
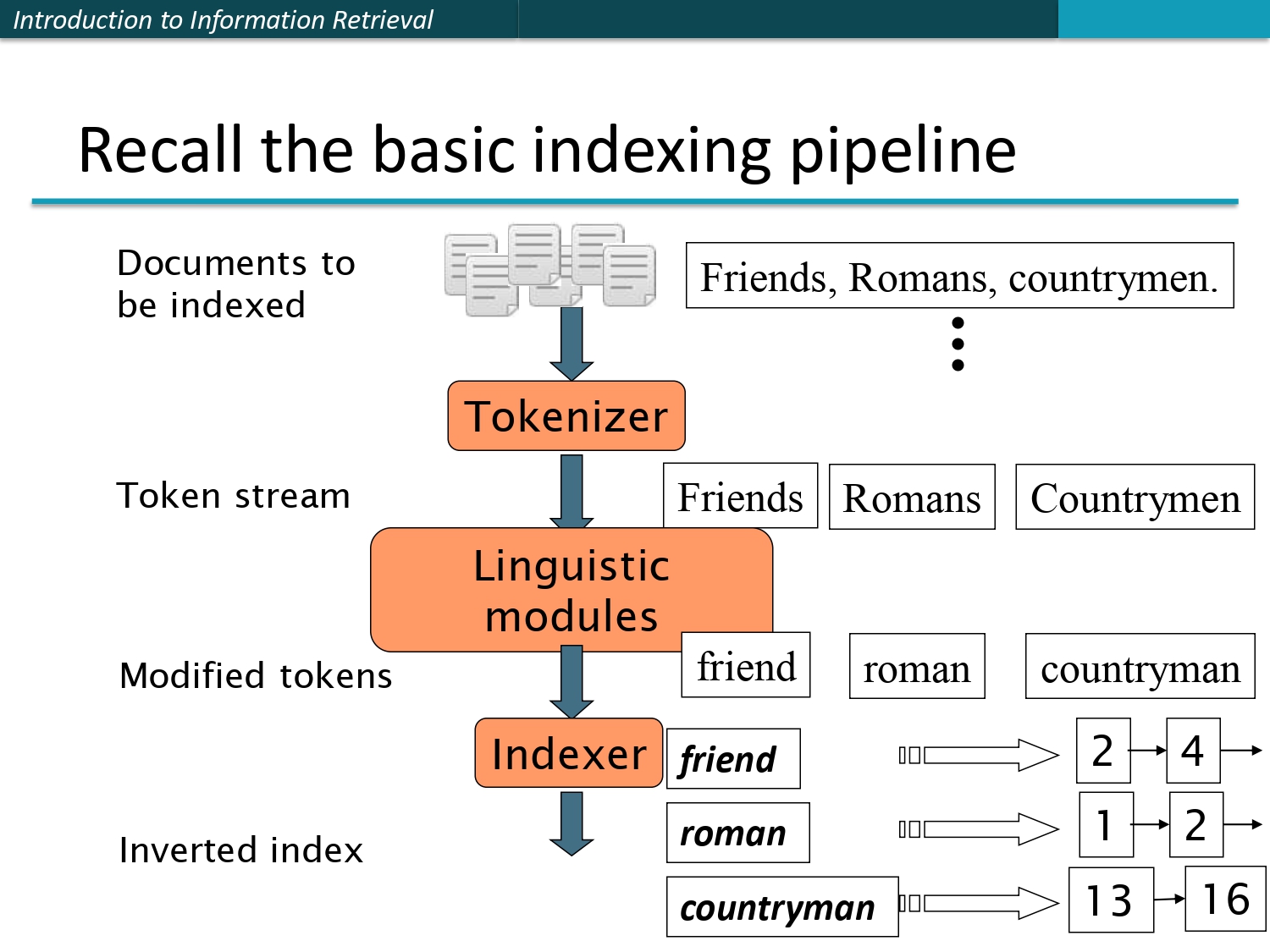
🔁 خط الإنتاج.. من الفوضى للفهرس!
هاي الصورة هي "قلب" الموضوع كله — بتحكيلك رحلة أي كلمة من لحظة ما تكون في مستند "خام" لغاية ما تتحول
لـ Inverted Index جاهز للبحث.
1. Documents to be indexed: هاي المواد الخام — ملفات، إيميلات،
صفحات ويب، ما بيهمك شكلها، المهم فيها نصوص.
2. Tokenizer: أول محطة عملية — بياخذ الجمل ويقطعها لكلمات مفردة
نسميها Tokens. مثلاً "Friends, Romans, countrymen." بتطلع منها:
Friends | Romans | Countrymen.
3. Linguistic Modules: هون الكلمات بتتعدل وترجع لجذرها — Friends بتصير friend، وRomans بتصير roman. الهدف: إنك لما
تدور على "friend" تلاقي كمان "friends" و"friendly"!
4. Indexer: آخر محطة — بياخذ الكلمات المعالجة ويبني الـ Inverted Index: كل كلمة ومعها أرقام المستندات اللي ظهرت فيها. friend → [2, 4] يعني الكلمة موجودة بالمستند 2 والمستند 4.

