
ليش بندرس هاي المادة أساساً؟ 🤔
تخيل حالك (زي الشخص اللي بالصورة) غرقان في جبل من الأوراق والكتب اللي مش مرتبة.. هاض هو حال البيانات
في العالم الرقمي اليوم!
البيانات الفوضوية (Unstructured Data):
إدارة البيانات هي من أهم استخدامات الكمبيوتر، بس المشكلة إن أغلب
البيانات النصية الموجودة في العالم مش مخزنة بطريقة مهيكلة ومُرتبة جوا Database.
ويعني شو المشكلة؟
بما إنها مش مهيكلة، معناته ما بنقدر نستخدم الاستعلامات الجاهزة (Structured Queries) زي SQL عشان
نستخرج اللي بدنا إياه.
الحل السحري:
كيف بدنا نحل هاي المشكلة؟ الجواب هو Information Retrieval (استرجاع
المعلومات)!

تعريف الـ Information Retrieval (الزبدة) 📝
التعريف الأكاديمي:
الـ IR هو علم إيجاد المواد (غالباً مستندات Documents) ذات طبيعة غير
مهيكلة (unstructured nature - وغالباً نصوص)، واللي بتلبي الرغبة أو بتجاوب على سؤال
عند المستخدم (Information Need) من داخل مجموعات بيانات ضخمة
(Large Collections).
أمثلة من حياتنا اليومية:
- Google Search: أشهر مثال للبحث بالويب.
- Amazon & YouTube: للبحث عن المنتجات أو الفيديوهات اللي ببالك.
- البحث جوا الملفات: زي لما تفتش عن كلمة داخل ملف PDF، أو تدور على رسالة قديمة في إيميلك (Emails).


الـ IR كطوق نجاة 🛟
شوف الصورة اللي بالسلايد.. إنت عبارة عن شخص صغير ضايع بنص مكتبة عملاقة فيها آلاف الكتب! هاض بالزبط
هو وضعنا مع الإنترنت اليوم.
Information Overload (العبء المعلوماتي):
إحنا عايشين بعصر غرقانين فيه بالمعلومات. الـ IR هو الأداة الأساسية
(Essential Tool) عشان نقدر نتعامل مع هذا الانفجار المعلوماتي ونجد اللي بنبحث عنه
بسرعة ودقة بدون ما نضيع.

علم الداتا المهيكلة vs الداتا الفوضوية ⚔️
البيانات المهيكلة (Structured Data):
هاض الشغل اللي تعلمناه زمان بقواعد البيانات (RDBMS).. في عندك جدول مرتب (زي جدول الطلاب اللي تحت
بالسلايد)، كل عمود إله اسم وقيمة واضحة (زي الـ GPA). لما بدك تدور، بتشغل استعلام ومفتاح أساسي (مثلاً GPA > 3.0) والكمبيوتر بجاوبك بدقة
100%.
البيانات غير المهيكلة (Unstructured Data):
هاض هو مجال مادتنا الـ IR.. الداتا عبارة عن كلام ونصوص (Natural
Language) ما إلها أعمدة ولا مفاتيح أساسية (No Primary Keys).
المشكلة:
السيستم الآلي ما بفهم المعنى الدلالي (Semantic Meaning)
المخفي ورا الكلام، ولازم يعتمد على معالجة اللغات الطبيعية (NLP) عشان يجرب يلاقي المعنى.

تحديات المادة: الكمبيوتر ما بيتحزّر! 🎲
في عنا مشكلتين أساسيات بهاي اللعبة:
1. البيانات فوضوية (Data is unstructured):
هاض بخلي السيستم مضطر يخمّن ويستنتج أي مستند فعلاً مرتبط
(Relevant) بالموضوع اللي بتبحث عنه.
2. سؤالك فوضوي (Query is unstructured):
المستخدم بكتب كلام طبيعي ومتنوع، والسيستم لازم يخمّن نية المستخدم
وقصده (User Intent) من هذا الكلام المكتوب.
جوهر العلم كله:
المشكلة إن الكمبيوتر بطبيعته الآلية "ما بيخبّص ولا بيتحزر"
(Computers don't guess!). قدرتك على بناء أنظمة قادرة "تستنتج" الصلة (Relevance) وتفهم
النية (Intent) من الداتا والسؤال العشوائي... هاض بالضبط هو علم استرجاع
المعلومات!

مشكلة الـ IR: شو بده المستخدم؟ 🤔
المستخدمين لأنظمة الـ IR (زي محركات البحث) عندهم حاجات للمعلومات (Information Needs)، وهاي الحاجات بتختلف درجة تعقيدها من شخص لثاني.
مثال على "رغبة معلوماتية" معقدة:
تخيل مستخدم بحكي: "دورلي على كل المستندات اللي بتحكي عن دور
الحكومة الفيدرالية في تمويل تشغيل مؤسسة النقل بالسكك الحديدية (أمتراك)!"... لاحظ قديش
الطلب طويل ومحدد!

من "رغبة" إلى "كلمات مفتاحية" 🔑
الرغبة لا تساوي الاستعلام (Need ≠ Query):
الوصف الطويل والمعقد اللي شفناه بالسلايد الماضي، مش بالضرورة يكون
"سؤال" (Query) ممتاز تدخله على السيستم!
عملية الترجمة (Translation Process):
عشان هيك، المستخدم بيعمل "ترجمة" لرغبته الطويلة وبحولها لـ Query قصير. هاي الترجمة بتنتج عنها
شوية كلمات مفتاحية (Keywords أو Index terms) بتلخص كل اللي بده
إياه. (يعني بدل الجريدة، بكتب: تمويل، حكومة، أمتراك، قطارات).

