QudahWay IR
Phrase Queries & Positional Indexes | استعلامات العبارات والفهرسة الموقعية


🎯 الهدف من استعلامات العبارات (Phrase Queries)
تخيل إنك بتبحث عن كلمة "stanford university" كـ جملة وحدة (Phrase).
السيستم العادي رح يجيبلك أي ملف فيه هالكلمتين بغض النظر عن ترتيبهم، وهاض بيعملنا مشكلة كالتالي:
❌ مثال يخفق فيه السيستم العادي (No Match):
جملة: "I went to university at Stanford" (الكلمات متباعدة عن بعضها ومش جاية كعبارة وحدة). الفهارس البدائية بتعتبره ماتش!
جملة: "I went to university at Stanford" (الكلمات متباعدة عن بعضها ومش جاية كعبارة وحدة). الفهارس البدائية بتعتبره ماتش!
✅ مثال صحيح (Match):
جملة: "The stanford university research..." (الكلمات متتالية تماماً وهاض اللي بنبحث عنه).
جملة: "The stanford university research..." (الكلمات متتالية تماماً وهاض اللي بنبحث عنه).
الخلاصة: المستند لم يعد يُعامل كأنه "كيس كلمات" (Bag of Words)
مبعثر ومجرد من أي ترتيب، لازم السيستم يبدأ يفهم "أماكن" وتجاور الكلمات مع بعضها!

📚 المحاولة الأولى: Biword Indexes
كيف ممكن نبحث عن عبارة كاملة (Phrase)؟ أول فكرة خطرت للعلماء هي Biword
Indexes (فهرس الكلمتين).
الفكرة ببساطة: بدل ما نفهرس كل كلمة لحال، بندمج كل كلمتين متتاليتين وبنعتبرهم "مُصطلح واحد" جديد.
مثال: نص مثل Friends, Romans,
Countrymen بتكوّن منه أزواج: friends romans و romans countrymen.
النتيجة: لو بحثت عن عبارة من كلمتين بالضبط، السيستم رح
يطابقها فوراً كأنها كلمة وحدة ويجيبلك النتيجة سريعاً بدون أي حسابات.

🔗 كيف بنبحث عن جملة أطول من كلمتين؟ (Longer Phrases)
بما إننا شغالين على نظام الثنائيات الـ Biword، شو بصير لو المستخدم بحث
عن جملة طويلة فيها 4 كلمات؟ لأنه النظام ما بيفهم إلا كل "مسارين" مع بعض!
الحل البرمجي (التقطيع): بنقوم بتقسيم الجملة الطويلة لأزواج
(ثنائيات متداخلة)، وبنربط بينهم بعملية الإضافة المنطقية AND. وهيك بنجبر السيستم يدور على كل هاي الأزواج مع بعض في
نفس المستند.
مثال السلايد: طلب منا جملة من 4 كلمات: stanford university palo alto.
عشان تتوافق مع نظام الـ Biword، بنفككها كالتالي:
عشان تتوافق مع نظام الـ Biword، بنفككها كالتالي:
- الزوج الأول: "stanford university"
- AND الزوج الثاني: "university palo"
- AND الزوج الثالث: "palo alto"
نتيجة التنفيذ: السيستم رح يروح يجيب المستندات اللي بيتحقق
فيها وجود هاي الأزواج الثلاثة معاً. وهذه المحاولة رح تسببلنا كوارث تقنية !

⚠️ مشاكل قاتلة في الـ Biword!
للأسف، طريقة دمج الكلمات سببت كارثتين تقنيات للمحرك:
1. مشكلة False Positives: لما قسمنا جملة لـ 3 أزواج، ممكن
السيستم يجيبلك ملف فيه هالأزواج بس مبعثرة! يعني بيحتوي أزواجك بس الجملة الأصلية مش موجودة متصلة
كقطعة واحدة، وهاض بعطيك "نتائج خاطئة".
2. تضخم الفهرس (Index Blowup): لأنّ كل "كلمتين" صاروا
"مُصطلح جديد" بالقاموس، عدد المصطلحات الممكنة صار فظيع، وحجم الفهرس اتضخم بشكل غير منطقي إطلاقاً
لتخزينه.

� الحل السحري: Positional Indexes
بسبب فشل الـ Biword، انتقلنا للحل المنطقي والمُعتمد عالمياً: الفهرسة
المكانية (Positional Indexes).
الفكرة الذهبية: بنرجع لفهرسة كل كلمة بشكل منفصل بالمستند، ولكن
هالمرة، بنسجل "المكان" (Position) اللي ظهرت فيه الكلمة
جوا المستند!
شكل الفهرس الجديد:
<term, num_docs; doc1: pos1, pos2...>
يعني الكلمة، ثم عدد الملفات، ثم رقم الملف ومعه كل الأرقام اللي بتمثل مواقع الكلمة داخل هاض الملف بالذات.
<term, num_docs; doc1: pos1, pos2...>
يعني الكلمة، ثم عدد الملفات، ثم رقم الملف ومعه كل الأرقام اللي بتمثل مواقع الكلمة داخل هاض الملف بالذات.

