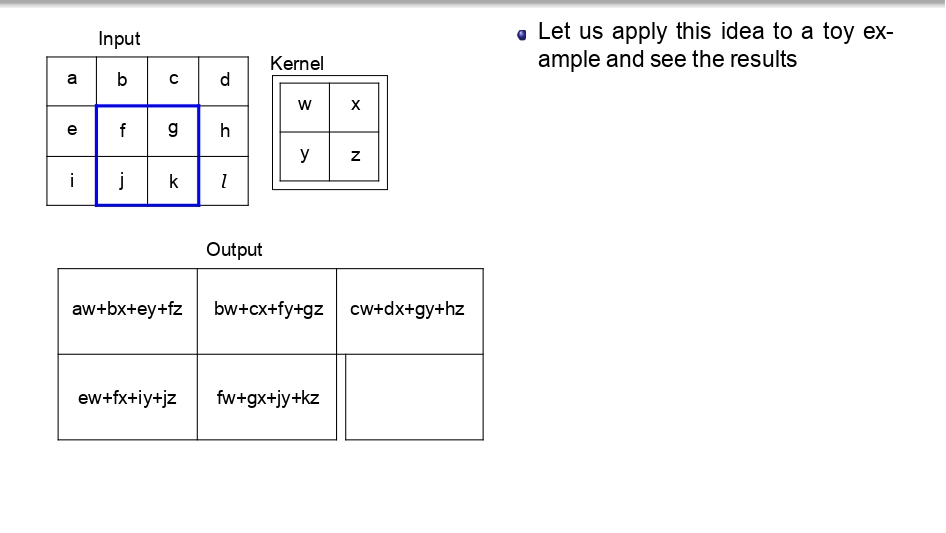
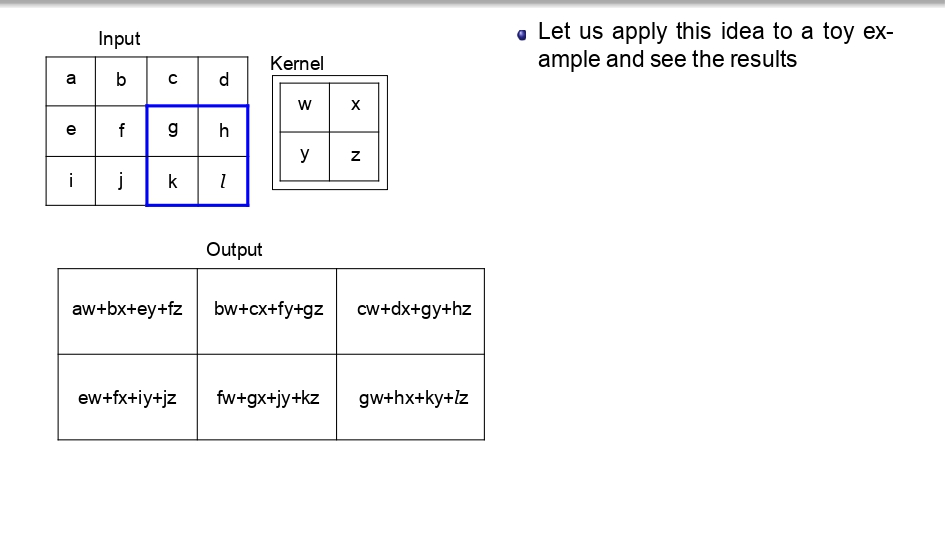
👈 اسحب لليسار لتشوف خطوات التحرك (Step-by-Step) 👉
تتبع العملية (Toy Example):
بدل ما نضيع وقتنا، شوفوا كيف الـ Kernel بمشي بكسل بكسل:
- بالبداية بضرب (aw+bx+ey+fz) عشان يطلع أول بكسل في الناتج.
- بعدين "بزحلق" خطوة لليحمين وبكرر نفس العملية.
- بخلص الصف الأول، وبنزل للصف اللي تحته.. وهكذا لحد ما يخلص الصورة كاملة.
الخلاصة: كل قيمة في الـ Output هي نتيجة "تفاعل" الفلتر مع منطقة معينة في الصورة الأصلية.
- بالبداية بضرب (aw+bx+ey+fz) عشان يطلع أول بكسل في الناتج.