استرجاع وترتيب النتائج (Ranking) 🏆
لما المستخدم يدخل الـ Query تبعه للسيستم، بصير تفاعل مهم جداً:
تحديد المفيد (Useful / Relevant):
الهدف الأساسي للسيستم إنّه يرجع معلومات مفيدة ولها صلة بطلب
المستخدم.
ترتيب النتائج (Ranking):
المشكلة إن السيستم ممكن يلاقي آلاف المستندات، عشان هيك مطلوب منه يرتب
(Rank) هاي النتائج بناءً على "درجة الصلة" (Degree of
relevance)... يعني الأهم فالمهم، مش يرميلك إياهم بشكل عشوائي!

الهدف الأسمى (والمستحيل!) 🎯
المعادلة الصعبة للـ IR:
الهدف الرئيسي هو إن السيستم يجيبلك كل الأشياء المرتبطة بطلبك،
وبنفس الوقت يجيبلك أقل عدد ممكن من الأشياء اللي ما إلها دخل (Non
relevant)... عشان هيك بنحكي إن مفهوم "الصلة" (Relevance) هو أهم إشي
الحقيقة المُرّة (بالخط الأحمر):
ما في أي نظام IR بالدنيا بيقدر يعطي إجابات مثالية لكل
المستخدمين في كل الأوقات! (دايماً رح يكون في نسبة خطأ بالتحزير أو بالاسترجاع).
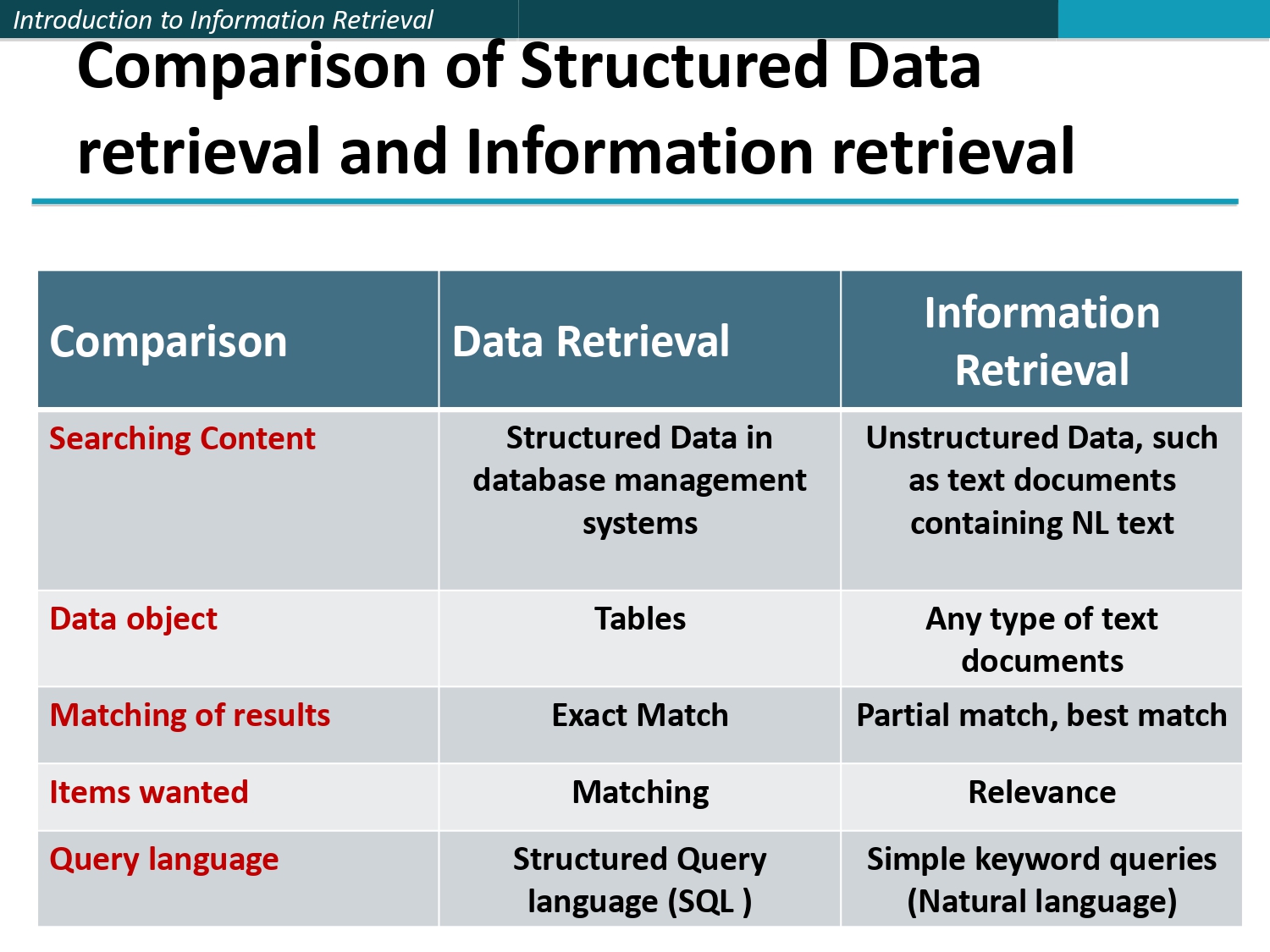
المواجهة الكبرى: DB ضد IR 🤼♂️ (الجزء الأول)
السلايدين الجايات رح يلخصولك الفرق الجوهري بين استرجاع البيانات (قواعد البيانات العادية) واسترجاع
المعلومات (محركات البحث):
1. شو بنبحث (البضاعة):
- في የ DR: بضاعتنا عبارة عن جداول (Tables) مليانة بيانات مهيكلة.
