تخيل حالك بتدور في أرشيف مكتبة فيها ملايين الكتب والملفات، وبدك تلاقي كلمة معينة، شو رح تعمل؟
قبل ما تصير المحركات ذكية وتفهم سياق الكلام، بدايات الـ Information Retrieval كانت بتعتمد على نظام منطقي
صارم. يا إما الكلمة موجودة، يا مش موجودة. هاض النظام اسمه Boolean Retrieval
Model.
في هاض الشابتر رح نتعرف على القصة من الصفر: كيف بنحول الكلمات لفهرس مقلوب (Inverted Index)، وكيف بنبحث
عن کلمة، وكيف بنحلل استعلام معقد مكون من AND و OR و NOT كأننا بنتعامل مع معادلات رياضيات!
نقطة البداية للمحركات الكبيرة 🌐

نموذج الاسترجاع المنطقي 📚
في هذا الشابتر رح نغوص بعمق في أقدم وأشهر نماذج البحث الكلاسيكية. رح نفهم حرفياً كيف الكمبيوتر
بيشوف الكلمات، وكيف بيقدر يجيبلك النتيجة من بين ملايين الملفات في أجزاء من الثانية!

التعريف والتطبيقات العملية 🔍
الـ Information Retrieval (IR) مش مجرد "بحث عن كلمات مبهمة". هو
عملية مدروسة مصممة عشان تلاقي "مواد" أو مستندات بتكون في الأغلب نصوص
غير منظمة (Unstructured)، بهدف إنها تلبي حاجة المستخدم من المعرفة من بين أكوام ضخمة
من البيانات.
تطبيقات من حياتنا:
- محركات البحث العالمية: مثل Google، واللي هي أشهر مثال على الويب.
- البحث في الإيميل: لما تدور على رسالة قديمة في الـ Gmail أو غيره.
- البحث الشخصي: لما تدور على ملف ضايع جوا اللابتوب تبعك بنظام الماك أو الويندوز.
- أنظمة الشركات: بحث الموظفين داخل وثائق ومستودعات المعرفة الخاصة بشركتهم.
- البحث القانوني: زي المحامين لما يدوروا على قضايا أو نصوص قانونية (مجال حساس جداً وبيحتاج دقة عالية).

الملعب اللي بنلعب فيه 🎯
قبل ما نصمم أي نظام بحث، لازم يكون عندنا افتراضات محددة تبسط المشكلة:
الـ Collection (أو الـ Corpus):
هاي هي "مجموعة المستندات" اللي النظام رح يبحث فيها. في هاي المرحلة الأولى، بنفترض إنها ثابتة (Static)؛ يعني ما في إضافة أو حذف لأي مستندات أثناء عملية البحث.
هاي هي "مجموعة المستندات" اللي النظام رح يبحث فيها. في هاي المرحلة الأولى، بنفترض إنها ثابتة (Static)؛ يعني ما في إضافة أو حذف لأي مستندات أثناء عملية البحث.
الهدف الحقيقي:
الهدف مش إنه النظام يلاقي الكلمة بشكل حرفي وبس! الهدف إنه يجيب للمستخدم مستندات "ذات صلة فعلية" (Relevant)، وتلبي حاجته، بحيث تساعد اليوزر يخلص "المهمة القائمة بين يديه" بنجاح.
الهدف مش إنه النظام يلاقي الكلمة بشكل حرفي وبس! الهدف إنه يجيب للمستخدم مستندات "ذات صلة فعلية" (Relevant)، وتلبي حاجته، بحيث تساعد اليوزر يخلص "المهمة القائمة بين يديه" بنجاح.

كيف بنحكم على المحرك؟ (الدقة والشمولية) ⚖️
عشان نحدد إذا كان نظام البحث بيشتغل بطريقة ممتازة ولا سيئة، بنعتمد على مقياسين خياليين بيشبهوا
كفتي الميزان:
الـ Precision (الدقة):
هو مقياس لـ "نظافة" النتائج، يعني من بين كل الملفات اللي النظام قدملك إياها، كم واحد منهم فعلاً مفيد إلك؟
💡 السؤال اللي بتجاوبه: "من بين الاشياء اللي رجعتلي، كم وحدة طلعت صحيحة؟"
هو مقياس لـ "نظافة" النتائج، يعني من بين كل الملفات اللي النظام قدملك إياها، كم واحد منهم فعلاً مفيد إلك؟
💡 السؤال اللي بتجاوبه: "من بين الاشياء اللي رجعتلي، كم وحدة طلعت صحيحة؟"
الـ Recall (الاستدعاء/الشمولية):
هو مقياس مكمل، بيقيس التغطية، يعني من بين "كل" الملفات الصح المفيدة اللي مخزنة جوا المكتبة أصلاً، كم قدر النظام يجيبلي منها؟
💡 السؤال اللي بتجاوبه: "من بين كل الملفات الصح الموجودة في الداتا، أنا قدرت الاقي كم واحد؟"
هو مقياس مكمل، بيقيس التغطية، يعني من بين "كل" الملفات الصح المفيدة اللي مخزنة جوا المكتبة أصلاً، كم قدر النظام يجيبلي منها؟
💡 السؤال اللي بتجاوبه: "من بين كل الملفات الصح الموجودة في الداتا، أنا قدرت الاقي كم واحد؟"

المصفوفات والبدايات 🚀
هون إحنا بندخل في صلب الموضوع. رح نتعرف على طريقة بدائية بس ذكية جداً عشان نمثّل وجود الكلمات
داخل الملفات، وهي باستخدام مصفوفة اسمها Term-document incidence
matrix.
الفكرة ببساطة إنه رح نعمل جدول، ونحط فيه أصفار وواحدات (0/1) عشان نعرف الكلمة موجودة ولا لأ!
الفكرة ببساطة إنه رح نعمل جدول، ونحط فيه أصفار وواحدات (0/1) عشان نعرف الكلمة موجودة ولا لأ!

كيف كنا نبحث زمان؟ 📜
بهاض السلايد بيسأل سؤال واقعي جابوه من أيام شكسبير: "أي مسرحية من مسرحيات شكسبير فيها كلمة Brutus وكمان كلمة Caesar بس ما فيها
كلمة Calpurnia؟"
الاستعلام بصيغة الداتا هو: Brutus AND Caesar NOT Calpurnia
الاستعلام بصيغة الداتا هو: Brutus AND Caesar NOT Calpurnia
طريقة البحث اليدوية (Grep):
زمان كنا ممكن نستخدم أمر الـ grep عشان نمشي على كل المسرحيات سطر سطر، وندور على الكلمتين الأولى والثانية، بعدين نحذف الأسطر اللي فيها الكلمة الثالثة.
زمان كنا ممكن نستخدم أمر الـ grep عشان نمشي على كل المسرحيات سطر سطر، وندور على الكلمتين الأولى والثانية، بعدين نحذف الأسطر اللي فيها الكلمة الثالثة.
ليش هاي الطريقة مش عملية؟
- بطيئة جداً (Slow): لو عندك قاعدة بيانات ضخمة (Large corpora) رح تاخذ سنين!
- ما بترتب لك النتائج (Ranked retrieval): يعني ما بتقدر تحكيلك مين أحسن ملف فيهم، هي بس بتجيبلك إذا الكلمة موجودة أو لا.