📂 قبل ما تبدأ.. افهم شو قدامك!
قبل ما السيستم يبدأ يفهرس أي ملف، لازم يسأل 3 أسئلة جوهرية — بدونها بكون أعمى تماماً:
What format is it in? هل الملف PDF؟ Word؟ Excel؟ HTML؟ كل صيغة لها طريقة مختلفة
لاستخراج النص منها.
What language is it in? عربي؟ إنجليزي؟ صيني؟ اللغة بتحدد قواعد
التقطيع والمعالجة اللي بنطبقها.
What character set is in use? هل الترميز UTF-8؟ CP1252؟ غلطة هون وبقرأ الملف
بالغلط وبطلع نص "مكسر".
تحديد هالمعلومات هو عملياً Classification Problem — السيستم لازم
يحزر ويصنف الملف بناءً على "بصماته" الداخلية.

⚠️ الأمور مش دايماً بسيطة!
تخيل إنك بدك تفهرس إيميلات شركة دولية — الوضع بيصير معقد سريعاً:
مستندات من لغات كثيرة: الـ Index
الواحد ممكن يحتوي كلمات عربية، إنجليزية، فرنسية، وصينية — كلها مع بعض! وكل لغة بدها معالجة
مختلفة.
French email with a German PDF: إيميل مكتوب بالفرنسي، ومعه مرفق
PDF باللغة الألمانية — السيستم لازم يعرف يتعامل مع الاثنين معاً.
French email quoting an English contract: إيميل فرنسي بداخله
اقتباس من عقد إنجليزي — بمستند واحد في لغتين مخلوطتين!
الخبر الكويس؟ في مكتبات Commercial وOpen Source متخصصة بتتعامل مع
هاي التعقيدات وبتحلها بشكل تلقائي — ما لازم نبني الحل من الصفر.

🤔 شو يعني "مستند واحد" أصلاً؟
سؤال بسيط بس إجابته مش واضحة! لما السيستم يرجع بـ Documents، شو يقصد
بالظبط؟ هون بنحكي عن موضوع اسمه Grain Size — يعني "حجم الوحدة".
A file? يعني كل ملف على حدة هو "مستند" واحد — هاض أبسط خيار.
An email? (mbox file) ملف الـ mbox ممكن يحتوي آلاف الإيميلات — هل نعتبر الملف كله مستند واحد؟ ولا
كل إيميل لحاله؟
Email with 5 attachments? إيميل ومعه 5 مرفقات — هل هو مستند
واحد؟ ولا 6 مستندات منفصلة؟ قرارك هون بأثر على دقة نتائج البحث!
A group of files (PPT, LaTeX): عرض PowerPoint أو ملف LaTeX مقسم
على صفحات HTML متعددة — هل كل صفحة مستند؟ ولا المجموعة كلها؟
مافيش إجابة "صح" واحدة — بتعتمد على طبيعة البيانات وشو بدك يطلع بنتائج البحث.


