

كيف نعرف إن المستخدم "راضي" عنّا؟ ❤️
تخيل يا كبير إنك فاتح محل أو عامل محرك بحث فخم، كيف بدك تعرف إذا الناس "راضيّة"
فعلاً عن اللي بتقدمه؟ مش بس إذا البرنامج شغال وموجود، لا!
بنقيس هاض الإشي بكم مؤشر أساسي:
بنقيس هاض الإشي بكم مؤشر أساسي:
1. الـ Relevance: هل النتائج اللي بطلعلها السيستم مرتبطة وبتلبي حاجة المستخدم؟ هاض هو التحدي الأول.
2. الـ Interaction: هل الناس بتضغط Click كثير؟ بس انتبه! مرات العناوين بتخدع ونسب النقرات لحالها
مش دايماً دليل رضا.
3. السلوك النهائي: هل المستخدم بشتري بعد ما يدور؟ هل
برجع يزورنا Repeat visitors؟ هاض هو الاختبار الحقيقي للنجاح.

شو "الميزان" اللي بنوزن فيه الـ Relevance؟ 🤔
عشان نقيس الـ Relevance صح، لازم يكون عندنا مختبر معياري ثابت فيه 3 قطع ذهبية:
⚠️ ملاحظة للامتحان: التقييم هون بكون Binary؛ يعني يا إما الملف مفيد (1) أو زبالة (0)!
1. Document Collection: مجموعة ملفات ثابتة الكل بجرب عليها
عشان نكون عادلين.
2. Suite of Queries: أسئلة محددة ومعروفة مسبقاً (ممنوع
نغيرها!).
3. Human Assessment: تقييم بشري بكون عارف شو الأسئلة
وشو الملفات المرتبطة فيها (Relevant).
⚠️ ملاحظة للامتحان: التقييم هون بكون Binary؛ يعني يا إما الملف مفيد (1) أو زبالة (0)!