مصفوفة الكلمات والمستندات 📊
الحل السحري المبدئي كان في هذا الجدول! إحنا بنبني مصفوفة. تقاطع الكلمة مع المستند بيكون إما
1 أو 0.
كيف بنقرأ المصفوفة؟
- الصفوف (Rows): كل صف بيمثل كلمة (Term) مثل Antony, Caesar.
- الأعمدة (Columns): كل عمود بيمثل ملف أو مسرحية (Document).
- القيمة 1: معناها إنه الكلمة موجودة داخل هاي المسرحية.
- القيمة 0: معناها إنه الكلمة مش موجودة.
شو بنستفيد منها؟
هيك خلينا الكمبيوتر يخزن الملفات على شكل أرقام، وصار جاهز يطبق عليها العمليات المنطقية بسرعة خرافية!
هيك خلينا الكمبيوتر يخزن الملفات على شكل أرقام، وصار جاهز يطبق عليها العمليات المنطقية بسرعة خرافية!
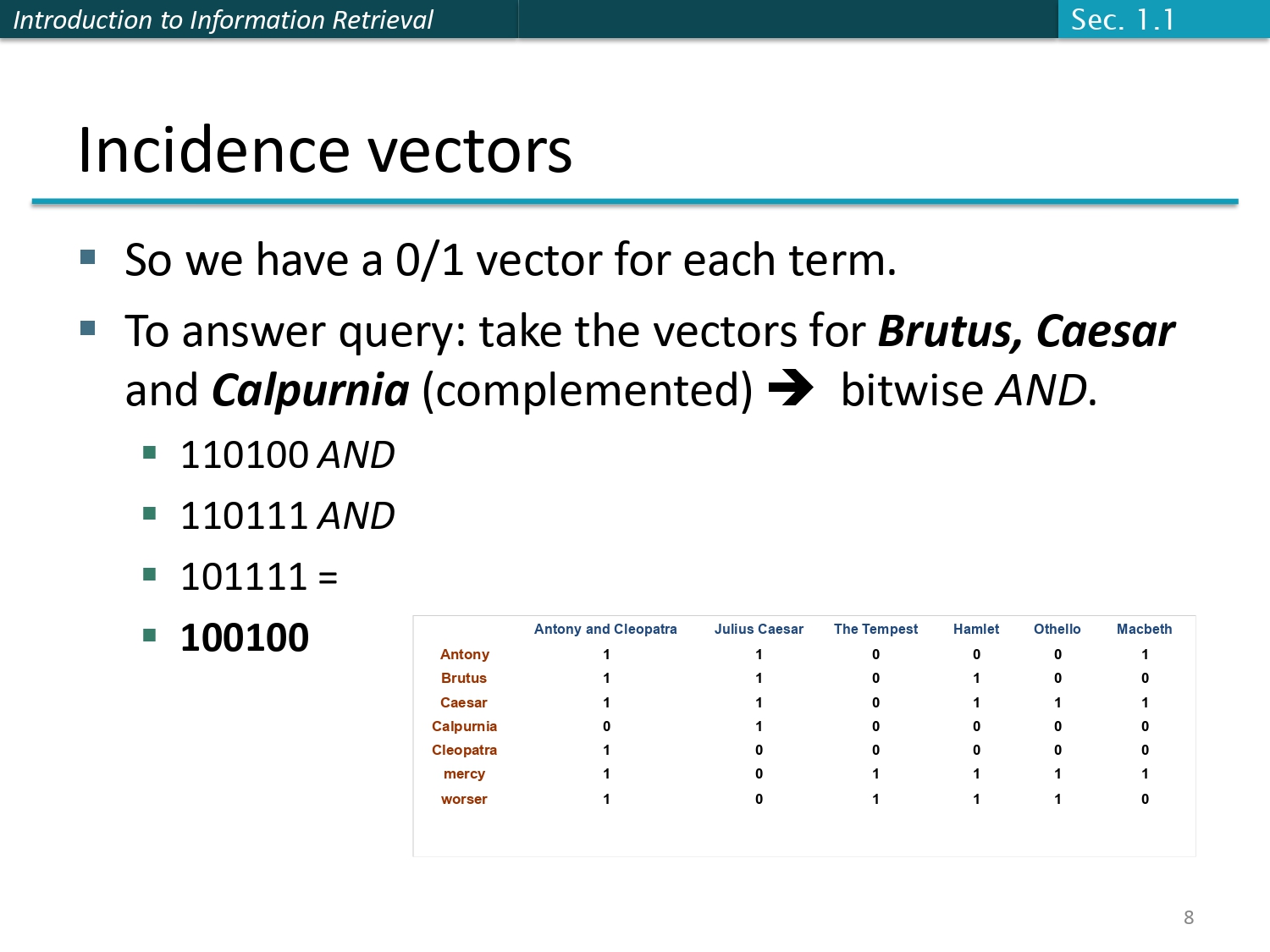
تطبيق الاستعلام باستخدام البتات ⚡
هسا اجا دور الرياضيات! الاستعلام تبعنا كان: Brutus AND Caesar BUT
NOT Calpurnia.
بما إننا حولنا الجدول لبتات (0 و 1)، صار لكل كلمة شعاع أو سطر كامل اسمه Vector.
بما إننا حولنا الجدول لبتات (0 و 1)، صار لكل كلمة شعاع أو سطر كامل اسمه Vector.
كيف بنحلها؟
نمسك الـ Vector تبع كلمة Brutus، والـ Vector تبع كلمة Caesar، ونعمللهم عملية المنطق AND (يعني متى بيكونوا الاثنين 1).
وبالنسبة لكلمة Calpurnia، لأننا ما بدنا إياها (NOT)، بنمسك الـ Vector تبعها وبنعكسه (نعملله Complement، الـ 1 بصير 0 والـ 0 بصير 1).
نمسك الـ Vector تبع كلمة Brutus، والـ Vector تبع كلمة Caesar، ونعمللهم عملية المنطق AND (يعني متى بيكونوا الاثنين 1).
وبالنسبة لكلمة Calpurnia، لأننا ما بدنا إياها (NOT)، بنمسك الـ Vector تبعها وبنعكسه (نعملله Complement، الـ 1 بصير 0 والـ 0 بصير 1).
النتيجة النهائية:
- لما نعمل Bitwise AND لكل هالأرقام: 110100 AND 110111 AND 101111
- الناتج بطلع: 100100
- وهاي الأرقام بتعادل المستند الأول (Antony and Cleopatra) والمستند الرابع (Hamlet) بناءً على ترتيب الأعمدة!
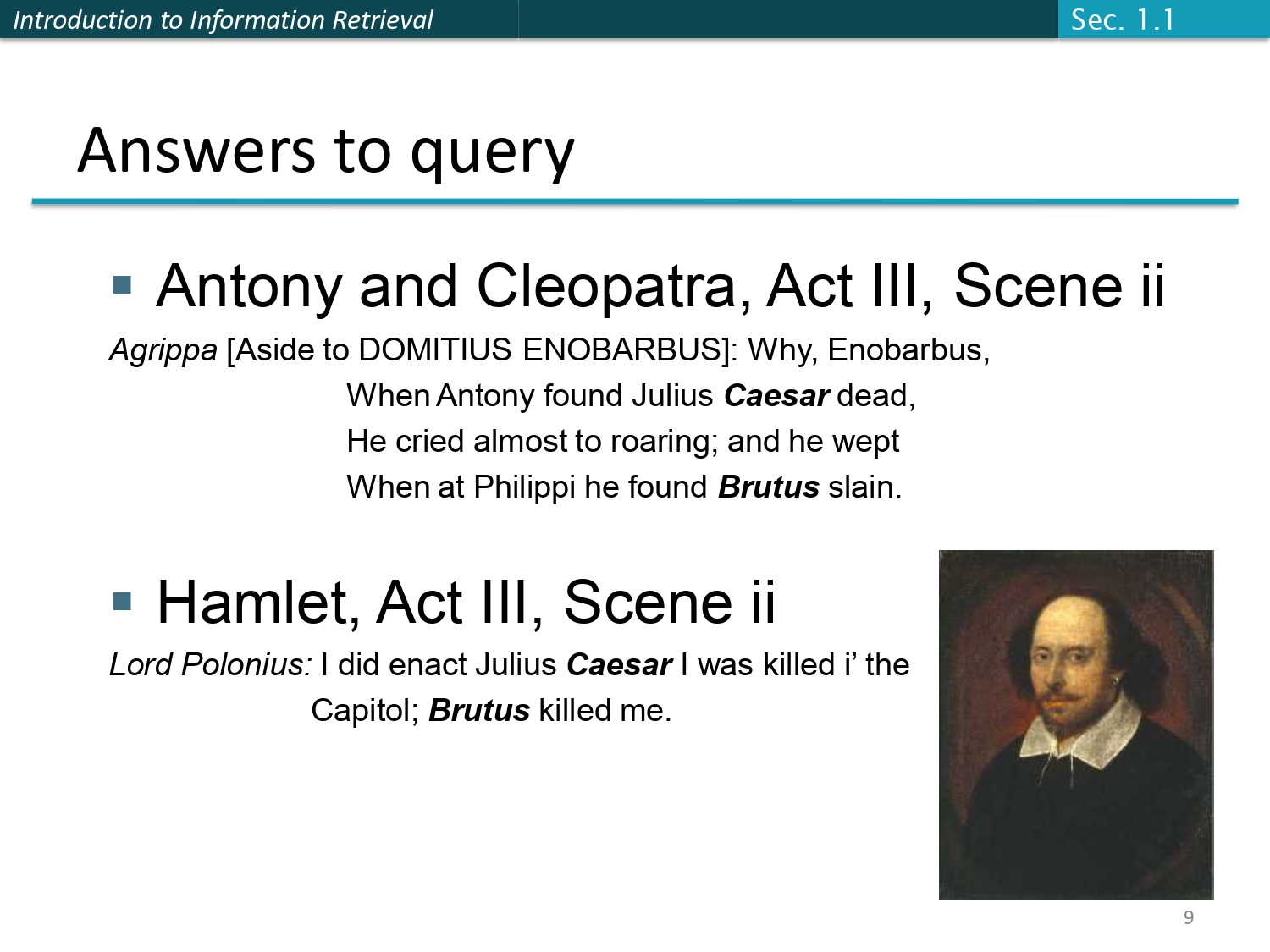
النتيجة النهائية للاستعلام 🎯
هون بالسلايد هاي بنشوف النتيجة الفعلية للبحث اللي عملناه! بعد ما حسبنا الـ Vectors وطلع معنا الناتج 100100،
الجهاز رجعلنا مسرحيتين فيهم الكلمات اللي بدنا إياها بدون الكلمة اللي استثنيناها!
النتائج اللي جابها النظام:
- مسرحية Antony and Cleopatra (المشهد الثاني): مبين في النص إنه بيحتوي على كلمة Caesar وكلمة Brutus.
- مسرحية Hamlet (المشهد الثاني): كمان هون الممثل بحكي عن Caesar و Brutus.
الخلاصة الممتعة:
الكمبيوتر ما بيقرأ القصة أو المسرحية، هو بشوف الملف على إنه عمود فيه (0/1)، وهيك عرف النتيجة بجزء من الثانية عن طريق عمليات حسابية بسيطة جداً زي الـ Bitwise AND!
الكمبيوتر ما بيقرأ القصة أو المسرحية، هو بشوف الملف على إنه عمود فيه (0/1)، وهيك عرف النتيجة بجزء من الثانية عن طريق عمليات حسابية بسيطة جداً زي الـ Bitwise AND!
المشكلة لما نكبر اللعبة 😱
في السلايدات الماضية فهمنا الفكرة العظيمة للمصفوفة وكيف بتبحث فيها وتطلع النتائج بسرعة خرافية..
لكن لحظة! شو بصير لو الداتا تبعتنا ضخمة جداً؟ Bigger collections.
تخيل هاض السيناريو الواقعي:
- عندنا مليون ملف (1 million documents).
- كل ملف فيه تقريباً 1000 كلمة.
- حجم الكلمة الواحدة مع الفراغات تقريباً 6 بايت.
- يعني المجموع حوالي 6 جيجابايت من البيانات النصية!
- واكتشفنا إنه عنا 500 ألف كلمة مميزة (Distinct terms) ما بتكرروا (يعني حجم القاموس تبعنا).
السؤال القوي:
هل فكرة الـ Term-document matrix لساتها بتزبط مع هالأرقام المخيفة؟ الجواب رح نشوفه بالسلايد الجاي!
هل فكرة الـ Term-document matrix لساتها بتزبط مع هالأرقام المخيفة؟ الجواب رح نشوفه بالسلايد الجاي!