- بعدين "بزحلق" خطوة لليحمين وبكرر نفس العملية.
- بخلص الصف الأول، وبنزل للصف اللي تحته.. وهكذا لحد ما يخلص الصورة كاملة.
الخلاصة: كل قيمة في الـ Output هي نتيجة "تفاعل" الفلتر مع منطقة معينة في الصورة الأصلية.

الـ Kernel في المركز:
في أغلب الحالات، بنفترض إن الـ Kernel "مركزي" (Centered) فوق البكسل اللي بنهتم فيه.
بهاي الطريقة، المعادلة بتخلينا نتطلع على الجيران اللي قبل واللي بعد في نفس الوقت، وهاذ بيعطينا دقة أكثر في استخراج الميزات وتحديد الحواف.
بهاي الطريقة، المعادلة بتخلينا نتطلع على الجيران اللي قبل واللي بعد في نفس الوقت، وهاذ بيعطينا دقة أكثر في استخراج الميزات وتحديد الحواف.

فلتر التنعيم (Blurring):
شوفوا كيف الأرقام بتغير كل شي! هون استخدمنا مصفوفة كلها 1.
ببساطة، الفلتر هون بجمع كل البكسلات اللي حول البكسل وبطلع الـ Average تبعهم. النتيجة؟ الصورة بتصير ناعمة ومغبشة (Blurs the image). هاض بنستخدمه عشان نشيل الـ Noise أو التفاصيل المزعجة الصغيرة.
ببساطة، الفلتر هون بجمع كل البكسلات اللي حول البكسل وبطلع الـ Average تبعهم. النتيجة؟ الصورة بتصير ناعمة ومغبشة (Blurs the image). هاض بنستخدمه عشان نشيل الـ Noise أو التفاصيل المزعجة الصغيرة.

فلتر التوضيح (Sharpening):
عكس اللي قبله تماماً! هون بنركز على البكسل اللي بالنص وبنعطيه قيمة عالية (5) وبنطرح القيم اللي حوله.
الحركة هاي بتخلي الفروقات بين البكسلات تزيد، فبتطلع الصورة أوضح والحدود بارزة أكثر (Sharpens the image). ممتاز لتحسين جودة الصور الباهتة.
الحركة هاي بتخلي الفروقات بين البكسلات تزيد، فبتطلع الصورة أوضح والحدود بارزة أكثر (Sharpens the image). ممتاز لتحسين جودة الصور الباهتة.

صياد الحواف (Edge Detection):
هون بنستخدم فلتر مصمم عشان "يطفي" أي منطقة لونها ثابت، وما يشتغل إلا لما يشوف
"تغيير مفاجئ" بالأرقام (يعني حافة).
النتيجة زي ما إنتو شايفين بصورة تاج محل، الصورة صارت سوداء وما بين غير الخيوط العريضة والحواف (Detects the edges). هاض هو الأساس اللي بتبني عليه السيارة اللي بتمشي لحالها عشان تميز الرصيف والشارع.
النتيجة زي ما إنتو شايفين بصورة تاج محل، الصورة صارت سوداء وما بين غير الخيوط العريضة والحواف (Detects the edges). هاض هو الأساس اللي بتبني عليه السيارة اللي بتمشي لحالها عشان تميز الرصيف والشارع.