� مثال على الفهرس المكاني (Positional Index)
لنفصل شكل الفهرس من الداخل من خلال هالمثال لكلمة be:
بنية السطر: <be: 993427; 1: 7, 18,
33, 72, 86, 231; ...>
هاض السطر بيحكيلنا قصة كاملة عن مسار الكلمة!
هاض السطر بيحكيلنا قصة كاملة عن مسار الكلمة!
تفكيك الأرقام:
- 993427: تدل على عدد المستندات الكلي اللي بتحتوي هالكلمة.
- 1: 7, 18, 33...: المستند رقم (1) بيحتوي هالكلمة في المواقع 7، 18، 33، وهكذا.
وهاد النمط بيتكرر لكل مستند جديد بتظهر فيه الكلمة (2: 3, 149... و 4: 17...).
- 993427: تدل على عدد المستندات الكلي اللي بتحتوي هالكلمة.
- 1: 7, 18, 33...: المستند رقم (1) بيحتوي هالكلمة في المواقع 7، 18، 33، وهكذا.
وهاد النمط بيتكرر لكل مستند جديد بتظهر فيه الكلمة (2: 3, 149... و 4: 17...).

⚙️ كيف بنبحث عن الجملة برمجياً؟ (Processing)
عشان السيستم يطابق عبارة مثل to be or not to be، بيعمل الآتي:
الشرط الرياضي: عشان نثبت إن كلمة "be" إجت بالضبط ورا كلمة "to"،
لازم موقع "be" يكون أكبر من موقع "to" بـ 1.
يعني: pos(be) = pos(to) + 1.
شرح المثال: إذا سحبنا كلمة "to" من المستند ولقيناها بموقع [7]،
لازم كلمة "be" تكون بموقع [8] عشان تقبل كـ Match صحيح.

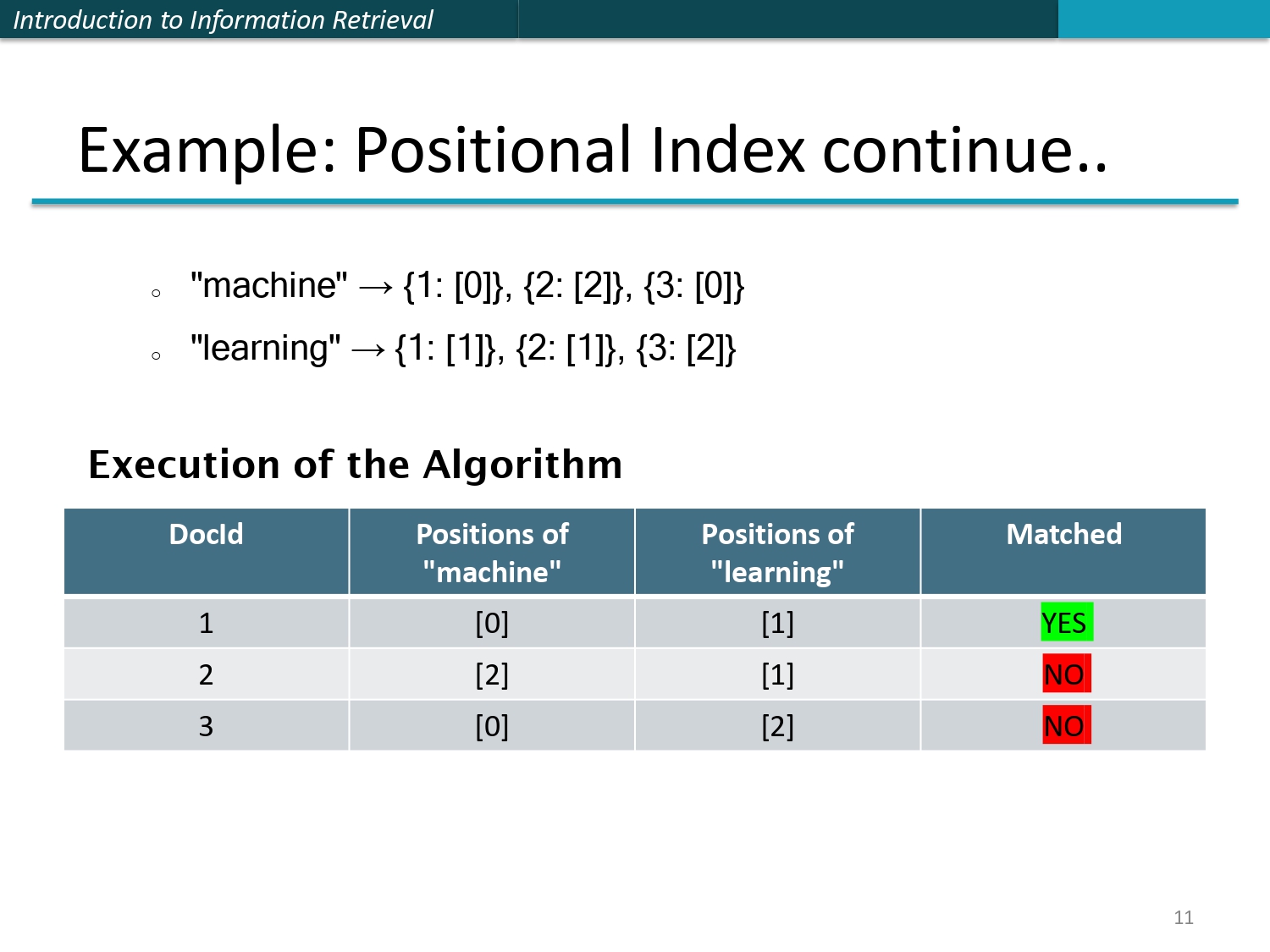
🏗️ مثال عملي: بناء الفهرس (جزء 1)
كيف السيستم بيبني الـ Positional Index من الصفر استناداً لـ 3 ملفات صغيرة كمثال:
خطوة 1 - الفهرسة: بنمسك كل كلمة بكل ملف، وبنحدد رقم الملف
(DocID) وموقع الكلمة (تبدأ من 0).
مثال كلمة machine: ظهرت بالملف 1 بموقع صفر {1: [0]}، وبالملف 2 بموقع اثنين {2:
[2]}، وبالملف 3 بموقع صفر {3: [0]}.
القاموس الناتج: الجدول اللي بالسلايد بمثل الذاكرة
النهائية اللي رح نستخدمها عشان ندور على أي جملة لاحقاً.