المصفوفة بتنهار! ليش؟ 💥
السؤال اللي سألناه في السلايد الماضي جوابه ببساطة: Can't build the
matrix! ما بنقدر نبني المصفوفة بهاي الحالة، ليش؟
حسبة بسيطة بتصدمك:
المصفوفة حجمها بيساوي عدد الكلمات ضرب عدد الملفات. يعني 500 ألف ضرب مليون = نص تريليون خلية (Half-a-trillion) فيها أصفار وواحدات. يعني حجم ضخم جداً عالفاضي!
المصفوفة حجمها بيساوي عدد الكلمات ضرب عدد الملفات. يعني 500 ألف ضرب مليون = نص تريليون خلية (Half-a-trillion) فيها أصفار وواحدات. يعني حجم ضخم جداً عالفاضي!
المشكلة الكبيرة (الخلايا الفاضية):
اكتشفنا إنه من بين هالنص تريليون خلية، بس "مليار" خلية بالكثر رح يكون فيها الرقم 1، والباقي كله أصفار! لأن الكلمة مستحيل تكون موجودة في كل الملفات. هاي الحالة بنسميها بالداتا Extremely sparse matrix (يعني مصفوفة مليانة فراغات وأصفار).
اكتشفنا إنه من بين هالنص تريليون خلية، بس "مليار" خلية بالكثر رح يكون فيها الرقم 1، والباقي كله أصفار! لأن الكلمة مستحيل تكون موجودة في كل الملفات. هاي الحالة بنسميها بالداتا Extremely sparse matrix (يعني مصفوفة مليانة فراغات وأصفار).
الحل البديل:
بدال ما نخزن كل الأصفار اللي بتوخذ مساحة على الفاضي، ليش ما نخزن بس أماكن الواحدات (1 positions)؟ وهاض اللي رح يعطينا اختراع جديد رح يغير شكل البحث في السلايد الجاي!
بدال ما نخزن كل الأصفار اللي بتوخذ مساحة على الفاضي، ليش ما نخزن بس أماكن الواحدات (1 positions)؟ وهاض اللي رح يعطينا اختراع جديد رح يغير شكل البحث في السلايد الجاي!

الأرقام بتحكي: ولادة الـ Inverted Index 🌟
بهاض السلايد الدكتور قاعد بثبتلنا بالأرقام ليش المصفوفة مش حل منطقي أبداً. خلينا نحسبها حبة حبة:
إثبات إنه الأصفار أكلت المصفوفة:
- عنّا مليون ملف، وكل ملف فيه 1000 كلمة بالكثر.
- هذا بيعني إنه أقصى عدد من الواحدات (1s) الممكن في المصفوفة هو 1,000,000 × 1,000 = 1 مليار واحد فقط!
النسبة الصادمة:
لما نقسم المليار واحد، على الحجم الكلي للمصفوفة اللي هو نص تريليون (500 مليار)، بيطلع الجواب 0.002.
هذا معناه إنه 99.8% من مصفوفتنا عبارة عن أصفار لا فائدة منها!
لما نقسم المليار واحد، على الحجم الكلي للمصفوفة اللي هو نص تريليون (500 مليار)، بيطلع الجواب 0.002.
هذا معناه إنه 99.8% من مصفوفتنا عبارة عن أصفار لا فائدة منها!
الخلاصة والحل السحري:
بدال ما نضيع المساحة بتخزين الأصفار (we store only the positions of the 1's)، بنخزن فقط وين موجودة الكلمة! وهاي الفكرة هي قلب محركات البحث، واسمها Inverted Index (الفهرس المقلوب).
بدال ما نضيع المساحة بتخزين الأصفار (we store only the positions of the 1's)، بنخزن فقط وين موجودة الكلمة! وهاي الفكرة هي قلب محركات البحث، واسمها Inverted Index (الفهرس المقلوب).

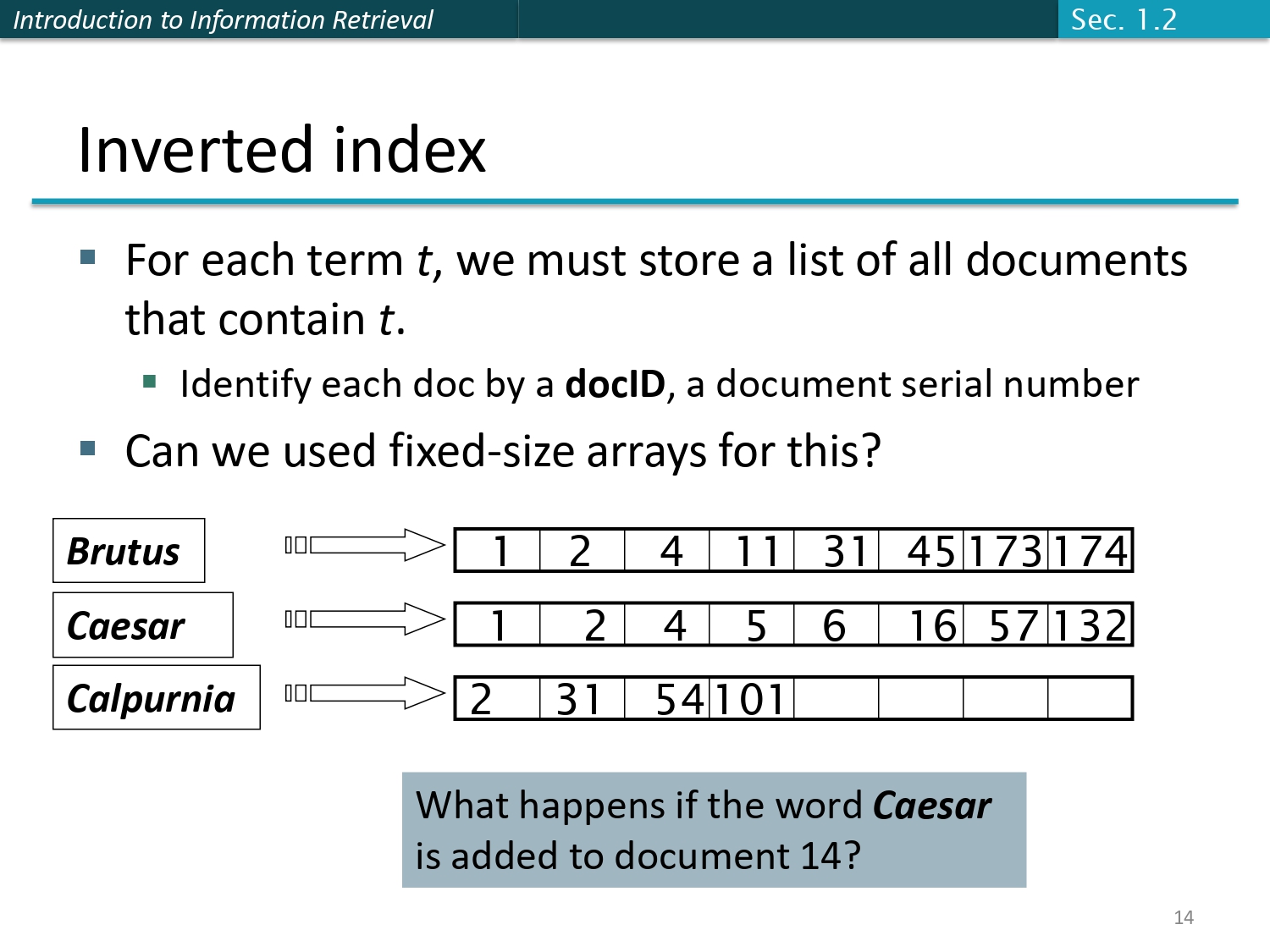
كيف بيشتغل الفهرس المقلوب؟ ⚙️
الفكرة ببساطة: بدل ما نعمل جدول ونحط أصفار وواحدات، بنعمل "قاموس" فيه كل الكلمات وكل كلمة جمبها
لستة بالأرقام تبعت المستندات اللي بتظهر فيها. يعني كل كلمة بنعطيها docID وهو رقم تسلسلي بيشير للمستند.
سؤال للذكاء: بنقدر نستخدم مصفوفة حجمها ثابت (Fixed-size
arrays)؟
تخيل لو حجزنا لكل كلمة مصفوفة حجمها 1000.. شو بصير لو الكلمة (زي Caesar) ضفناها لملف جديد مش من ضمن الـ 1000؟ الجواب لا طبعاً، مش عملي! لازم المصفوفة تكون مرنة وتكبر براحتها.
تخيل لو حجزنا لكل كلمة مصفوفة حجمها 1000.. شو بصير لو الكلمة (زي Caesar) ضفناها لملف جديد مش من ضمن الـ 1000؟ الجواب لا طبعاً، مش عملي! لازم المصفوفة تكون مرنة وتكبر براحتها.