- في الـ IR: بضاعتنا هي مستندات نصية (Text documents) وأي إشي عشوائي مكتوب بلغة طبيعية.
2. كيف بنطابق النتائج؟:
- في የ DR (Exact Match): التطابق "حرفي ومضبوط 100%". يا إما الراتب 500، يا إما لأ!
- في الـ IR (Partial Match): التطابق "جزئي أو أفضل تطابق ممكن" (Best match). السيستم بحاول يجيبلك أقرب اشي لمعنى كلامك.
3. لغة البحث والهدف:
بالـ DR بكتب كود برمجي زي (SQL) بهدف "المطابقة" (Matching). أما بالـ IR بكتب كلمات طبيعية (بحكي
معه عادي) والهدف هو "الصلة" (Relevance).
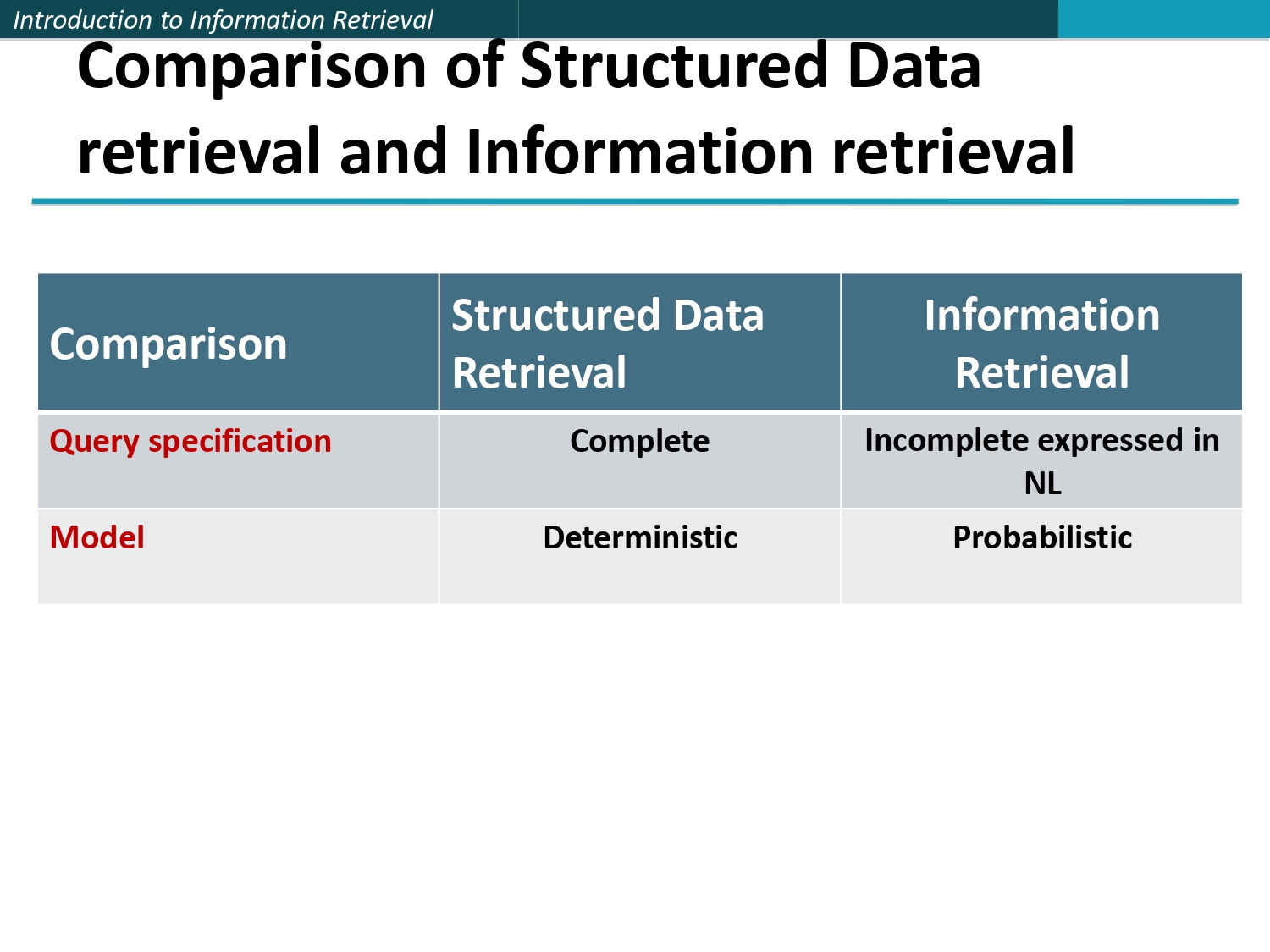
المواجهة الكبرى (الجزء الثاني) ⚔️
بنكمل المقارنة بين النظامين، وهاي أهم نقطتين فيهم:
1. وصف الاستعلام (Query Specification):
- في الـ Structured Data (DR): الاستعلام بكون "كامل وواضح" (Complete)، إنت عارف تماماً شو الشرط اللي بدك ياه (مثلاً Where GPA = 4).
- في الـ IR: الاستعلام بكون "غير كامل" (Incomplete) ومكتوب بلغة طبيعية (NL). المستخدم بيرمي كلمتين والسيستم مفروض يفهّمه!
2. الموديل/النموذج (Model):
- قواعد البيانات (Deterministic): يعني "حتمي". نفس الـ Query على نفس الجدول دايماً بعطيك نفس النتيجة الحتمية والمؤكدة. 💯
- الـ IR (Probabilistic): يعني "احتمالي". السيستم بيحسب احتمالات.. "احتمال يكون هاض المستند مفيد بنسبة 80%". ما في إشي مؤكد 100%! 🎲