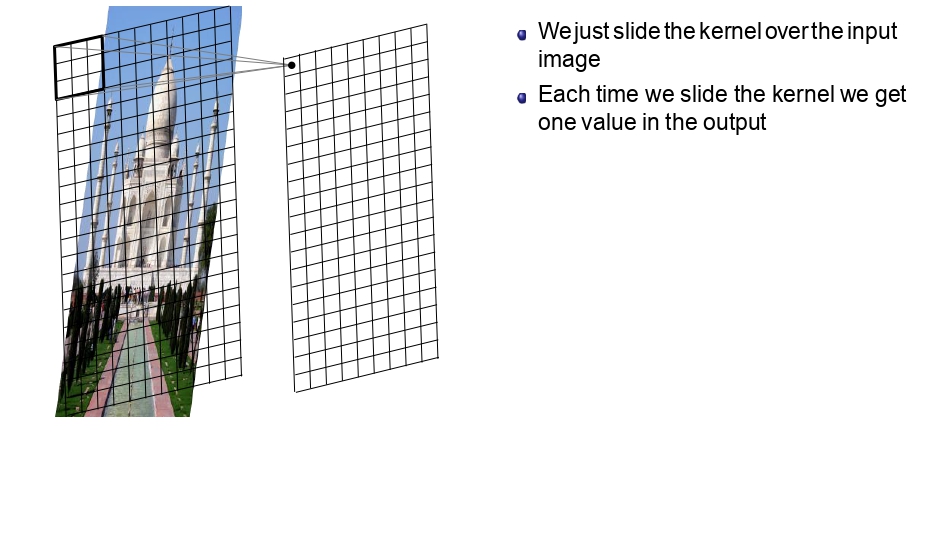
بداية المسح (أول بكسل)

اكتمال المسح (آخر بكسل)
شو اللي صار فعلياً؟
تخيل الفلتر زي "الماسح الضوئي" اللي بمشي على كل زاوية بصورة تاج محل:
- Process: الفلتر بزحف بكسل بكسل (Sliding)، وكل ما يوقف بمكان، بيعمل عمليته الرياضية وبيطلع "رقم واحد" بحطه في شبكة المخرجات.
- Feature Map: النتيجة النهائية اللي بنحصل عليها (الشبكة اللي تعبت نقاط) هي اللي بنسميها Feature Map.
- Multi-Filters: في الـ Deep Learning، إحنا ما بنستخدم فلتر واحد؛ بنستخدم عشرات الفلاتر في نفس الوقت عشان كل واحد فيهم يصيد ميزة شكل (واحد للحواف الطولية، واحد للعرضية، واحد للمنحنيات).
الـ Convolution
Layer مش وظيفتها تعطينا صورة جديدة، وظيفتها تعطينا "خريطة ميزات" بتفهم الكمبيوتر
شو الأشكال المهمة الموجودة بالصورة.

في الـ 1D:
بنتحرك على خط مستقيم (خيط)

في الـ 2D:
بنتحرك على مساحة (ورقة)
?What would happen in the 3D case
إذا كانت الصورة الملونة (RGB) بتعني 3 طبقات فوق بعض..
كيف رح يتصرف الفلتر؟ هل بيمشي على وجه واحد، ولا بيخترق العمق كله؟
تمهيد للعمق (Depth):
الأسئلة اللي شفناها بالسلايدات بتنبهنا لشغلة مهمة: العالم الحقيقي مش "مسطح".
- 1D Filter: بيمشي على "خيط".
- 2D Filter: بيمشي على "ورقة".
- 3D Filter: بيتعامل مع "مكعب" من البيانات (زي الصور الملونة أو الفيديو).

مرحلة الوحش: الـ 3D بدأت!
اربطوا الأحزمة، هسا رح ننتقل من "المساحات" لـ "الأحجام". رح نعرف كيف الـ Convolution بتقدر تعالج الألوان والعمق في نفس اللحظة.

الفلتر صار "مكعب":
بما إن الصورة صارت RGB (يعني 3 طبقات)، الفلتر بطل مجرد مربع مسطح.. صار Volume (حجم).
قاعدة ذهبية: عمق الفلتر دايماً بكون نفس عمق الصورة اللي بشتغل عليها. إذا الصورة RGB، الفلتر عمقه 3.
قاعدة ذهبية: عمق الفلتر دايماً بكون نفس عمق الصورة اللي بشتغل عليها. إذا الصورة RGB، الفلتر عمقه 3.