القاموس وقوائم النشر (Postings List) 🔗
بما إنه حجم المصفوفة الثابت ما زبط معنا، الحل هو Variable-size postings
lists (قوائم متغيرة الحجم).
مكونات الـ Inverted Index:
- القاموس (Dictionary): هو المكان اللي بنخزن فيه الكلمة نفسها (مثل Brutus)، وبيكون بالعادة مرتب ويؤشر على اللستة.
- قوائم النشر (Postings): هاي اللستة اللي جواها أرقام الملفات (docIDs)، ولازم دايماً تكون مرتبة تصاعدياً! (رح نعرف فايدة الترتيب بعدين).
وين بنخزنها؟
لما نكون بالهارد ديسك (On disk) يفضل نخزنها كقطعة وحدة متصلة. بس لما نكون بالرام (In memory) بنستخدم Linked lists عشان نقدر نضيف الملفات بسرعة وسهولة وبدون ما نستهلك مساحة زيادة.
لما نكون بالهارد ديسك (On disk) يفضل نخزنها كقطعة وحدة متصلة. بس لما نكون بالرام (In memory) بنستخدم Linked lists عشان نقدر نضيف الملفات بسرعة وسهولة وبدون ما نستهلك مساحة زيادة.
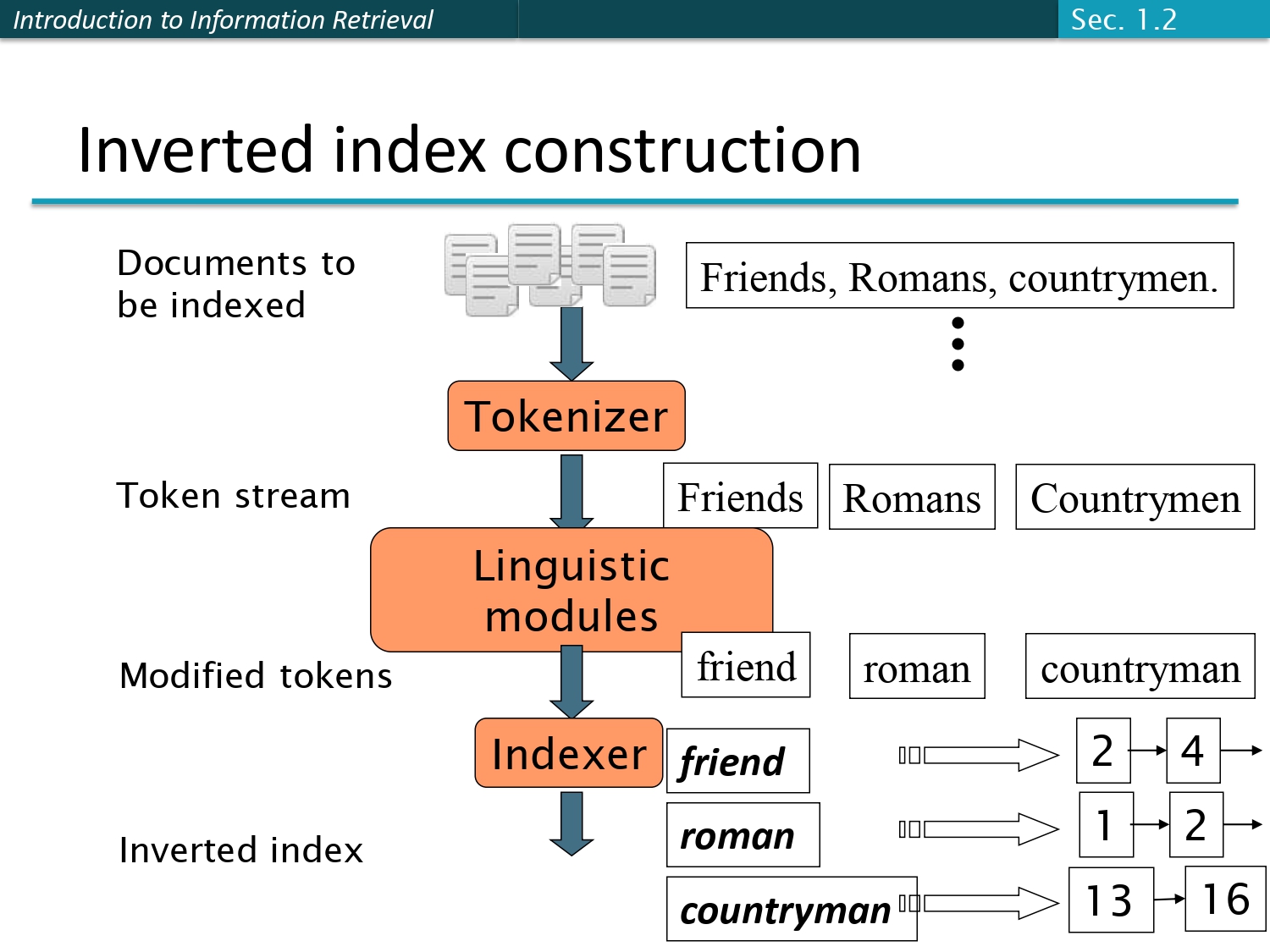
رحلة بناء الفهرس (Index Construction) 🏭
طيب كيف بنبني هالفهرس الحلو هاض؟ السلايد بوضح الشغل كأنه مصنع، وهاي خطواته:
خطوات المصنع بالترتيب:
- 1. المستندات (Documents): بتدخل النصوص الخام زي ما هي.
- 2. التقطيع (Tokenizer): بنقطع النص لكلمات لحالها فبصير عنّا (Token stream).
- 3. المعالجة اللغوية (Linguistic modules): هون بنظف الكلمات! مثلاً كلمة Friends بتصير friend، وكلمة Romans بتصير roman (عشان نرجعها لأصلها).
- 4. البناء (Indexer): أخيرًا! كل كلمة بتترتب وبتنعمللها الـ Postings list الخاصة فيها.