المهمة الأساسية للـ IR 🛠️
ببساطة، أي نظام IR بالحياة إله مدخلات (Given) وإله مخرجات (Find):
المُعطيات (Given):
- Corpus: مجموعة ضخمة من المستندات المكتوبة بنصوص طبيعية (مخزن الداتا).
- Query: استعلام المستخدم (السؤال) اللي كمان بكون مكتوب على شكل نص عادي.
المطلوب إيجاده (Find):
السيستم لازم يطلّع "مجموعة مرتبة" (Ranked set) من
المستندات، وشرط هاي المستندات إنها تكون ذات صلة (Relevant)
بسؤال المستخدم. (هاي هي وظيفة السيستم اللي بتوخذ راتب عليها!).

أنواع المستندات (شو هي الداتا تبعتنا؟) 📚
مصطلح Document:
بالـ IR، لما نحكي كلمة "مستند"، ما بنقصد بس ملف وورد! حرفياً أي شيء
غير مهيكل وفيه معلومات بعتبره Document!
أمثلة: صفحات الويب، الإيميلات، الكتب، الأوراق العلمية، التغريدات
(Tweets)، بوستات المنتديات، وحتى ملفات الملتميديا.
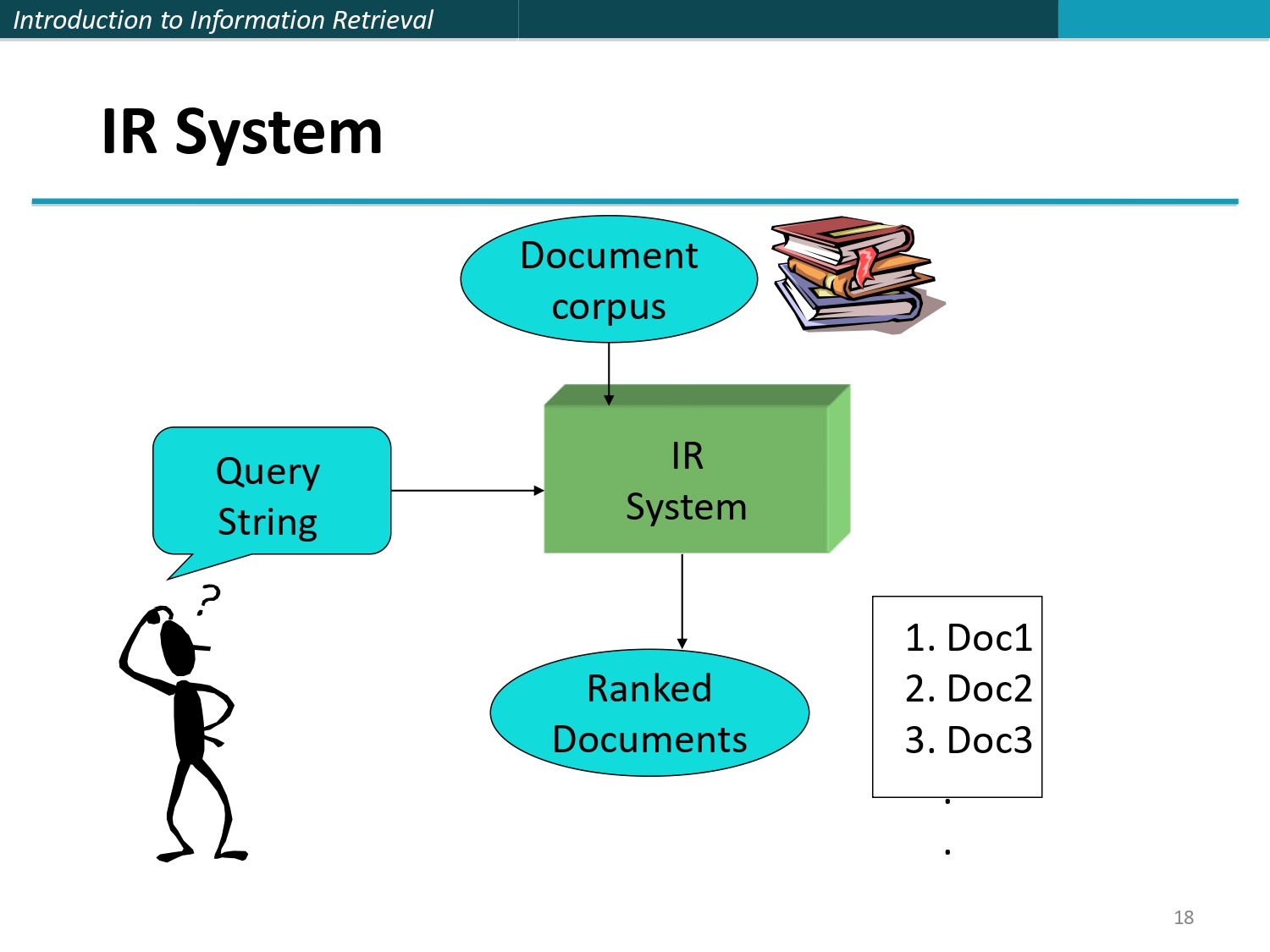
آلية عمل نظام الـ IR (مخطط) 🔄
مخطط بسيط جداً بلخص كل اللي حكيناه:
المدخلات (من جهتين):
جهة فيها الـ Document corpus (مستودع الكتب/الوثائق)، وجهة فيها
المستخدم اللي بيسأل الـ Query String.
المعالجة والمخرجات:
نظام الـ IR بالمركز (الأخضر) بوخذ المدخلات وبطلع منهم الخلاصة المُرتبة
(Ranked Documents).. ولاحظ إنه بطلعهم مرقمين (Doc1, Doc2, Doc3) حسب مين الأقوى صلة.