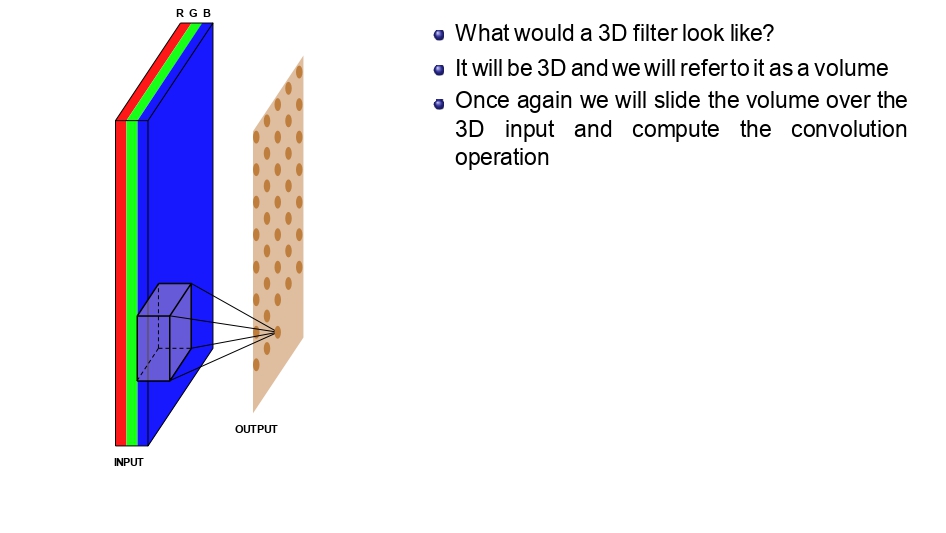
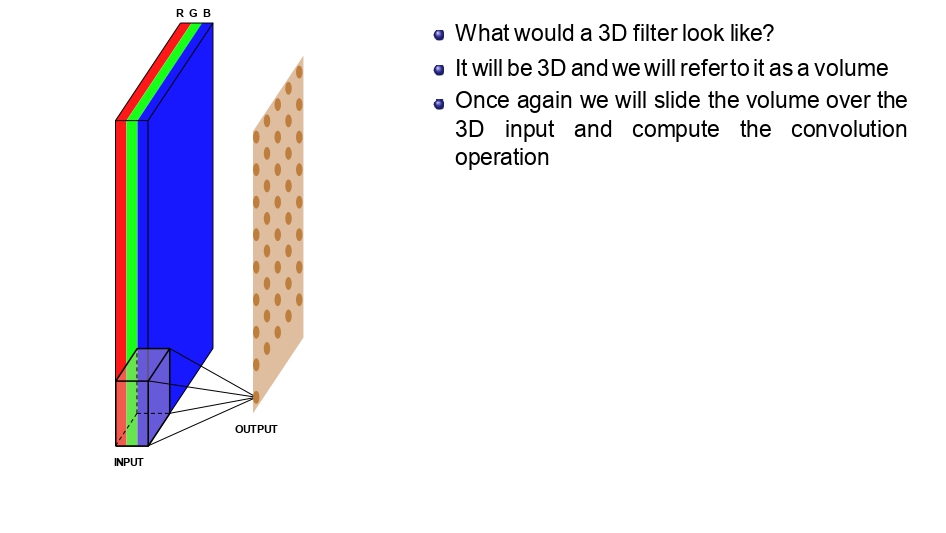
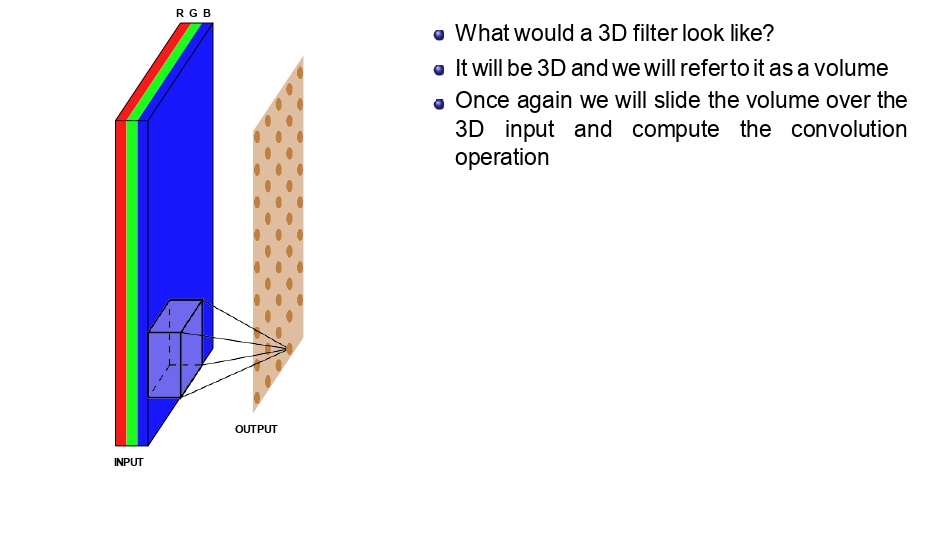
👈 المكعب بيمسح الطبقات كلها في كل وقفة 👉
كيف بتم الحركة؟
المكعب بيعمل Sliding يمين وتحت، بس ما بمشي
للداخل (العمق). هو أصلاً بغطي كل الطبقات RGB مرة وحدة.