✂️ شو معناها "التقطيع"؟
الـ Tokenization هي أول خطوة حقيقية بتعمل فيها السيستم بالنص — ببساطة
بياخذ الجمل ويكسرها لوحدات صغيرة اسمها Tokens.
مثال عملي: الجملة "Friends, Romans and Countrymen" بتطلع منها 3
Tokens:
Friends و Romans و Countrymen — لاحظ إن الـ "and" ممكن يتشال كـ Stop Word لاحقاً.
تعريف الـ Token: هو "مثيل لسلسلة من الحروف" (instance of a sequence of characters) — يعني كل كلمة منفردة بعد
التقطيع.
مرشح للفهرس: كل Token بيطلع من هاي المرحلة بيصير Candidate عشان يدخل الفهرس — بس بعد مراحل معالجة إضافية (Further
Processing) رح نشرحها بالسلايدات الجاية.
السؤال الأهم هون: شو الـ Tokens "الصح" اللي لازم نطلعها؟ مش كل
حالة بسيطة!

🤯 مشاكل التقطيع.. مش بسيطة زي ما تفكر!
تقطيع النص على ورق واضح، بس بالواقع فيه حالات شايكة بتخلي السيستم يحتار:
Finland's capital → كيف نتعامل مع الـ apostrophe؟ نفصلها لـ
Finland + s ؟ ولا نخليها Finlands ؟ ولا Finland's ؟ كل خيار
بعطي نتائج بحث مختلفة!
Hewlett-Packard → الشحطة (Hyphen) بتفصل ولا لا؟ يعني Token واحد
HewlettPackard ولا ثنين Hewlett +
Packard؟ نفس المشكلة مع كلمات زي state-of-the-art و co-education وحتى
lower-case مقابل lowercase!
San Francisco → اسم المدينة — Token واحد ولا ثنين؟ لو فصلتهم،
حدا بيبحث عن "San Francisco" ما رح يلاقي إشي! ولو خليتهم مع بعض، حدا بيبحث عن "San" لحاله ما رح
يلاقي.
الحل العملي: ممكن تخلي المستخدم يحدد كيف يكتب الاستعلام، أو
تبني سيستم ذكي يتعامل مع الحالتين.

🔢 الأرقام.. مشكلة بحد ذاتها!
الأرقام مش كلمات، بس إهمالها خطأ كبير. شوف كيف الأرقام بتيجي بأشكال مختلفة خرافية:
تواريخ بأشكال مختلفة: 3/20/91 و
Mar. 12, 1991 و 20/3/91 — كلها بتحكي
عن نفس التاريخ بس بأشكال مختلفة تماماً. السيستم كيف يعرف يطابقهم؟
أرقام معقدة: 55 B.C. ، B-52 ، 324a3df234cb23e (مفتاح PGP) —
هون بزيد التعقيد!
أرقام التلفون: (800) 234-2333
فيها فراغات ورموز — بتلخبط الـ Tokenizer لأنه مش واضح وين تنتهي الكلمة.
ليش مهمة؟ المحركات القديمة كانت تتجاهل الأرقام كلياً، بس اليوم
هي مفيدة جداً — تخيل لو بدك تبحث عن كود خطأ زي Error 404 أو Stacktrace معين على الويب!
الحل الشائع: الأرقام غالباً بتتفهرس بشكل منفصل كـ Meta-data — زي تاريخ الإنشاء أو صيغة الملف — بدل ما تندمج مع النص
العادي.

📚 مثال عملي: فهرسين مش فهرس واحد!
هاي الصورة بتلخص فكرة ذهبية — السيستم الذكي ما بيبني فهرس واحد، بيبني فهرسين منفصلين!
تخيل مستند عنده:
تخيل مستند عنده:
- المحتوى: "Deep learning for medical imaging"
- التاريخ: 2024
- الصيغة: PDF
Content Index (فهرس المحتوى): بيفهرس الكلمات الفعلية في النص:
deep → doc1 ، learning → doc1 ،
medical → doc1.
Metadata Index (فهرس البيانات الوصفية): بيفهرس المعلومات
التنظيمية:
date:2024 → doc1 ، format:pdf →
doc1.
الفايدة الكبرى: هسا بتقدر تعمل استعلامات متقدمة زي:
deep learning AND date:2024 — بتلاقي مقالات Deep Learning من سنة
2024 بالضبط!
author:Abdullah AND format:pdf — كل PDF كتبه عبدالله!