شو يعني "الصلة" (Relevance)؟ 🎯
حكم شخصي (Subjective judgment):
إشي مهم جداً تفهمه.. الصلة أو ה"Relevance" مش إشي مطلق 100% (مش 1+1=2)!! الصلة هي حكم شخصي (Subjective) بيعتمد على المستخدم نفسه اللي سأل السؤال!.
متى نعتبر المستند "ذو صلة" بطلب المستخدم؟ (شروط مفيدة):
- Being on the proper subject: إنه يحكي عن نفس الموضوع اللي قاصده المستخدم!
- Being timely: إنه يكون حديث (معلومة جديدة مش قديمة منتهية صلاحيتها).
- Being authoritative: يكون جاي من مصدر موثوق وبُعتمد عليه (مثلاً مصدر طبي مش أي منتدى).
- Satisfying goals: والأهم، إنه "يُرضي" رغبة المستخدم ويلبي حاجته للمعلومة!

البحث بالكلمات المفتاحية (بدايات محركات البحث) 🔍
قديماً، محركات البحث ما كانت تفهم معنى الكلام، كانت بس تدور هل
الكلمة اللي كتبتها موجودة جوّا المستند ولا لأ؟ (عملية تطابق بسيطة).
طريقتين لمعنى "الصلة" زمان:
- التطابق الحرفي (Verbatim): لازم تفاصيل الجملة تيجي زي ما هي بالضبط. مثال: كلمة "data mining" لازم يكونوا ورا بعض بالضبط بالمستند، غير هيك ما برجعلك إياه.
- كيس الكلمات (Bag of words): مش متشدد كثير زي الأول.. بكفيه إن الكلمات تكون موجودة بالمستند بأي ترتيب! المهم موجودين. مثال: جملة "mining of data" بتزبط كإجابة لـ "data mining".

مشاكل البحث بالكلمات (ليش السيستم القديم غبي؟) 🧠
لأنه السيستم بيعتمد على الكلمات بدون ما يفهم المعنى، وقعنا بمشكلتين كبار:
1. المترادفات (Synonymous Terms):
ممكن السيستم ما يجيبلك مستندات مفيدة (Relevant) بس لأن كاتبها
استخدم كلمة ثانية لنفس المعنى!
أمثلة للتبسيط: إنت بحثت عن "Restaurant"، فما رح
يطلعلك أي مستند مكتوب فيه "Cafe" مع إنهم نفس الإشي وبفيدوك! (نفس الإشي PRC مقابل China).
2. الكلمات اللي بتحمل أكثر من معنى
(Ambiguous Terms):
ممكن السيستم يجيبلك مستندات ما إلها دخل (Irrelevant) بس
فيها كلمتك!
أمثلة للتبسيط: تبحث عن "Apple" قاصد الشركة،
يطلعلك مستندات عن التفاح (الفاكهة)! أو تبحث عن "Bat" قاصد الخفاش، يطلعلك مقالات عن مضرب
البيسبول!

الـ IR الذكي (التطور) 🤖
عشان نحل مشاكل الكلمات ونعمل بحث ذكي جداً، أنظمة الـ IR الحديثة صارت تعمل هاي الأشياء:
- 1. تأخذ المعنى بعين الاعتبار (Meaning): يعني صارت تفهم إن التفاحة ممكن تكون شركة!
- 2. تركز على الترتيب (Order): ترتيب كلامك بالسؤال بصنع فرق بالمعنى.
- 3. تتأقلم مع المستخدم (Adapting): بتصير تفهم شو جوّك من حركاتك (تغذية راجعة). إنت بتختار مقالات طبية دائماً؟ رح تصير تبدّيها إلك.
- 4. قوة المصدر (Authority): مش أي واحد بكتب معلومة جوجل بصدقه! لازم الموقع يكون إله ثقل وهيبة.