كل ما يوقف في مكان، بضرب كل أرقامه في أرقام الصورة اللي تحته وبجمعهم، والنتيجة بتطلع لنا رقم واحد بس.
كل ما يوقف في مكان، بضرب كل أرقامه في أرقام الصورة اللي تحته وبجمعهم، والنتيجة بتطلع لنا رقم واحد بس.

قوانين المخرجات بالـ 3D:
ركزوا هون لأنها نقطة جوهرية:
- الناتج دايماً 2D: مع إننا استخدمنا فلتر 3D على صورة 3D، الناتج بطلع صفحة وحدة مسطحة (لأن كل بقعة بتعطينا رقم واحد فقط).
- تعدد الفلاتر: إذا بدنا الطبقة الجاية تكون 3D، بنستخدم أكثر من فلتر. كل فلتر بطلع لنا "صفحة" (Feature Map)، وبنجمعهم فوق بعض عشان يصيروا Volume جديد.
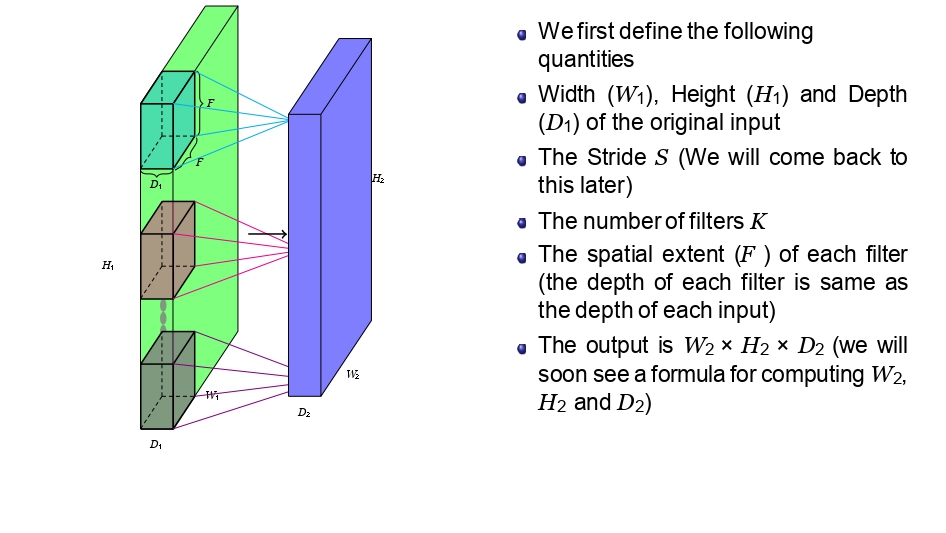
شو لازم نعرف قبل ما نحسب؟
عشان نصير "مهندسين" رؤية حاسوبية صح، لازم نعرف نسمي الأشياء بمسمياتها. هاي هي الكميات اللي رح
نستخدمها في كل المعادلات الجاية:
1. أبعاد المدخلات (Input)
- 🏷️ \(W_1\): العرض (Width)
- 🏷️ \(H_1\): الارتفاع (Height)
- 🏷️ \(D_1\): العمق (Depth)
- 🚀 \(S\): مقدار القفزة (Stride)
2. أبعاد الفلتر (Filter)
- 🏷️ \(K\): عدد الفلاتر المستخدمة
- 📐 \(F\): مساحة الفلتر المكانية (Spatial Extent)
- 💡 تذكير: عمق الفلتر دايماً بساوي عمق المدخلات (\(D_1\)).