🌏 لما ما في فراغات.. الأمور بتعقد!
بالإنجليزية الأمور بسيطة — في فراغ بين كل كلمة وثانية. بس في اللغتين الصينية واليابانية ما في فراغات بين الكلمات إطلاقاً!
مثال صيني: الجملة 莎拉波娃现在居住在美国东南部的佛罗里达。 بتحكي إن "شارابوفا تسكن حالياً في فلوريدا جنوب
شرق أمريكا" — بس الكلمات كلها ملزقة ببعض بدون أي فراغ!
المشكلة الحقيقية: السيستم مش ضامن إنه رح يقطّع الجملة بطريقة
وحيدة صحيحة — نفس التسلسل من الحروف ممكن يُقرأ وينقسم بأكثر من طريقة، وكل طريقة بتعطي معنى مختلف
تماماً!
الحل: يستخدموا خوارزميات متخصصة زي Segmentation algorithms اللي تحاول تحزر أفضل تقطيع بناءً على القاموس
والسياق.

🕌 لغتنا العربية.. فيها تفاصيل تقنية مهمة!
العربية لها "شخصية" مختلفة عند التعامل معها بالأنظمة — وفي 3 نقاط جوهرية اللي ذكرها الدكتور:
Bi-directional (BiDi): العربية من اليمين لليسار، بس لما يدخل
رقم بالنص (زي 1962) هو بيُكتب من اليسار لليمين — يعني في نفس السطر بتتعكس اتجاهين! السيستم لازم
يتعامل مع هاي الثنائية.
Complex Ligatures (تشبيك الحروف): حروفنا بتغير شكلها حسب موقعها
بالكلمة — الحرف في البداية بيختلف عن نفسه بالوسط وبالنهاية. وبعض الحروف بتلزق ببعض وتصير شكل
واحد (Ligature). هاد بيعقد عملية التعرف البصري على الأحرف.
Unicode vs Stored form: على الشاشة النص العربي يبدو معقداً بسبب
الاتجاهات والتشبيكات، بس بالسيرفر طريقة تخزينه (Stored form) بتكون Straightforward ومباشرة — يعني التعقيد بالعرض مش بالتخزين.
مثال من الشريحة: "استقلت الجزائر في سنة 1962 بعد 132 عاماً من
الاحتلال الفرنسي" — لاحظ كيف الأرقام 1962 و132 بتكتب لليسار بينما باقي النص لليمين!


🚫 كلمات الوقف.. نشيلها ولا نتركها؟
Stop Words هي الكلمات الشائعة جداً زي the,
a, and, to, be — اللي بتيجي بكل مستند تقريباً ومش بتعطي معنى مميز.
ليش المنطق القديم يشيلها؟ ما عندها semantic content، وكثيرة
جداً — أول 30 كلمة شائعة بتشكل ~30% من كل الـ postings.
ليش التوجه الحالي نتركها؟ تقنيات الضغط الحديثة خلّت مساحتها شبه
معدومة، والسيستم صار سريع بما يكفي إنه يتجاهل تأثيرها وقت البحث.
⚠️ بس لازم تبقى أحياناً! في Phrase
queries زي "King of Denmark"، وأسماء أغاني زي "To be or
not to be"، واستعلامات زي "flights to London".