تفاصيل التنظيف اللغوي (Text Processing) 🧼
عشان الفهرس تبعنا يكون ذكي وما يكرر كلام عالفاضي، في 4 عمليات مهمة للنص قبل ما يتخزن:
العمليات الأربعة:
- 1. التقطيع (Tokenization): بنقصقص الجملة لكلمات وبنفصلهم.
- 2. التوحيد (Normalization): بنخلي الكلمات اللي بتشبه بعض باللفظ أو المعنى تصير كلمة وحدة. يعني إذا واحد بحث عن U.S.A. والثاني USA بنخليهم يتطابقوا!
- 3. التجذير (Stemming): بنقص الزيادات عن الكلمة عشان نرجعها لجذرها. يعني كلمات زي authorize و authorization بيصيروا كلمة وحدة وبنقيس عليهم كل الإشتقاقات.
- 4. إزالة الكلمات الشائعة (Stop words): في كلمات ما إلها معنى مؤثر بالبحث مثل (the, a, to, of)، ممكن نحذفهم عشان نوفر مساحة (أو نخليهم، بيعتمد على قوة النظام).
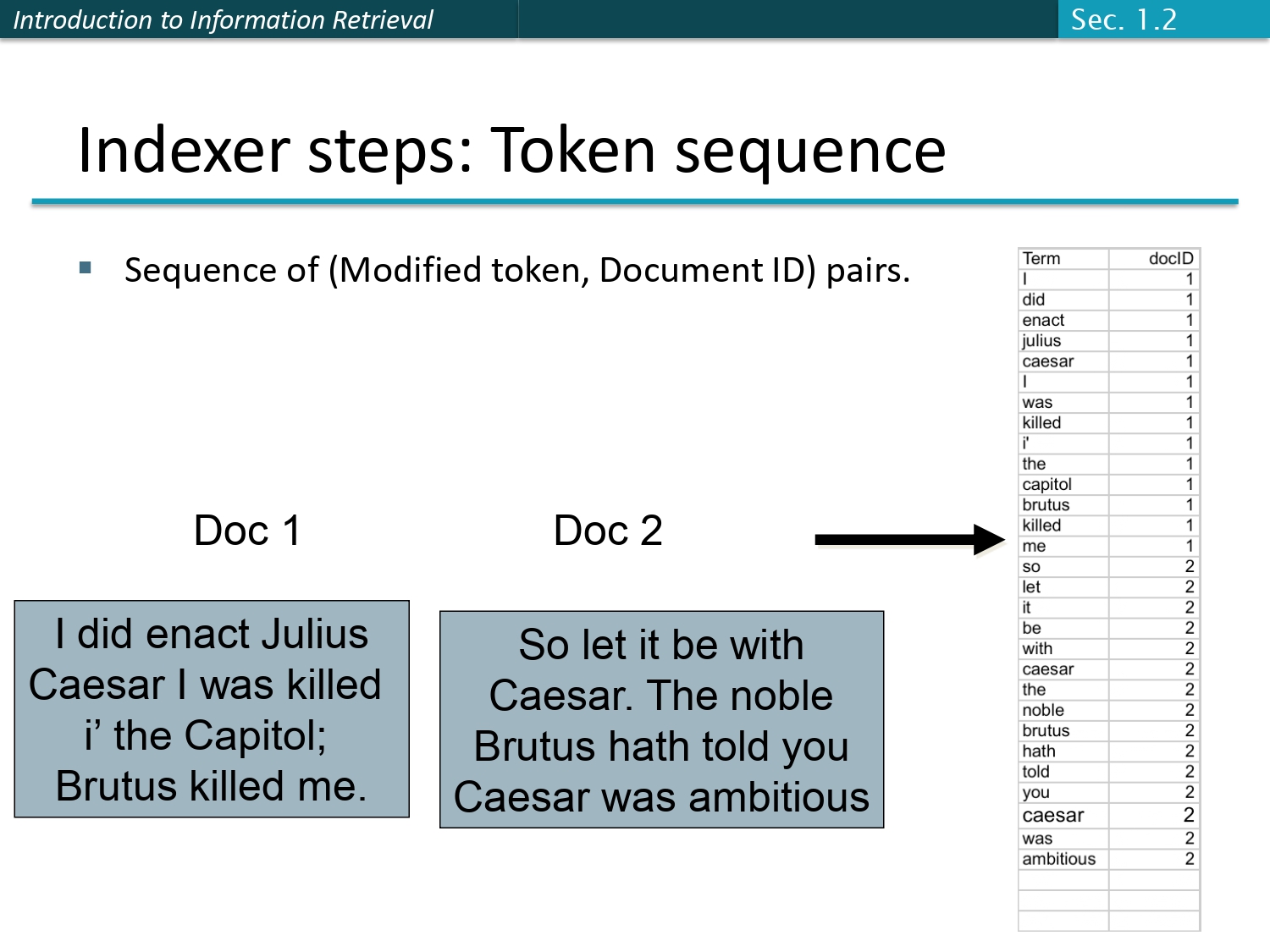
خطوة 1: تسلسل الكلمات (Token sequence) 📜
في السلايد هذا بنشوف أول خطوة عملية لبناء الفهرس. تخيل عندنا ملفين (Doc 1 و Doc 2).
شو اللي بصير بالضبط؟
النظام بيقرأ الملفات كلمة كلمة بالترتيب، وكل كلمة بيلاقيها بحطها بجدول وجنبها رقم الملف اللي ظهرت فيه (يعني (Modified token, Document ID) pairs).
لاحظ إن الكلمات في الجدول على اليمين مش مرتبة أبجدياً، هي مرتبة حسب ظهورها بالنص! وكمان الكلمات تم تنظيفها (كلها أحرف صغيرة).
النظام بيقرأ الملفات كلمة كلمة بالترتيب، وكل كلمة بيلاقيها بحطها بجدول وجنبها رقم الملف اللي ظهرت فيه (يعني (Modified token, Document ID) pairs).
لاحظ إن الكلمات في الجدول على اليمين مش مرتبة أبجدياً، هي مرتبة حسب ظهورها بالنص! وكمان الكلمات تم تنظيفها (كلها أحرف صغيرة).

خطوة 2: الفرز (Sort) 🔄
هاي هي الخطوة الجوهرية (Core indexing step)! بعد ما استخرجنا
الكلمات وصارت بجدول حايص وبايص، لازم نرتبهم.
كيف بنرتب؟
- أولاً: بنرتب كل الجدول بناءً على الكلمة ألفبائياً (Sort by terms). عشان هيك حتلاقي حرف a بالسطر الأول.
- ثانياً: إذا الكلمة تكررت (زي كلمة caesar)، بنرتبها داخلياً حسب رقم الملف اللي ظهرت فيه (And then docID).

خطوة 3: التجميع وفصل الفهرس (Dictionary & Postings) 🧩
هون بندخل بمرحلة النظافة النهائية. بما إنه الكلمات ترتبت، هسا صار وقت ندمج المكرر ونفصل الجدول
لقسمين.
التغييرات اللي صارت:
- دمج التكرار: لو كلمة (brutus) مثلاً ظهرت مرتين في Doc 1، ما بنحط رقم 1 مرتين في اللستة، بندمجهم (Multiple term entries ... are merged).
- الفصل السحري: الجدول انقسم لـ Dictionary (القاموس اللي فيه الكلمات) و Postings lists (القوائم اللي فيها أرقام الملفات زي السهم اللي طالع).
- إضافة معلومة جديدة: ضفنا عامود اسمه Document Frequency (doc. freq.). وهاض بحكيلنا "في كم ملف رئيسي ظهرت هاي الكلمة؟". (ليش ضفناه؟ الدكتور رح يشرحلنا أهميته بعدين!).
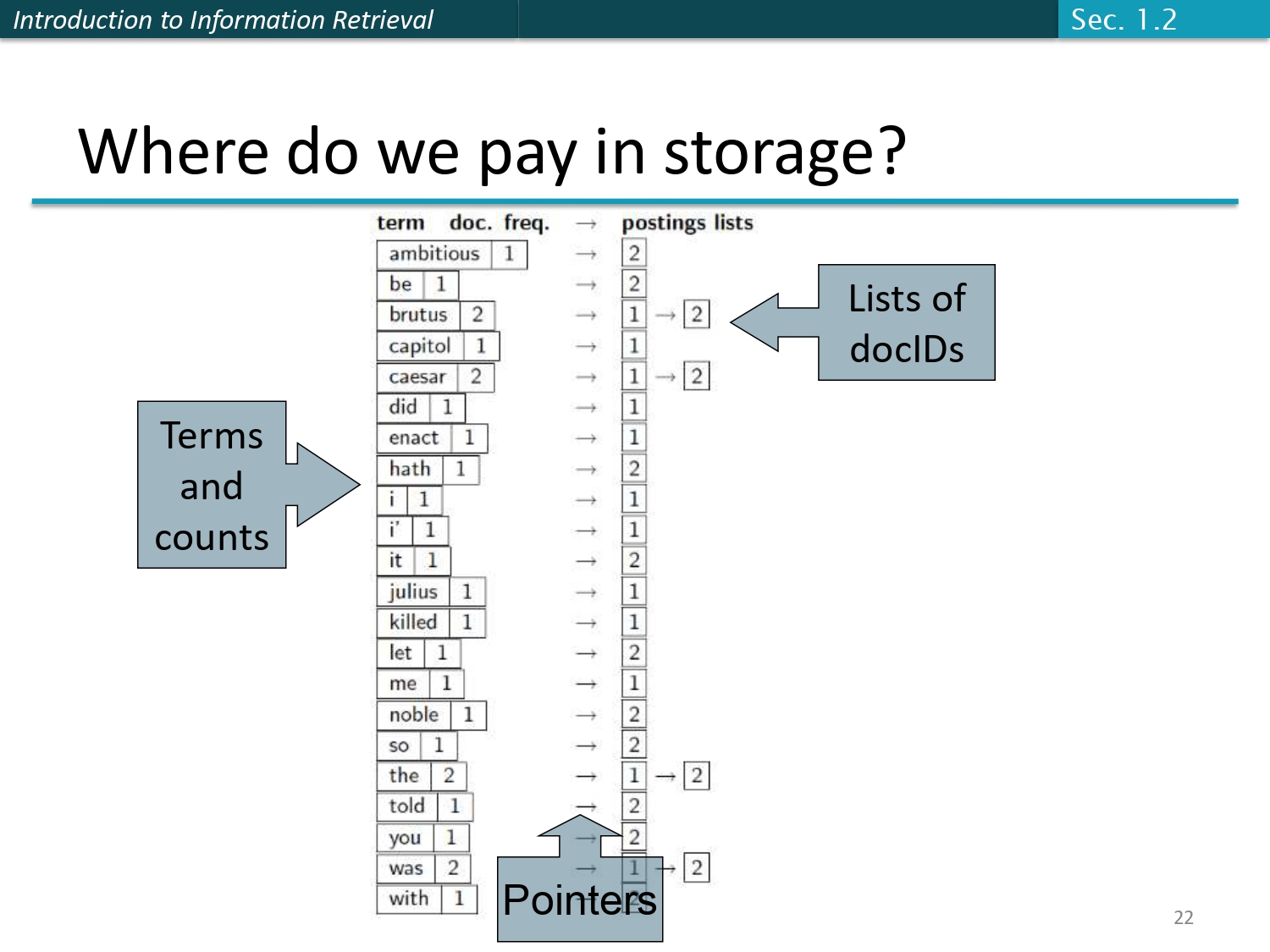
نظرة هندسية (أين ندفع الثمن المساحي؟) 💰
بهاض السلايد الدكتور بيسألنا سؤال عن مساحة التخزين (Where do we pay in
storage?). لما نبني الفهرس، وين أكثر مكان بيسحب مساحة؟
الجواب بالتفصيل:
- تخزين القاموس (Terms and counts): بنحتاج مساحة لتخزين الكلمات وأرقام التكرار، وهاض بالعادة بيكون صغير نسبياً (لأن عدد الكلمات الممكنة في اللغة محدود).
- تخزين المؤشرات (Pointers): الأسهم اللي بتوديك من الكلمة للستة الخاصة فيها بتاخذ مساحة من الرام/الهارد.
- حجم الكارثة الحقيقية (Lists of docIDs): التكلفة الأكبر بالتخزين بتروح في قوائم النشر نفسها! تخيل كلمة زي "the" ممكن يكون جنبها لستة فيها 10 مليون رقم لملف!