3. أبعاد المخرجات (Output)
- 📦 \(W_2\): عرض المخرجات
- 📦 \(H_2\): ارتفاع المخرجات
- 📦 \(D_2\): عمق المخرجات (ويساوي \(K\))
سؤال: ليش عمق المخرجات (\(D_2\)) بساوي عدد الفلاتر (\(K\))؟ الجواب: لأن كل فلتر بيعمل "مسحة" كاملة وبطلع لنا صفحة وحدة بس!

ظاهرة تقلص الصور:
لاحظتوا إنه كل ما نطبق فلتر، الـ Feature Map بتطلع أصغر من الصورة
الأصلية؟
السبب: الفلتر اله "حجم"، وعشان يشتغل لازم يكون "جوا" حدود الصورة. الزوايا والأطراف ما بنقدر نمركز الفلتر عليها لأنه رح "يطلع برا". هيك بنخسر بكسلات من الأطراف في كل طبقة، وبنخسر معلومات مهمة!
السبب: الفلتر اله "حجم"، وعشان يشتغل لازم يكون "جوا" حدود الصورة. الزوايا والأطراف ما بنقدر نمركز الفلتر عليها لأنه رح "يطلع برا". هيك بنخسر بكسلات من الأطراف في كل طبقة، وبنخسر معلومات مهمة!
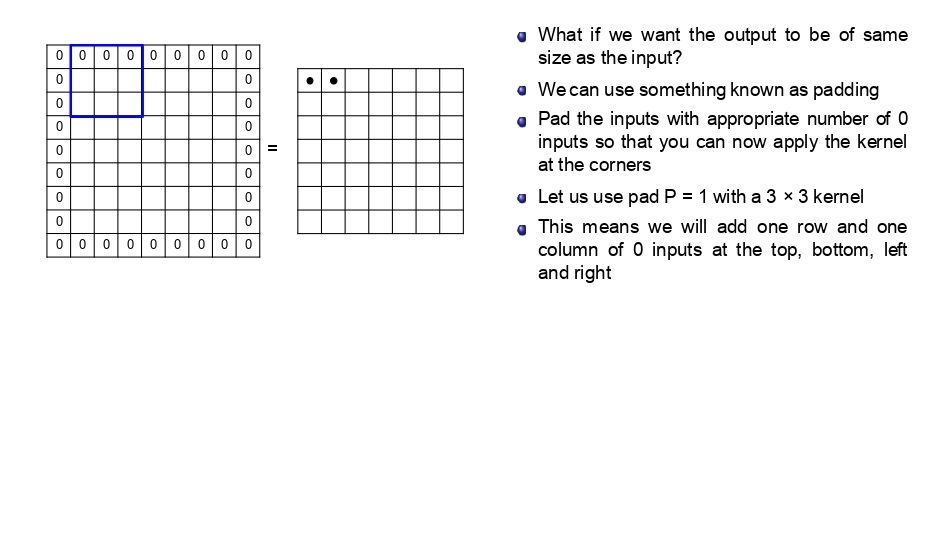
كيف بنحمي أطراف الصورة؟
عشان نحل مشكلة الزوايا، بنعمل إشي اسمه Padding.
ببساطة، بنحاوط الصورة بـ "إطار" من الأصفار. هاض الإطار بخلي الفلتر يقدر يوقف على البكسلات الأصلية
اللي كانت عالطرف بدون ما يطلع برا "المنطقة الجديدة".
✅ النتيجة: بنحافظ على حجم الصورة، وبنكسب معلومات الأطراف.
✅ النتيجة: بنحافظ على حجم الصورة، وبنكسب معلومات الأطراف.

مش دايما بدنا نمشي خطوة خطوة:
الـ Stride ويرمز له بـ S هو
"مقدار القفزة".
- إذا كان S = 1: بنمشي بكسل بكسل (تفاصيل دقيقة).
- إذا كان S = 2: بنط بكسل وبمر بغيره.. وهيك بنصغر حجم المخرجات للنص تقريباً!
🚀 الفائدة: تقليل الحسابات وتصغير حجم الداتا لما نكون بدنا نشوف "الصورة الكبيرة" مش التفاصيل الصغيرة.
- إذا كان S = 1: بنمشي بكسل بكسل (تفاصيل دقيقة).