أساسيات من جوا المطبخ 🧑🍳
أي نظام IR بشتغل على 3 أعمدة رئيسية:
1. تمثيل الاستعلام (Query Representation):
لازم نسكر الفجوة بين سؤال المستخدم وفهم السيستم.
- Lexical gap (معجمي): إنك تفهم إن (create) و (creating) نفس الكلمة والنهايات مش مهمة.
- Semantic gap (دلالي): إنك تفهم إن (car) و (automobile) نفس الإشي، ومرات السيستم بيستعين بالتغذية الراجعة (feedback) ليفهم!
2. تمثيل المستندات (Document Representation):
السيستم ما بحفظ المستندات زي ما هي نصوص طويلة (لأنه غباء). السيستم بحفظها بطريقة داخلية (Internal Representation)، زي إنه يعمل قائمة بتوضح كل كلمة وين
تكررت، وبراعي الهيكلة (مثلاً هاي الكلمة بالعنوان ولا بالنص؟).
3. نموذج الاسترجاع (Retrieval
Model):
هاض مخ السيستم! عبارة عن خوارزميات (Algorithms) وظيفتها تلاقي
وتقيّم وتجيبلك أقوى المستندات صلة (Most relevant
documents) بطلبك.
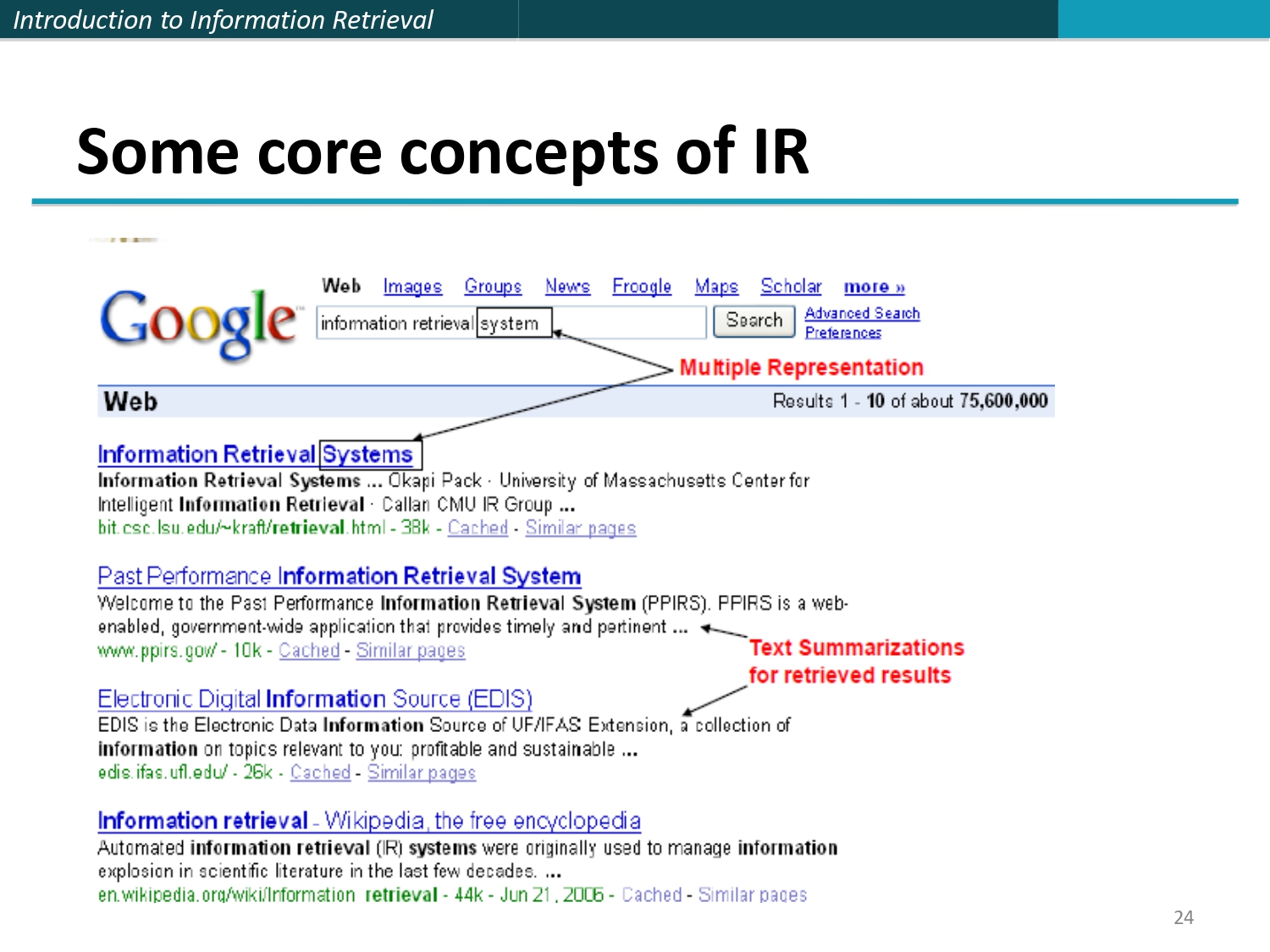
تطبيق الأساسيات على Google 🔎
بالسلايد، الدكتور بتشرح على شاشة بحث الجوجل عشان تورجيك الأساسيات عالأرض:
Multiple Representation (تمثيل متعدد):
بتلاحظ إن جوجل فاهم إن (System) و (Systems) هما كلمات بتدل على نفس الإشي، فبعملك Highlight إلهم
الاثنين! (هاض هو الـ Lexical gap اللي حكينا عنه).
Text Summarizations (تلخيص النص للنتائج):
تحت كل رابط للنتيجة بتلاقي جوجل مقتبس سطرين من الموقع وبحفزك تفوت عليه. هاض الإشي مش عبث!
السيستم عمل تلخيص و جاب الكلمات اللي إنت بحثت عنها بلون أسود غامق (Bold) عشان يورجيك إنه نتيجة
قوية وإلها صلة.

أبليكيشنز الـ IR: البحث عالويب 🌐
هون بنبلش نحكي عن مجالات تطبيق ה-IR بالحياة العملية.
محركات البحث (Web Search):
أشهر وأكبر مثال للـ IR! زي (Google, Bing, Yahoo). إنت بتعطيه Query و هو بفلترلك الإنترنت وبجيبلك
Ranked URLs حسب قوة الصلة.

أبليكيشنز الـ IR: المساعدات الشخصية 📱
المساعد الذكي (Intelligent PDAs):
كلنا بنستخدمهم بموبايلاتنا! (Siri من أبل، Cortana من مايكروسوفت، Alexa من أمازون، و Google
Assistant). هذول كلهم أنظمة IR شغالة بصوتك. بتعطيهم الـ Query حكي، وهم بيترجموه وبجيبولك
المعلومة.