مرحلة معالجة الاستعلامات (Query processing) 🔍

عملية التقاطع بين كلمتين (AND) 🔗
هسا بدنا نبحث عن كلمتين مع بعض: `Brutus AND Caesar`!
الخطوات الثلاثة البسيطة:
- أول خطوة: بنروح على القاموس، بندور على كلمة Brutus، وبنسحب اللستة تبعتها.
- ثاني خطوة: بندور على كلمة Caesar بالقاموس، وبنسحب اللستة تبعتها كمان.
- الخطوة الذهبية: بنعمل عملية Merge أو تقاطع (Intersect) للستتين عشان نلاقي الملفات المشتركة، واللي في الرسمة طلعت معنا (2, 8).

سرّ السرعة في الـ Merge ⚡
عملية الـ Merge (التقاطع) مش عشوائية ولا بتوخذ وقت عبثي، في شرط جوهري عشان تكون سريعة جداً
وتشتغل بوقت خطي (Linear time).
الشرط الأساسي:
لازم القوائم تكون مرتبة! (Sorted by docID). وهون عرفنا ليش رتبناهم في السلايدات الماضية.
إذا كانت اللستة الأولى طولها X والثانية طولها Y، فالعملية رح تاخذ بالأسوأ وقت O(X+Y)، يعني بنمشي عليهم مرة وحدة بس!
لازم القوائم تكون مرتبة! (Sorted by docID). وهون عرفنا ليش رتبناهم في السلايدات الماضية.
إذا كانت اللستة الأولى طولها X والثانية طولها Y، فالعملية رح تاخذ بالأسوأ وقت O(X+Y)، يعني بنمشي عليهم مرة وحدة بس!

خطوات جاهزة للتطبيق 📝
هون الدكتور بيلخص الخطوات الستة اللي بنعملها لما نطبق استعلام "AND" بشكل مرتب:
الملخص السريع:
1. بنلاقي الكلمة الأولى بالقاموس.
2. بنسحب قائمتها.
3. بنلاقي الكلمة الثانية بالقاموس.
4. بنسحب قائمتها.
5. بنقاطع القائمتين مع بعض (Intersect).
6. بنرجع النتيجة للمستخدم!
1. بنلاقي الكلمة الأولى بالقاموس.
2. بنسحب قائمتها.
3. بنلاقي الكلمة الثانية بالقاموس.
4. بنسحب قائمتها.
5. بنقاطع القائمتين مع بعض (Intersect).
6. بنرجع النتيجة للمستخدم!

خوارزمية التقاطع (Intersection Algorithm) ⚙️
كيف السحر بصير من جوا؟ البرنامج كيف بيعرف يقاطع القوائم بهاي الكفاءة؟ الفكرة المليونية هي
باستخدام "المؤشرات" (Two pointers).
كيف اللعبة بتشتغل؟
- بنحط مؤشر أول على بداية اللستة (p1) ومؤشر ثاني على بداية (p2).
- إذا الأرقام تطابقت (Match): بنضيف الرقم لجوابنا وبنمشي المؤشرين الثنين خطوة لقدام.
- إذا الأرقام مش متساوية: بنحرك المؤشر اللي رقمه أصغر (Smaller) خطوة لقدام لحاله، وبنضل نعيد لتخلص وحدة من اللستتين.

الكود الفعلي لعملية التقاطع 💻
هاض السلايد هو ترجمة لكلامنا بالسلايد الماضي بس على شكل كود (Pseudo-code) لخوارزمية دمج قائمتين.
فك الكود بسرعة:
- السطر 2: حلقة
whileبتتأكد إنه لسه ما وصلنا لنهاية اللستتين (NIL أو Null). - السطر 3 و 4: إذا المؤشرين متساويين بضيف الرقم للـ answer.
- السطر 7 و 8: هون شرط التحريك الأهم! إذا p1 أصغر من p2، بنحرك p1. غير هيك بنحرك p2، وبس!

تتبع ومثال عملي ✏️
عشان الفكرة تثبت خرسانة، هاض جدول تتبع (Trace) للخوارزمية اللي فوق
خطوة بخطوة!
نفهم كيف تتبع الجدول:
عنا قائمتين: p1 بتبدأ من 1، و p2 بتبدأ من 2:
عنا قائمتين: p1 بتبدأ من 1، و p2 بتبدأ من 2:
- الخطوة 1: بنقارن 1 مع 2. الواحد أصغر؟ بنحرك p1.
- الخطوة 2: بنقارن 3 مع 2. الاثنين أصغر؟ بنحرك p2.
- الخطوة 3: بنقارن 3 مع 3. تطابق (Match)! هههه ضفنا رقم 3 للنتيجة وحركنا المؤشرين معاً (Move both).


شو يعني البولين بالضبط؟ 🤔
نموذج البولين (Boolean Retrieval Model) هو ببساطة: بنبحث باستخدام
تعابير منطقية (Boolean Expressions) فيها AND و OR و NOT.
ميزاته وخصائصه:
- كل مستند بنشوفه كمجموعة كلمات (Set of words)، مش بنشوف تكرارها.
- الجواب دايماً واضح (Precise): إما المستند ينجح في الشرط أو لأ، ما في وسط!
- هو أبسط نموذج ممكن في الـ IR.
- كان الأداة الرئيسية لمحركات البحث التجارية لمدة 3 عقود!
- ولسه مستخدم حتى اليوم بأشياء زي البريد الإلكتروني، macOS Spotlight وأنظمة المكتبات!

حين بنتشبك بالدمج بشكل أكثر تعقيداً 🤯
في السلايد السابقة كنا بنقاطع كلمتين (AND)، بس شو بصير لو الاستعلام فيه تشكيلة أكثر تعقيداً مثل
Brutus AND NOT Caesar أو Brutus
OR NOT Caesar؟
كلمة مفتاح:
- الـ AND: بيشتغل على مبدأ التقاطع (Intersection).
- الـ OR: بيشتغل على مبدأ الاتحاد (Union).
- الـ NOT: بيشتغل على مبدأ المتمم (Complement)، يعني كل شي إلا هاي الكلمة.