- إذا كان S = 2: بنط بكسل وبمر بغيره.. وهيك بنصغر حجم المخرجات للنص تقريباً!
🚀 الفائدة: تقليل الحسابات وتصغير حجم الداتا لما نكون بدنا نشوف "الصورة الكبيرة" مش التفاصيل الصغيرة.
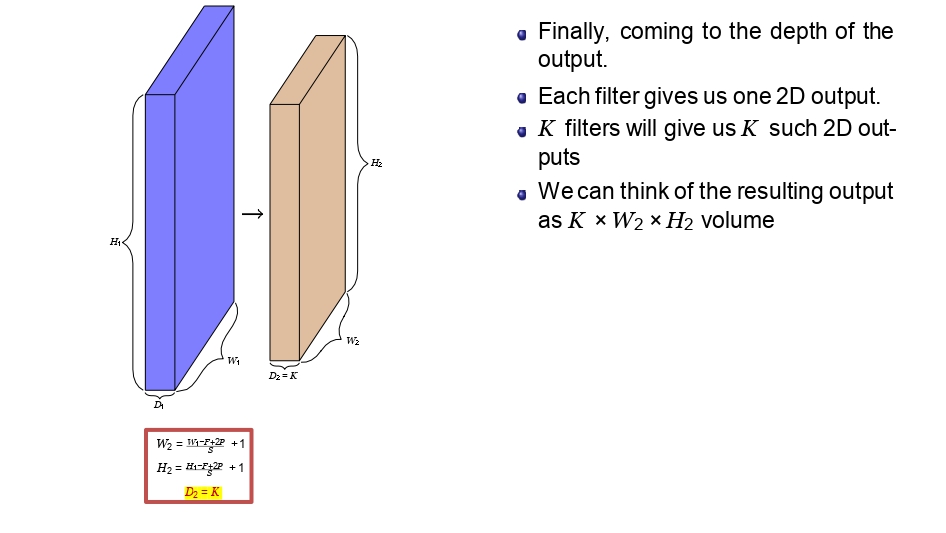
ليش المخرجات "مُكعب"؟
تذكرنا السلايدات بآخر قطعة في الأحجية:
- كل فلتر بيطلع لنا 2D Feature Map.
- إذا استخدمنا \(K\) من الفلاتر، رح نلاقي عندنا \(K\) من الطبقات فوق بعض.
✨ النتيجة: المخرج النهائي هو عبارة عن "حجم" (Volume) أبعاده هي \(W_2 \times H_2 \times K\).
- كل فلتر بيطلع لنا 2D Feature Map.
- إذا استخدمنا \(K\) من الفلاتر، رح نلاقي عندنا \(K\) من الطبقات فوق بعض.
✨ النتيجة: المخرج النهائي هو عبارة عن "حجم" (Volume) أبعاده هي \(W_2 \times H_2 \times K\).
PRACTICE LAB
تطبيق اللي تعلمته
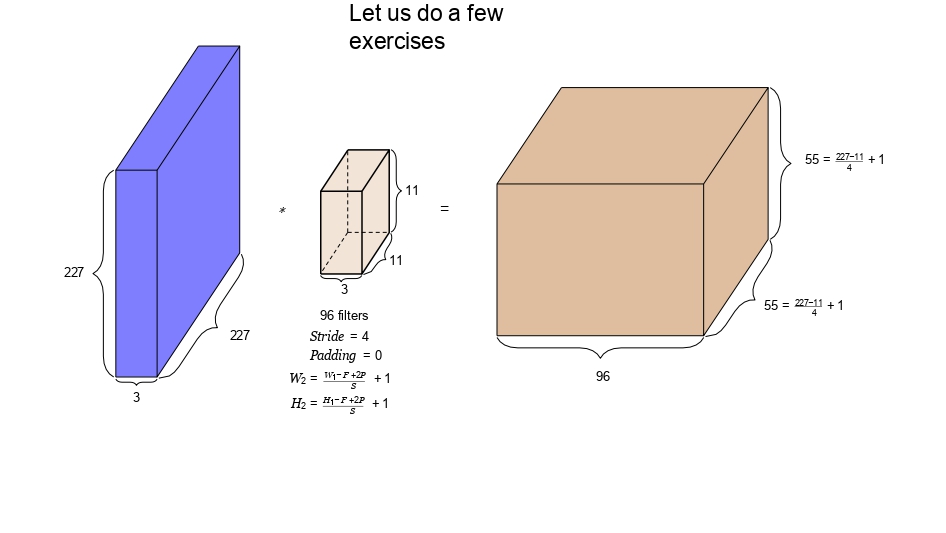
أولاً: مثال الـ AlexNet
في هاذ المثال، بدنا نحسب حجم مخرجات أول طبقة في شبكة مشهورة جداً. لاحظ إنه الصورة كبيرة والفلتر كمان حجمه كبير.