⚙️ مثال عملي: خوارزمية البحث (جزء 2)
الآن اجا أحدهم يبحث عن العبارة "machine learning" كجملة وحدة.
الهدف (Goal): بدنا الملفات اللي بتيجي فيها كلمة learning مباشرةً بعد كلمة machine.
الخطوات:
1. بنسحب قائمة كلمة machine وقائمة كلمة learning من الفهرس اللي عملناه بالسلايد السابق.
2. بنروح لكل ملف مشترك بيناتهم (مثلاً الملف 1، 2، 3) وبنفحص شرط التجاور.
1. بنسحب قائمة كلمة machine وقائمة كلمة learning من الفهرس اللي عملناه بالسلايد السابق.
2. بنروح لكل ملف مشترك بيناتهم (مثلاً الملف 1، 2، 3) وبنفحص شرط التجاور.
شرط التجاور: لازم موقع learning يساوي موقع machine زائد 1.
pos(learning) = pos(machine) + 1.
� خوارزمية دمج المواقع (Positional Intersect)
كيف بشتغل الكود البرمجي لهالعملية الخرافية؟
السحر في الـ Pointers: الخوارزمية بتوقف عند أول موقع للكلمة
الأولى وأول موقع للثانية.
شرط المسافة المسموحة (k): بنحسب الفرق. إذا كان |pos(word2) - pos(word1)| <= k، معناها لاقينا تطابق وبنسجله في
القائمة!
سرعة الاستجابة: بمجرد ما تصير المسافة كبيرة، بنمشي
بالمؤشر الأصغر للأمام. هالشي بيضمن إنه نقرأ الكلمات بسرعة البرق.

📏 استعلامات التقارب (Proximity queries)
هون بنشرح قدرة الفهرس الموقعي على تلبية الاستعلامات المعقدة اللي بتطلب كلمات ضمن مسافة محددة من
بعضها:
شرح الاستعلام (LIMIT!): استعلام مثل /3 STATUTE /3 FEDERAL /2 TORT (وهو استعلام قانوني معقد)، بيطلب كلمات
محددة تكون قريبة من بعضها بمسافات معينة لا يتجاوزها.
معنى المعامل (/k): ببساطة، الرمز /k بيحكيلنا "ضمن مسافة مقدارها k كلمة من..." (within k words of).
فمثلاً /3 معناها الكلمتين مسموح يبعدوا عن بعض أقصى شيء 3 مواقع.
الخلاصة والقوة: السلايد بيأكد بشكل واضح (Clearly) إن فهارس
المواقع Positional indexes هي الوحيدة اللي بتُستخدم بفاعلية لهيك
نوع من الاستعلامات الدقيقة المعتمدة على المسافة، بينما استخدام فهارس Biword indexes مستحيل يزبط هون لأنها بس بتخزن ثنائيات متلاصقة بدون
أي إحداثيات مرنة!