مثال واقعي بثلاث عمليات: (Brutus OR Caesar) AND NOT Calpurnia 📚
هسا وصلنا لسؤال ممتاز: احسب المستندات اللي فيها بروتس أو قيصر، بس مش كالبورنيا!
البيانات اللي عنا:
- Brutus → {1, 2, 4, 5, 8}
- Caesar → {2, 3, 5, 6, 8, 9}
- Calpurnia → {2, 8, 10}
- All Documents → {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}

خطوة 1: أحسب OR (Brutus OR Caesar = Union) 🔗
أول خطوة في حل الاستعلام هي حساب اتحاد قائمتي Brutus و Caesar (Union).
الحساب:
Brutus = {1, 2, 4, 5, 8}
Caesar = {2, 3, 5, 6, 8, 9}
Brutus OR Caesar = {1, 2, 3, 4, 5, 6, 8, 9}
(كل الأرقام من اللستتين مجتمعة، بدون تكرار)
Brutus = {1, 2, 4, 5, 8}
Caesar = {2, 3, 5, 6, 8, 9}
Brutus OR Caesar = {1, 2, 3, 4, 5, 6, 8, 9}
(كل الأرقام من اللستتين مجتمعة، بدون تكرار)

خط؈ 2 و 3: المتمم (NOT) ثم التقاطع (AND) 🎯
بعد ما حسبنا الـ OR بالخطوة السابقة، هسا نكمل المثال بخطوتين إضافيتين.
خطوة 2: احسب NOT Calpurnia (المتمم):
All Documents = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
Calpurnia = {2, 8, 10}
NOT Calpurnia = {1, 3, 4, 5, 6, 7, 9}
All Documents = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
Calpurnia = {2, 8, 10}
NOT Calpurnia = {1, 3, 4, 5, 6, 7, 9}
خطوة 3: قاطع النتيجتين (AND = Intersection):
Brutus OR Caesar = {1, 2, 3, 4, 5, 6, 8, 9}
NOT Calpurnia = {1, 3, 4, 5, 6, 7, 9}
النتيجة النهائية = {1, 3, 4, 5, 6, 9} ✅
Brutus OR Caesar = {1, 2, 3, 4, 5, 6, 8, 9}
NOT Calpurnia = {1, 3, 4, 5, 6, 7, 9}
النتيجة النهائية = {1, 3, 4, 5, 6, 9} ✅

جواب السؤال: هل AND و OR و NOT كلهم O(x+y)؟ �
الدكتور سأل بالمحاضرة: لو الاستعلام معقد زي (Brutus OR Caesar) AND
NOT (Antony OR Cleopatra)، هل بنقدر نعمل كل العمليات بنفس الكفاءة؟
✅ AND → O(x+y) ممكن
بنستخدم خوارزمية المؤشرين (Two Pointers) اللي شرحناها. بنمشي على القائمتين معاً مرة وحدة بس. كفء جداً!
بنستخدم خوارزمية المؤشرين (Two Pointers) اللي شرحناها. بنمشي على القائمتين معاً مرة وحدة بس. كفء جداً!
✅ OR → O(x+y) ممكن
نفس فكرة المؤشرين، بس بدل ما نتقاطع، بنجمع (Union). أي رقم يجينا من أي قائمة بنضيفه، وبنحرك المؤشر الأصغر.
نفس فكرة المؤشرين، بس بدل ما نتقاطع، بنجمع (Union). أي رقم يجينا من أي قائمة بنضيفه، وبنحرك المؤشر الأصغر.
⚠️ NOT → المشكلة! O(N)
هون المشكلة الحقيقية! NOT Calpurnia يعني "كل الملفات اللي مش فيها Calpurnia"، يعني لازم تمشي على قائمة كل الملفات الموجودة وتطرح منها قائمة Calpurnia.
هاض بيكلفنا O(N) حيث N =عدد كل الملفات بالمجموعة، وهاض مكلف جداً لو عندك مليارات ملف!
هون المشكلة الحقيقية! NOT Calpurnia يعني "كل الملفات اللي مش فيها Calpurnia"، يعني لازم تمشي على قائمة كل الملفات الموجودة وتطرح منها قائمة Calpurnia.
هاض بيكلفنا O(N) حيث N =عدد كل الملفات بالمجموعة، وهاض مكلف جداً لو عندك مليارات ملف!
💡 الإجابة الكاملة للدكتور:
نعم، AND و OR بنعملهم بكفاءة O(x+y). أما NOT فبيكلفنا O(N) خطي بعدد كل الوثائق مش بطول القائمتين فقط، وهاض هو التحفظ الجوهري!
نعم، AND و OR بنعملهم بكفاءة O(x+y). أما NOT فبيكلفنا O(N) خطي بعدد كل الوثائق مش بطول القائمتين فقط، وهاض هو التحفظ الجوهري!

تحسين الاستعلامات (Query Optimization) ⚡
تخيل عندنا استعلام فيه n كلمة مرتبطة بـ AND. سؤال: وين نبدأ؟ هل بيفرق الترتيب؟
الجواب المنطقي:
نعم، بيفرق! الحل الذكي هو نبدأ بالكلمة اللي عندها أصغر قائمة!
مثلاً في السلايد، استعلام Brutus AND Calpurnia AND Caesar:
نعم، بيفرق! الحل الذكي هو نبدأ بالكلمة اللي عندها أصغر قائمة!
مثلاً في السلايد، استعلام Brutus AND Calpurnia AND Caesar:
- Brutus: قائمتها تحتوي 7 مستندات
- Caesar: قائمتها تحتوي 8 مستندات
- Calpurnia: قائمتها تحتوي 2 مستندات فقط!

ليش بدنا doc. freq في القاموس؟ هسا الجواب! 💡
بتذكروا لما ضفنا عامود الـ document frequency في القاموس وحكينا
ليش فايدته‟؟ هسا طلع الدور!
فكرة التحسين بالتفصيل:
نبني استعلامات الـ AND بشكل أكفأ لو بدأنا من الكلمة الإقل تكراراً (smallest postings first)، والكلمة الأقل تكراراً هي اللي عندها أصغر doc. freq.
وهنا بيهم الـ doc. freq! بدونه ما بنعرف وين نبدأ. والأفضل إنه جاهز موجود بالقاموس ولا نحتاج نعد لنحسبه كل مرة!
نبني استعلامات الـ AND بشكل أكفأ لو بدأنا من الكلمة الإقل تكراراً (smallest postings first)، والكلمة الأقل تكراراً هي اللي عندها أصغر doc. freq.
وهنا بيهم الـ doc. freq! بدونه ما بنعرف وين نبدأ. والأفضل إنه جاهز موجود بالقاموس ولا نحتاج نعد لنحسبه كل مرة!
نتيجة التحسين:
استعلام Brutus AND Calpurnia AND Caesar بيصير (Calpurnia AND Brutus) AND Caesar. هيك بنضمن إنتاج أصغر وسط والخوارزمية أسرع!
استعلام Brutus AND Calpurnia AND Caesar بيصير (Calpurnia AND Brutus) AND Caesar. هيك بنضمن إنتاج أصغر وسط والخوارزمية أسرع!

تحسين أعم (More general optimization) 🔧
طيب، خلينا نكمل التحسين لغير AND كمان. شو بصير لو عندنا استعلام فيه AND و OR مع بعض؟ مثل: (madding OR crowd) AND (ignoble OR strife)
كيف نحسنها؟
- نحسب الـ doc. freq لكل الكلمات الأربع.
- نتوقع حجم كل مجموعة OR عن طريق جمع أرقام freq الكلمتين فيها.
- ننفذ AND بالترتيب من أصغر OR size لأكبر.

نماذج بولين الموسعة (Extended Boolean Models)
خلصنا من موضوع الفهرس، وهسا بندخل على موضوع جديد! نموذج البولين العادي عنده ضعف كبير: جوابه
دايماً
إما صح أو خطأ! متى بتعامل مع الدرجات والقرب، في النماذج الموسعة.
مصطلح جديد: مشغل القرب (Proximity
Operator):
بدل ما نبحث عن كلمة بس، النموذج الموسع بيسمح لك تشترط إن الكلمتين تكونوا قريبتين من بعض في النص.
بدل ما نبحث عن كلمة بس، النموذج الموسع بيسمح لك تشترط إن الكلمتين تكونوا قريبتين من بعض في النص.
- "Closeness" ممكن تتحدد بتحديد عدد الكلمات المسموحة بين الكلمتين.
- أو بتحديد إنهم لازم يكونوا في نفس الجملة أو الفقرة.