- 📐 حجم الصورة: 227x227x3
- 📐 حجم الفلتر: 11x11
- 🚀 القفزة (Stride): 4
- 📦 عدد الفلاتر (K): 96
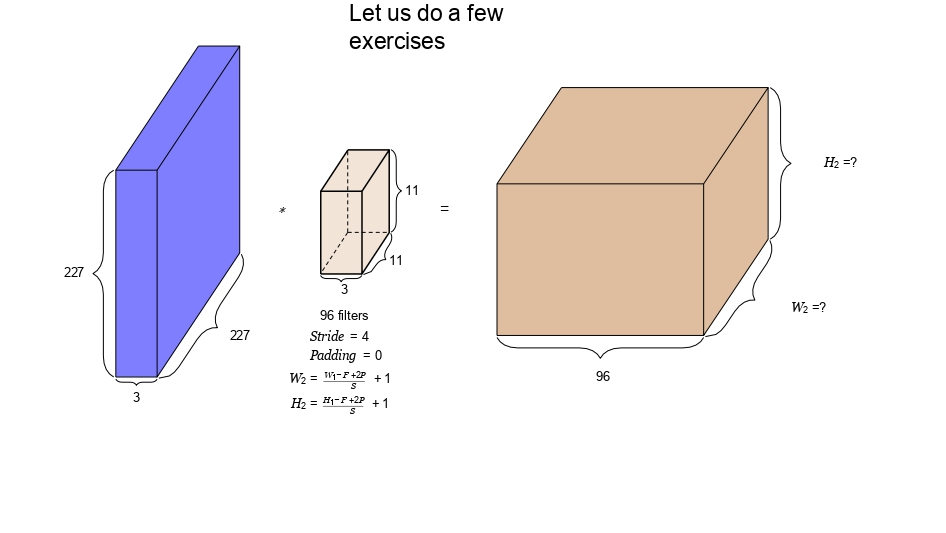
طريقة
الحساب:
1. بنحسب العرض والارتفاع للمخرج: \(W_2 = (227 - 11 + 0) / 4 + 1 = 55\)
2. العمق النهائي بساوي عدد الفلاتر اللي استخدمناها (\(K = 96\))
🎯 المخرج النهائي: 55x55x96
2. العمق النهائي بساوي عدد الفلاتر اللي استخدمناها (\(K = 96\))
🎯 المخرج النهائي: 55x55x96
ثانياً: مثال الـ Toy Example
هاذ المثال أبسط عشان نفهم المبدأ بدون أرقام كبيرة. هون الصورة (Grayscale) وعمقها واحد بس.
- 📐 حجم الصورة: 32x32x1
- 📐 حجم الفلتر: 5x5
- 🚀 القفزة (Stride): 1
- 📦 عدد الفلاتر (K): 6
طريقة
الحساب:
1. بنحسب المخرج: \(W_2 = (32 - 5 + 0) / 1 + 1 = 28\)
2. العمق هو دايماً الـ \(K\)، يعني \(6\)
🎯 المخرج النهائي: 28x28x6
2. العمق هو دايماً الـ \(K\)، يعني \(6\)
🎯 المخرج النهائي: 28x28x6
✏️ إختبر حالك: جرب تحلها!
لو عندنا صورة ومدخلات زي هيك.. شو بطلع حجم المخرج؟
🔹 Input: 7x7x3
🔹 Filter: 3x3
🔹 Stride: 1
🔹 Padding: 0
🔹 Filters (K): 2
🔹 Filter: 3x3
🔹 Stride: 1
🔹 Padding: 0
🔹 Filters (K): 2