📈 حجم الفهرس المكاني (Positional index size)
مع كل قوة الفهرس الموقعي، بييجي تحدي المساحة المزعج اللي بيحتاج نعالجه:
توسع هائل في التخزين: الفهرس المكاني بزيد مساحة تخزين
القوائم (postings) بشكل ملحوظ وكبير جداً (Substantially). ورغم إنه احنا بنقدر نضغط (Compress)
هالمساحة بخوارزميات رح ناخذها بعدين، إلا إنو بيضل أضخم من الفهرس العادي.
المعيار المعتمد (Standardly used): بالرغم من استهلاكه
الكبير للمساحة، الفهرس المكاني صار المعيار الأساسي والمُستخدم حالياً في كل أنظمة البحث ومستحيل
نستغني عنه!
ليش لا غنى عنه؟ لأنه بعطينا قوة (Power) وفائدة عظيمة مستحيلة في
الفهارس السابقة؛ وهي البحث عن "العبارات المتلاصقة" (Phrase) و"التقارب" (Proximity)، سواء بطريقة
مباشرة أو ضمنية بأنظمة ترتيب النتائج (Ranking).

� تأثير حجم المستند على الـ Positional Index
كيف حجم المستند الواحد بيلعب دور جوهري بتضخيم المشكلة؟
تعدد الإدخالات: بالنظام المكاني بنحتاج مدخل (Entry) لكل ظُهور
حرفي للكلمة بالمستند، مش بس مجرد مرة وحدة للقول إنها موجودة بالملف! وهذا بيعني إن الحجم بيعتمد
عالـ "متوسط لحجم المستندات".
مقارنة بين المستندات: صفحات الويب العادية غالباً فيها أقل من
1000 كلمة مابتخوف. لكن لو مسكنا مستندات ضخمة زي (الكتب، القصائد الملحمية، ملفات SEC)، رح نلاقي
فيها بسهولة 100,000 كلمة!
شرح لجدول التكرار (Why?): السلايد بيفترض كلمة تكرارها
0.1%:
- بملف 1000 كلمة: الفهرس العادي بسجل 1 Posting، والمكاني بسجل 1 Positional Posting (ما في فرق).
- بملف 100,000 كلمة: العادي بسجل إنها موجودة مرة وحدة (1 Posting)، بينما المكاني رح يلاقيها انذكرت 100 مرة ورح يضطر يسجل الـ 100 موقع تبعها بالذاكرة (وهون الكارثة! زاد 100 ضعف!).

� قواعد عامة للفهرس (Rules of Thumb)
مقاييس معروفة بعالم الـ IR بتعطينا تصور سريع عن التكلفة مقابل الأداء:
مقارنة بالحجم العادي: الفهرس المكاني (Positional Index)
بيكون حجمه مقدر بـ 2 إلى 4 أضعاف (2-4x) مساحة الفهرس التقليدي
Non-positional.
النسبة المئوية من النص: بيستهلك الفهرس المكاني مساحة تعادل ما
بين 35% إلى 50% من الحجم الأصلي للنص اللي قاعد بتفهرسه!
ملاحظة هامة (Note): السلايد بيأكد إنو هاي الأرقام
والقواعد بتنطبق بشكل أساسي فقط على اللغات المشابهة للإنجليزية
(English-like languages). اللغات اللي تركبيتها غير، ممكن تأدي لأرقام أضخم.

� استراتيجية المزيج المهجن (Combination schemes)
ليش ما ندمج الخصائص الحلوة بكل الفهارس مع بعض؟ دمج الـ (Biword) مع الـ (Positional) بيولد نتائج
سريعة جداً:
سرعة الأسماء المشهورة: في عبارات شائعة الها طلب بشكل كثيف
جداً مثل "Michael Jackson" أو "Britney
Spears". رح يكون "غير فعال ومُتعب" (Inefficient) إنه السيستم يعمللهم حسابات ومقاطعة
مواقع (Merge) كل مرة!
الحل: بنفهرسهم بنظام الـ Biword لحالهم ليتم استرجاعهم فوراً بدون تعب.
الحل: بنفهرسهم بنظام الـ Biword لحالهم ليتم استرجاعهم فوراً بدون تعب.
معضلة فرقة (The Who): هاي فرقة غنائية اسمها مكون من كلمتين
(Stop words) بسيطات جداً. حساب أماكن الكلمتين ودمجهم راح يعلق محرك البحث من كثر ما هم مكررين في
الإنترنت! وهون استخدام الـ Biword لدمجهم مع بعض يعتبر منقذ
للسيستم وبيخلي استرجاع معلومات هالفرقة سريع وبدون ضغط كبير.