مثال واقعي: WestLaw أكبر محرك بحث قانوني في العالم ⚖️
هسا بنشوف نموذج البولين في تطبيق حقيقي! WestLaw هو محرك بحث قانوني
تجاري مستخدم من المحامين والقضاة حول العالم.
أرقام وحقائق:
- بدأ سنة 1975 كخدمة بحث بولين خالص.
- ضافوا الترتيب (Ranking) سنة 1992.
- ضافوا بحث موحد (Federated search) سنة 2010.
- فيه تيرابايتات من البيانات وأكثر من 700,000 مستخدم!
- والأهم: غالبية المستخدمين لسا بيستخدموا بحث البولين! يعني الموضوع لسا بيهم في الواقع.

كيف بيكتب المحامي الاستعلام بالـ WestLaw؟ 📜
هذا مثال حقيقي! محامي بده يلاقي قضايا عن حقوق المعاقين بمكان العمل.
الاستعلام: disab! /p access! /s work-site work-place (employment /3 place)
الاستعلام: disab! /p access! /s work-site work-place (employment /3 place)
فك الاستعلام كلمة كلمة:
- disab! = Wildcard → يلاقي disability, disabled, disabilities...
- /p = في نفس الفقرة واحدة.
- access! = Wildcard → accessed, accessing, accessibility...
- /s = في نفس الجملة.
- work-site work-place = OR ضمني (space يساوي OR).
- (employment /3 place) = كلمة employment لازم تكون بعد place ب 3 كلمات بالأكثر.

مثال ثاني بالـ WestLaw: محامي وضيوف
سكارى 🍺
مثال ثاني أذكى! بدنا نلاقي قضايا عن مسؤولية صاحب البيت هل ضيوفه سكرو وتسببوا بألم للغير.
الاستعلام: host! /p
(responsib! liab!) /p (intoxicat! drunk!) /p guest
- host! → host, hosts, hosting...
- /p → في نفس الفقرة.
- (responsib! liab!) → تجميع Wildcard للكلمتين: responsible, responsibility, liable, liability.
- (intoxicat! drunk!) → intoxicate, intoxicated, drunk, drunkenness.
- guest → كلمة عادية لازم تكون بنفس الفقرة.
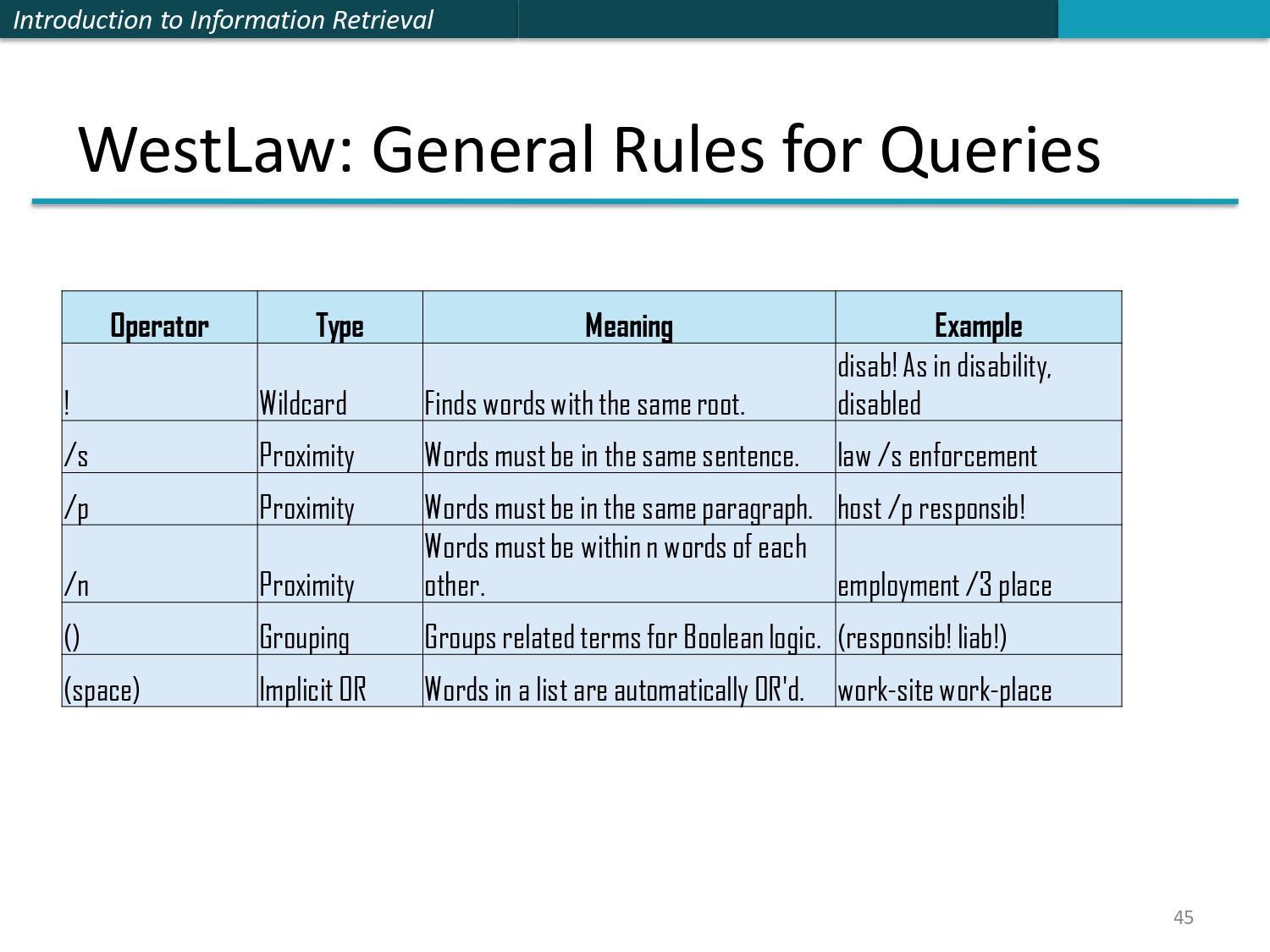
جدول مشغلات WestLaw العامة 📋
هاي الشريحة بتلخصلك كل المشغلات اللي بتعرفت عليها بالاستعلامات السابقة بشكل منظم.
ملخص المشغلات:
- ! = Wildcard →
يلاقي كل كلمة بنفس الجذر. مثال:
disab! - /s = Proximity →
نفس الجملة. مثال:
law /s enforcement - /p = Proximity →
نفس الفقرة. مثال:
host /p responsib! - /n = Proximity →
ضمن n كلمة. مثال:
employment /3 place - () = Grouping →
تجميع بولين. مثال:
(responsib! liab!) - (space) = Implicit
OR → مسافة بين كلمتين = OR تلقائي. مثال:
work-site work-place

مزايا نموذج البولين (Advantages) ✅
بعد ما تعرفنا على نموذج البولين بالتفصيل، خلينا نجمع إيجابياته!
- ✅ كفة جداً في التنفيذ (Very efficiently implemented) → بنينا الفهرس وخوارزميات الدمج وكلها بوقت O(x+y).
- ✅ نتائج متوقعة وسهلة التفسير (Predictable, easy to explain) → المستخدم بيعرف زبط شو بده يلاقي.
- ✅ استعلامات مبنية (Structured queries) → بتشتغل كويس للبحث المتخصص زي WestLaw.
- ✅ شغالة لمن يعرف شو يبحث (Works well when searchers know exactly what they want) → المحامي بعرف المصطلحات القانونية بالضبط.

عيوب نموذج البولين (Disadvantages) ⚠️ — الختام!
كلشي له إيجابيات وسلبيات، ونموذج البولين إله مشاكل!
- ❌ قرار ثنائي بدون تطابق جزئي (No partial matching) → الدوكيمنت إما ينجح كلياً أو يفشل، ما في وسط.
- ❌ ما في ترتيب للنتائج (No ranking) → بيجيبك كل المطابقين بدون ترتيب بالأفضلية.
- ❌ صعبة على المستخدم (Complex for users) → المستخدم لازم يكتب استعلام بولين مضبوط، وهاض صعب على الناس العاديين.
- ❌ الاستعلامات بتكون بسيطة جداً (Queries too simplistic) → الناس بغلبهم بيكتبوا AND بس عشان ما يعقدوا الاستعلام.
- ❌ إما أكثر من اللازم أو أقل (Too few or too many results) → لو AND مع كثير كلمات رح تطلع صفر نتائج، ولو OR مع كثير كلمات رح تطلع آلاف ما عندهاش لازم!
💡 ليش بدنا نماذج موسعة؟
هاي العيوب هي اللي دفعت العلماء يفكروا بنماذج أذكى ترتب النتائج وتفهم شو المستخدم بده فعلاً ، مثل نماذج الترتيب (Ranked Retrieval Models) اللي رح ندرسها !
هاي العيوب هي اللي دفعت العلماء يفكروا بنماذج أذكى ترتب النتائج وتفهم شو المستخدم بده فعلاً ، مثل نماذج الترتيب (Ranked Retrieval Models) اللي رح ندرسها !