الوحوش الاثنين: الـ Precision والـ
Recall 🏹
هون وصلنا للزبدة، كيف نحسب قوة السيستم بالأرقام؟
🏆 نصيحة قضاة: احفظ الجدول هاض زي اسمك (tp, fp, fn, tn). الـ tp يعني "جبت إشي صح وهو صح". الـ fp يعني "جبت إشي غلط". الـ fn يعني "ضيعت إشي كان لازم تجيبه".
🎯 Precision (الدقة): من بين كل الملفات اللي "رَجّعها" السيستم، كم واحد فعلاً طلع مفيد؟
القانون: P = tp / (tp + fp)
القانون: P = tp / (tp + fp)
🎣 Recall (الاسترجاع): من بين ملفات العالم المفيدة "الموجودة" أصلاً، السيستم كم واحد قدر يصيد؟
القانون: R = tp / (tp + fn)
القانون: R = tp / (tp + fn)
🏆 نصيحة قضاة: احفظ الجدول هاض زي اسمك (tp, fp, fn, tn). الـ tp يعني "جبت إشي صح وهو صح". الـ fp يعني "جبت إشي غلط". الـ fn يعني "ضيعت إشي كان لازم تجيبه".
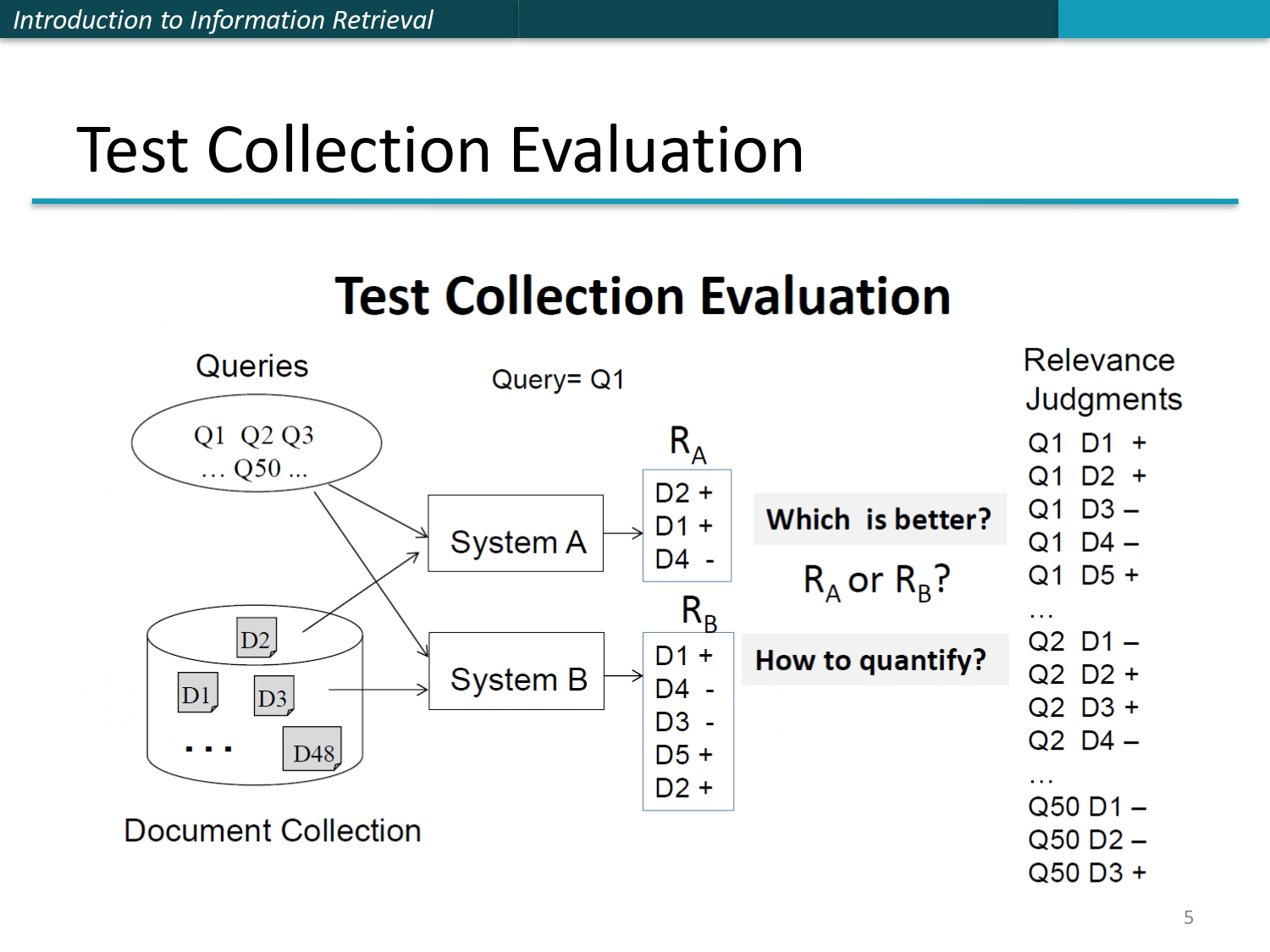
كيف بنقارن بين المحركات؟ 🏎️ 🏁
تخيل عندك محركين بحث System A و System B. كيف نعرف مين "الأقوى" بالميدان؟
بنطبق نظام الاختبار المعياري: بنجيب نفس الأسئلة ونفس الملفات وبنخليهم يشتغلوا. بعدها بنقارن النتائج بـ Relevance Judgments (اللي فيه + يعني صح، و - يعني غلط).
بنطبق نظام الاختبار المعياري: بنجيب نفس الأسئلة ونفس الملفات وبنخليهم يشتغلوا. بعدها بنقارن النتائج بـ Relevance Judgments (اللي فيه + يعني صح، و - يعني غلط).
الهدف من المقارنة: نعرف مين جاب أعلى دقة ومين كان ترتيبه أذكى. هيك بنقدر نقول بالأرقام مين السيستم اللي بيبيض الوجه
قدام المستخدمين.