أبليكيشنز الـ IR: استخراج المعلومات 📊
تكوين الداتا المنظمة (Information Extraction):
وظيفة رهيبة للـ IR! بتكون عندك نصوص عادية (Unstructured) زي جرايد أو تقارير، السيستم بفوت فيها
وبستخرج منها معلومات منظمة (Structured data) وبحطلك إياها
بجدول!
مثال: بعطيه مقال مالي طويل، بطلعلي منه جدول
فيه اسم الشركة، الأرباح، والخسائر.
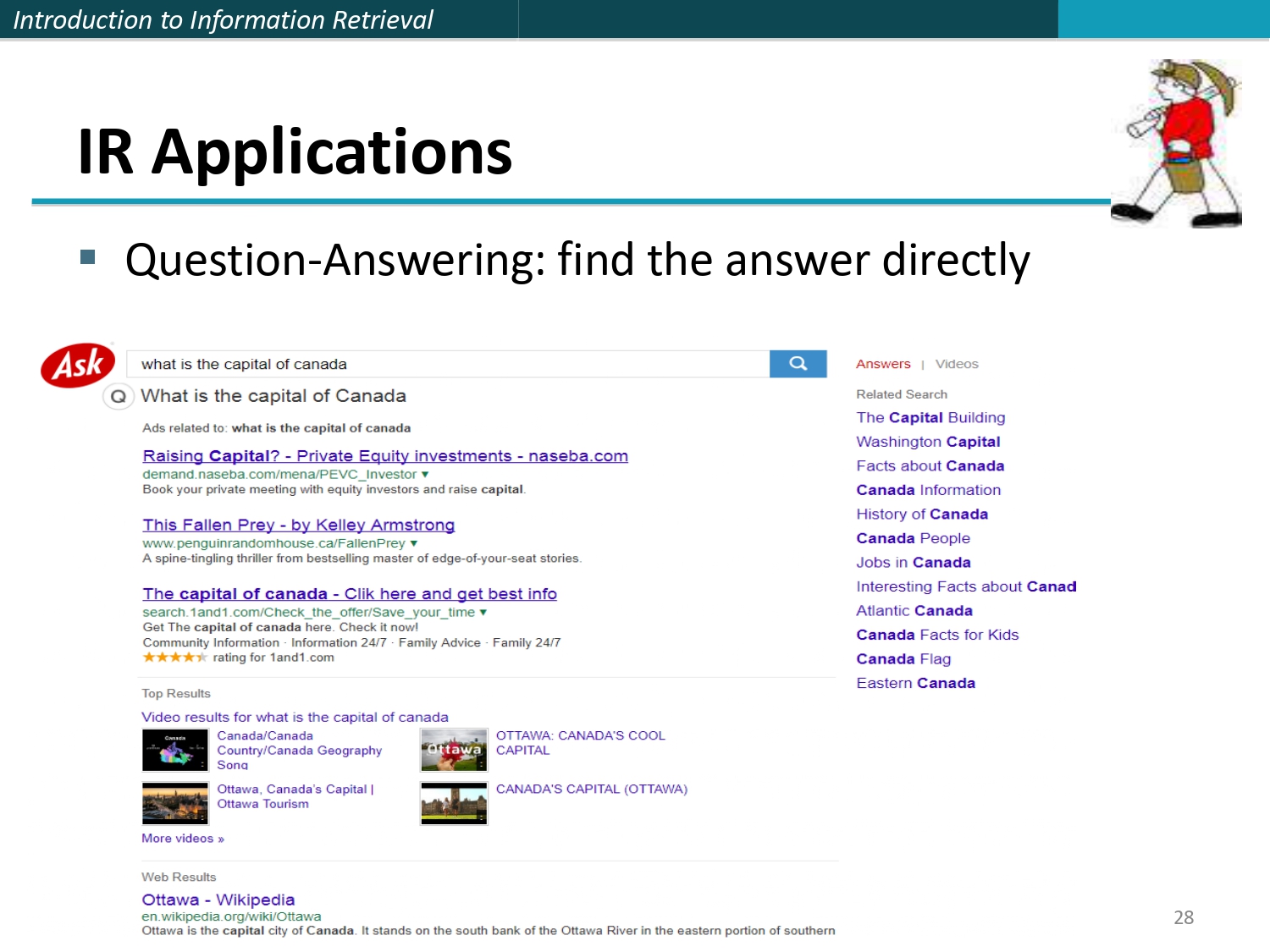
أبليكيشنز الـ IR: الإجابة المباشرة 💡
أسئلة وأجوبة (Question-Answering):
تطوّر جميل بالـ IR، بدل ما يعطيك السيستم مليون رابط تقرأهم عشان تعرف عاصمة كندا، بطولك الإجابة
(Ottawa) وبحطلك إياها بوجهك جاهزة! Find the answer directly!

أبليكيشنز الـ IR: بحث الملتميديا 🖼️
بحث الصور والفيديو (Multimedia IR):
الـ IR مش بس نصوص! بتقدر تبحث باستخدام صورة أو فيديو أو صوت. زي
بحث الصور بجوجل.
- كيف بشتغل النظام؟ برفعله صورة بسة (Query).
- السيستم بستخرج الميزات البصرية (Feature Extraction) زي الألوان وحواف الصورة.
- بقارنها بقاعدة البيانات (Database) وبجيبلي صور بتشبهها! (العملية مشمولة بالرسمة).