🔤 التوحيد.. عشان الكل يتفاهم!
بعد التقطيع، الكلمات لازم تتوحد بشكل واحد — هاي بنسميها Normalization. الهدف: إنك لما تبحث تلاقي النتائج حتى لو كُتبت بشكل
مختلف.
مثال كلاسيكي: U.S.A. و USA — نفس الشيء بنقاط وبدون! السيستم لازم يطابقهم مع بعض.
النتيجة = Term: الـ Token يتحول لـ Term وهو اللي بنخزنه فعلياً بقاموس الـ IR system.
أشيع الطرق: حذف النقاط: U.S.A. ←
USA | حذف الشحطات: anti-discriminatory ← antidiscriminatory

🔡 الكبيرة والصغيرة.. فرّقوا ولا موحّدوا؟
Case Folding يعني تحويل كل الحروف لـ lowercase — عشان Apple وapple وAPPLE كلهم يُعتبروا نفس الكلمة.
ليش منطقي؟ الناس بالغالب بيكتبوا استعلاماتهم بالحروف الصغيرة
بغض النظر عن الكتابة الصحيحة.
الاستثناء — General Motors: لو حوّلناها لـ general motors ممكن تتطابق مع نصوص عن "المحركات العامة" وليس الشركة
— خطأ!
مثال Google الشهير: البحث عن C.A.T. كانت Google ترجع "cat"
القطة بدل Caterpillar — لأنه وحّد كل شيء!

🔍 بديل التوحيد: التوسيع!
بدل ما نوحّد الكلمات، في طريقة ثانية اسمها Expansion — لما المستخدم
يبحث عن كلمة، السيستم يضيف أشكالها المختلفة للبحث تلقائياً.
مثال — كلمة window:
بحث عن window → يبحث عن: window, windows
بحث عن windows → يبحث عن: Windows, windows, window
بحث عن Windows → يبحث عن: Windows فقط
بحث عن window → يبحث عن: window, windows
بحث عن windows → يبحث عن: Windows, windows, window
بحث عن Windows → يبحث عن: Windows فقط
الفرق عن Equivalence Classes: الـ Expansion أقوى وأشمل — بس أبطأ لأنه بيعمل عمليات أكثر وقت البحث.

📖 المترادفات.. تعامل مع الكلمات المتشابهة!
Thesaurus هو قاموس المترادفات — بيعرّف السيستم إن car = automobile وإن color = colour. السؤال: كيف نتعامل مع
هالمترادفات بالفهرسة؟
طريقة 1 — Equivalence Classes يدوية: نبني جدول يوحّد الكلمات
المترادفة — لما يجي مستند فيه كلمة automobile، نحتفظه تحت car-automobile (والعكس كذلك).
طريقة 2 — Query Expansion: لما يبحث المستخدم عن automobile، السيستم يبحث كمان عن car تلقائياً.
مشكلة الـ Thesaurus: بناءه يدوي ومكلف جداً — لازم خبراء لغويين
يحددوا العلاقات.


📚 الليما — الرجوع للشكل الأصلي!
Lemmatization يعني رجوع الكلمة لشكلها القاموسي الأساسي (Base form)،
بطريقة صحيحة مبنية على التحليل اللغوي.
مثال فعل التكوين: am, are, is →
be — كلهم أشكال من نفس الفعل الأساس.
مثال الأسماء: car, cars, car's,
cars' → car — كل أشكال الجمع والتملك ترجع
للمفرد.
نتيجة عملية: جملة "the boy's cars are
different colors" تتحول لـ the boy car be different
color.
الفرق عن Stemming: الليما بتعطي كلمة حقيقية موجودة بالقاموس، ليس مجرد تقطيع آلي.

✂️ الـ Stemming — القطع الخشن!
Stemming هو خوارزمية أبسط — بتأخذ الكلمة وتشيل من آخرها (اللواحق)
لتوصل لـ "جذر" متقريبي. مش بالضرورة كلمة حقيقية — بس كافية للفهرسة.
مثال: automate(s), automatic,
automation → كلهم بيصيروا automat — مش كلمة
حقيقية بترتيح بالقاموس، بس الكل تؗيجي بنفس النتيجة.
الفكرة العملية: جملة "for example
compressed and compression are both accepted as equivalent to compress" — بعد الـ
Stemming تصير: "for exampl compress and compress ar both accept
as equival to compress". الجذر واحد للكل!
ميزته: سريع وبسيط تقنياً. عيبه: مش دايماً صحيح لغوياً — ممكن يقطع كلمات بشكل خاطئ.