المنافسة بالأرقام: مين اللي فاز؟ 📊
خلينا نحلل المثال هاض . عندنا سؤال (Q1)
بنعرف إنه اله 10 ملفات مفيدة بالداتا كلها.
الخلاصة: B جاب نتائج أكثر بس "خبص" أكتر، و A كان أدق بس "بخيل" بالنتائج.
System A: رجّع 3 ملفات، 2 منهم صح.
💡 Precision: 2/3 (دقة عالية).
💡 Recall: 2/10 (استرجاع ضعيف، ضيع 8 ملفات!).
💡 Precision: 2/3 (دقة عالية).
💡 Recall: 2/10 (استرجاع ضعيف، ضيع 8 ملفات!).
System B: رجّع 5 ملفات، 3 منهم صح.
💡 Precision: 3/5 (دقة أقل من A).
💡 Recall: 3/10 (استرجاع أحسن من A).
💡 Precision: 3/5 (دقة أقل من A).
💡 Recall: 3/10 (استرجاع أحسن من A).
الخلاصة: B جاب نتائج أكثر بس "خبص" أكتر، و A كان أدق بس "بخيل" بالنتائج.

القاعدة الذهبية: كفتي الميزان ⚖️
في عالم الـ IR، مستحيل (إلا بالمعجزات) تجيب 100% دقة و
100% استرجاع مع بعض.
الحالة المثالية: إنك تكون Precision = Recall = 1.0، بس بالحقيقة إحنا دايماً بنحاول نلاقي "نقطة توازن" تعجب المستخدم وتناسب نوع البحث تبعه.
💡 Trade-off: لما تحاول تزيد الـ Recall (يعني بدك تلم كل الملفات الصح)، غصب عنك رح تلم معهم "عفش"
وغلط، فبينزل الـ Precision.
الحالة المثالية: إنك تكون Precision = Recall = 1.0، بس بالحقيقة إحنا دايماً بنحاول نلاقي "نقطة توازن" تعجب المستخدم وتناسب نوع البحث تبعه.

الحل الوسط: الـ F-Measure 🔗
عشان ننهي الطوشة بين الدقة والاسترجاع، عملوا الـ F-measure.هاض
الوحش بدمج P و R برقم واحد.
ليش بنستخدم الـ (Weighted Harmonic Mean) مش المتوسط العادي؟ لأن المتوسط العادي ممكن يخدعنا! الـ Harmonic Mean بكون قاسي، فإذا واحد من المعايير كان (صفر)، النتيجة النهائية بتنخسف للأرض، وهاذ هو الصح تقنياً.
🌟 F1 Measure (The Balanced): هاض لما نعتبر إن الدقة
والاسترجاع متساويين بالأهمية (beta = 1).
ليش بنستخدم الـ (Weighted Harmonic Mean) مش المتوسط العادي؟ لأن المتوسط العادي ممكن يخدعنا! الـ Harmonic Mean بكون قاسي، فإذا واحد من المعايير كان (صفر)، النتيجة النهائية بتنخسف للأرض، وهاذ هو الصح تقنياً.

لعب بالأرقام: مين المهم عندك؟ 🎲
ركز هون لأنه هاذ السلايد "تكتيكي". لما نغير قيمة beta، بنقدر
نتحكم مين أهم:
الخلاصة للطلاب: فيس بوك وجوجل دايماً بلعبوا بهي الأرقام عشان يوازنوا بين إنهم يلموا كل شي وبين إنهم يعطوك نتائج نظيفة.
1️⃣ Beta = 2: يعني إنت مهتم بالـ Recall (الاسترجاع) أكثر. لاحظ كيف النتيجة نقصت (0.541) لأن
الـ Recall كان واطي (0.5).
2️⃣ Beta = 0.5: يعني إنت مهتم بالـ Precision (الدقة) أكثر. النتيجة طلعت عالية (0.714) لأن الدقة
كانت ممتازة (0.8).
الخلاصة للطلاب: فيس بوك وجوجل دايماً بلعبوا بهي الأرقام عشان يوازنوا بين إنهم يلموا كل شي وبين إنهم يعطوك نتائج نظيفة.

الخلاصة الذهبية 🏆
- 🎯 Precision: هل كل اللي جبته فعلاً مفيد؟ (نظافة النتائج).
- 🎣 Recall: هل قدرت تلم كل المفيد اللي بالمكتبة؟ (تغطية المحتوى).
- 🔗 F-measure: الجسر اللي بربطهم ببعض عشان يعطيك حكم نهائي.