أبليكيشنز الـ IR: الاقتراحات (زي أمازون) 🛒
أنظمة التوصية والتزكية (Recommendation Systems):
السيستم بعرف شو اهتماماتك بناءً على بحثك أو مشترياتك، فبصير يعطيك اقتراحات. زي لما تشتري كتاب من
أمازون بحطلك شريط تحته: "الزبائن اللي اشتروا هالكتاب اشتروا هذول
كمان!" (Collaborative information).
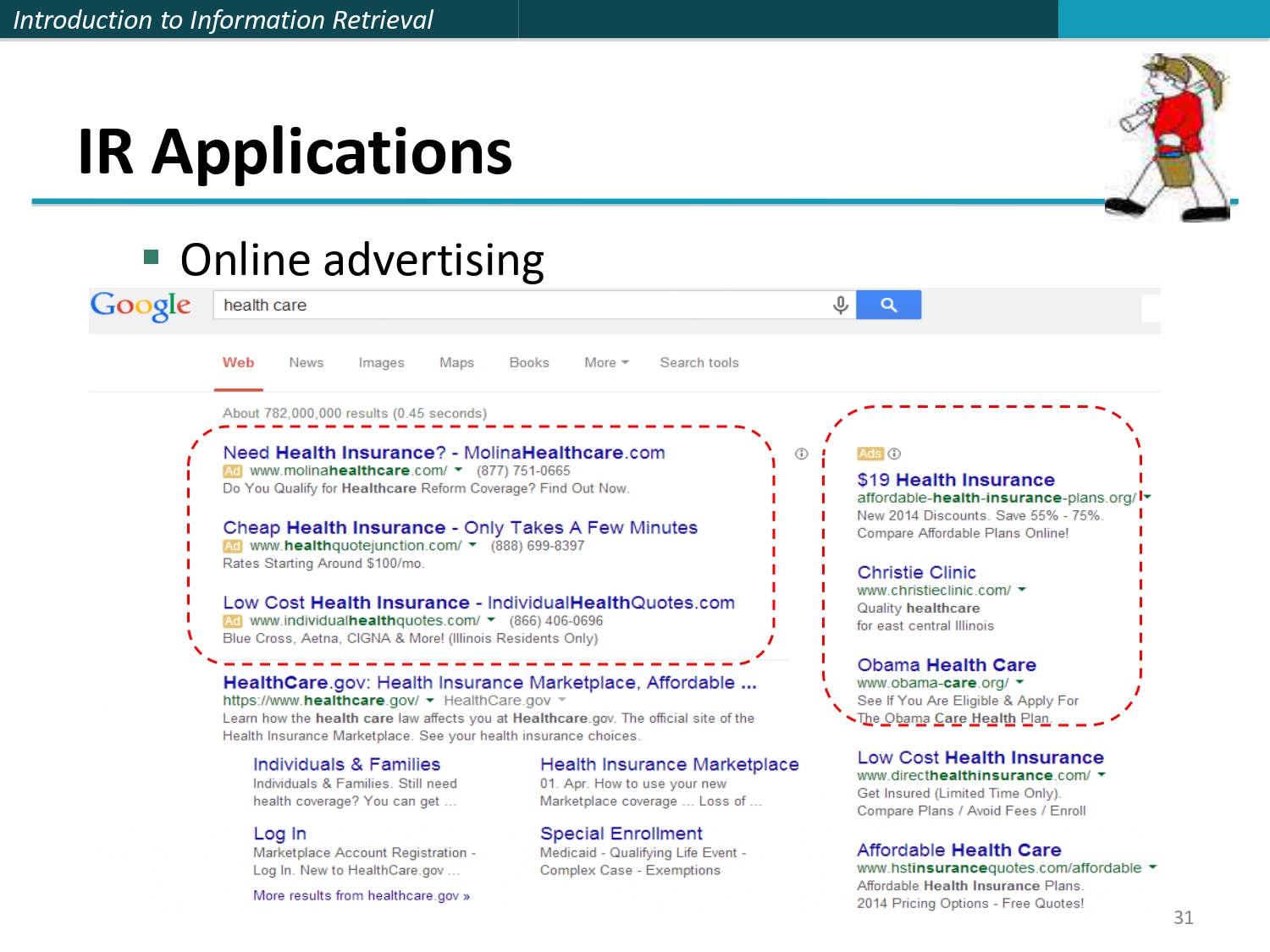
أبليكيشنز الـ IR: الإعلانات الممولة 💰
الإعلانات الأونلاين (Online Advertising):
جوجل بتستخدم الـ IR للإعلانات.. لما تبحث عن "تأمين صحي"، الـ IR بجيبلك أول اشي مواقع دافعة مصاري
لجوجل (معمول إلها Ads) عشان تطلع بوجهك أول اشي لأنها ذات صلة
(Relevant) للـ Query تبعك!

الخلاصة: الـ IR هو العقل المدبر! 🧠
ببساطة نقدر نحكي: "الـ IR هو المحرك الأساسي ورا أي نظام ذكاء
اصطناعي (AI) بتعامل مع داتا ضخمة!"
- بدون الـ IR: ما في جوجل! ما في سيري! ما في بحث عاليوتيوب! وما في توصيات بنتفليكس!
مصطلح الـ RAG (حديث ومهم جداً):
RAG = Retrieval-Augmented Generation
من دمج الـ IR مع نماذج اللغات (زي ChatGPT)، بنعمل نظام قوي.
- شو المشكلة القديمة؟ الشات بوتس كانوا يعتمدوا عالمعلومات اللي تدربوا عليها (وممكن تكون قديمة).
- شو الحل مع (RAG)؟ النظام بيبحث عن المعلومات الجديدة بالإنترنت (Retrieval)، بحدث داتا تبعته، بعدين بجاوبك بإجابة دقيقة ومنطقية (Generation)! (بدونه الموديل بظل محدود، معاه بصير عنده علم خارجي متجدد).