🧠 خوارزمية بورتر — أشهر Stemmer بالإنجليزي!
Porter's Algorithm هو أكثر خوارزمية Stemming استخداماً للإنجليزي —
وكان الجواب الأفضل لفترة طويلة.
فكرته الأساسية: بدل قواعد لغوية معقدة، بيعتمد على 5 مراحل (phases) تُطبق بالتسلسل، كل مرحلة فيها مجموعة أوامر
(commands) لحذف اللواحق.
النتائج: أثبتت الدراسات إنه في أقله نفس جودة أي خيار Stemming
آخر، وفي أحيان كثيرة أحسن منهم.

📜 شوف كيف بيشتغل بورتر!
مثال على قواعد بورتر — كل قاعدة بتشوف آخر الكلمة وتشيل اللاحق:
قواعد بسيطة:
sses → ss |
ies → i |
ational → ate |
tional → tion
Weight-sensitive rules (EMENT): بعض القواعد بتنظر لطول الكلمة —
مثلاً لاحقة EMENT:
replacement → replac (طويلة → تشال)
cement → cement (قصيرة → تبقى)
الخلاصة: بورتر بيطبق القواعد بالتسلسل، وبيراعي طول الكلمة عشان ما
يقطع بشكل خاطئ.
replacement → replac (طويلة → تشال)
cement → cement (قصيرة → تبقى)

🛠️ بورتر مش وحيد.. في خيارات ثانية!
حتى لو كان بورتر هو الأشهر، في خيارات أخرى للـ Stemming يستحق معرفتها:
Lovins Stemmer: ختار واحد (Single-pass) — بيشيل أطول لاحقة ممكنة دفعة وحدة. عنده
حوالي 250 قاعدة — أكثر من بورتر بس بختار واحد.
Paice/Husk Stemmer: خيار ثاني — أكثر عدوية من بورتر، بيشيل
لواحق أكثر — أحياناً أكثر من اللازم.
Snowball: إطار عمل حديث يسمح ببناء Stemmers للغات متعددة — مش
بس للإنجليزية، بيدعم فرنسي، ألماني، اسباني، وغيرهم. هو الخيار الحديث الأكثر شيوعاً.
الخلاصة: كل Stemmer وله فلسفته — اختيارك يعتمد على اللغة وطبيعة
بياناتك.

🌍 كل لغة الها طريقتها!
كل المعالجات اللي حكينا عنها — Tokenization وNormalization وStemming — هي مش عالمية بلا تغيير.
Language-specific: كل لغة عندها طريقتها الخاصة — قواعد التقطيع
بالعربية تختلف كلياً عن الإنجليزية أو الصينية.
Application-specific: حتى بنفس اللغة، سيستم بحث طبي بيحتاج
معالجة مختلفة عن محرك بحث قانوني — المصطلحات والتعامل معها مختلف.
الخبر الكويس: في plug-ins
جاهزة (Open Source وCommercial) تعالج هالفروقات تلقائياً — ما لازم تبني كل شيء من الصفر.

❓ السؤال المهم: هل الـ Stemming بيفيد فعلاً؟
الجواب: يعتمد! — مش عنده إجابة واحدة ثابتة لكل الحالات.
بالإنجليزي — نتائج مختلطة: الـ Stemming بيساعد بعض الاستعلامات
— بيرفع الـ Recall (تلاقي أكثر نتائج) — بس ممكن يضر Precision مع استعلامات أخرى.
مثال سيئ: operative (dentistry) ⇒
oper — كلمة موجودة بسياق طبي بتتقطع لجذر قصير جداً — فتصير بتفلت مع كلمات مثل opera, operation!
بالإسبانية والألمانية — مفيد جداً: هاللغات فيها تصريف
كثير والكلمة بتحمل لواحق كثيرة — هون الـ Stemming بيساعد بشكل واضح مقارنة بالإنجليزية.
الخلاصة: لا تعتمد عليه بعينين مغمضتين — اختبره على بياناتك وشوف شو
بيعطي نتائج أحسن.