هون بنبلش الجد! الـ Vector Space Model هو اللي نقل محركات البحث من مجرد
"كلمة موجودة أو لأ" إلى "قديش هاي الكلمة مهمة".
تخيل إن كل مستند هو نقطة في فضاء واسع، وكل كلمة هي بُعد جديد. قديش المستندات قريبة من بعض بيعتمد على
قديش محتواها متشابه. في هذا الشابتر رح نفهم الـ TF-IDF وكيف بنحسب الـ
Cosine Similarity عشان نطلع أدق النتائج.
أهلاً بك في عالم المتجهات 🚀


شو رح نتعلم اليوم؟ خارطة الطريق 🗺️
ركز ، هاض الشابتر هو العمود الفقري لمحركات البحث الحديثة. رح نمرق على 6 مواضيع أساسية وشاملة
وعميقة:
- Ranked retrieval: كيف بنرتب الملفات بدال الأصفار والواحدات.
- Scoring documents: إعطاء علامة لكل ملف عشان نعرف مين الأول ومين العاشر.
- Term frequency: قديش تكررت الكلمة في الملف (مقياس القوة).
- Collection statistics: إحصائيات عن كل الكلمات في كل الملفات.
- Weighting schemes: أنظمة الأوزان وكيف بنوزن كل كلمة.
- Vector space scoring: الرياضيات والفضاء اللي بنحسب فيه الـ Score النهائي.

عصر الـ Boolean.. ليش صار قديم؟ 🧐
كنا نستخدم الـ Boolean Retrieval، بس هاض النظام إله كواليسه:
نقاط القوة (للمين؟):
- ممتاز للـ Expert users اللي عارفين بالضبط وبكل دقة شو بدهم.
- كويس للتطبيقات المبرمجة اللي بتقدر "تبلع" آلاف النتائج وتتعامل معها.
العقبات والمشاكل:
- مش مناسب لغالبية الناس (Majority of users).
- اليوزر العادي ما بيعرف يكتب معادلات Boolean، أو بحسها "شغلة طويلة عريضة" وبدها مجهود كبير.
- اليوزر ما عنده طولة بال يدوّر بين آلاف النتائج (خصوصاً ببحث الويب.. مين بنزل لثاني صفحة بقوقل؟).

مشكلة الـ Feast or Famine 🍽️🚫
هون المعضلة الكبيرة في الـ Boolean.. يا ميت جوع يا ميت شبع!
المثال الشهير (ركز بالأرقام):
الخلاصة: الـ AND بتعطيك نتائج
قليلة جداً، والـ OR بتعطيك انفجار نتائج. وبدك "شطارة ومهارة" غير
طبيعية عشان تطلع عدد معقول ومفيد!
- استعلام "standard user dlink 650" طلع لنا 200,000 نتيجة! (مستحيل حدا ينتقيهم).
- بس لما اليوزر حاول يحدد النتائج وكتب "standard user dlink 650 no card found"، النتيجة صارت 0!

الموديلات المرتبة (Ranked Retrieval Models) 🏆
هون انقلبت الآية، وبطلنا نجاوب بـ "أه ولا" (Match or Not)، صرنا نجاوب بـ "ترتيب".
- Ranked Retrieval: بدال ما نبعث مجموعة ملفات عشوائية، بنرجع "ترتيب" (Ordering) لأفضل الملفات في المجموعة.
- Free text queries: هي ميزة إنك تكتب كلمات عادية باللغة البشرية، بدال استخدام الرموز والمعادلات المعقدة (Operators & Expressions).
ملاحظة ذكية: علمياً هم موضوعين منفصلين (الترتيب واللغة
العادية)، بس فعلياً وبأي نظام ناجح، دايماً بنربطهم مع بعض.

الـ Feast or Famine؟ انساها هون! 🛑✨
لما يكون النظام مرتب (Ranked System)، بطل يهمنا إذا فيه 100 ألف
ملف أو 10.. ليش؟
- ببساطة، إحنا بنعرض لليوزر أول k ≈ 10 نتائج بس (الصفحة
الأولى).
- هيك اليوزر ما بضيع ولا "بنغرقه" بكثرة الملفات الغير مفيدة.
القاعدة الذهبية: طول ما الـ Ranking algorithm شغال صح وبطلع أهم الملفات فوق، فعدد الملفات
الكلي بالحاوية بطل يشكل أي مشكلة.

الـ Scoring.. الأساس والميزان ⚖️
بدنا نطلع الملفات اللي "غالباً" رح تكون مفيدة لليوزر. بس كيف بدنا نعرف إن هاض الملف هو رقم 1
وهاض رقم 2؟ عن طريق الـ Scoring.
الآلية:
بدنا نعطي كل ملف "علامة" (Score) تابعة للاستعلام، غالباً بنحسبها بين 0 و 1.
المعنى التقني: هاض الـ Score هو مقياس لـ "قديش الملف
والـ Query بيطابقوا بعض" (Match). كل ما كبر الـ Score، يعني
الملف Relevant أكثر ومكانه الطبيعي فوق.

المحاولة الأولى.. معامل جيكارد (Jaccard Coefficient) 📐
أول فكرة ذكية عشان نحسب "التشابه" بين المستعلام (Query) والمستند
(Document) هي الـ Jaccard
coefficient.
القانون:
`jaccard(A, B) = |A ∩ B| / |A ∪ B|`
يعني: (عدد الكلمات المشتركة) تقسيم (إجمالي عدد الكلمات الفريدة في الاثنين مع بعض).
يعني: (عدد الكلمات المشتركة) تقسيم (إجمالي عدد الكلمات الفريدة في الاثنين مع بعض).
قواعد لازم تعرفها:
- jaccard(A, A) = 1: أي إشي بيشبه حاله 100%.
- jaccard(A, B) = 0: إذا ما في ولا كلمة مشتركة، التشابه صفر.
- دائماً الرقم بطلع بين 0 و 1، ومش لازم يكونوا الملفين نفس الحجم!

مثال عملي.. كيف بنحسب الـ Jaccard؟ 📝
تعال نجرب نحسب علامة ملفين بالنسبة للاستعلام: ides of march.
المدخلات:
- Query: {ides, of, march} (3 كلمات).
- Doc 1: "caesar died in march" -> {caesar, died, in, march} (4 كلمات).
- Doc 2: "the long march" -> {the, long, march} (3 كلمات).
الحسبة:
النتيجة: الملف الثاني فاز وحصل علامة أعلى بالاعتماد على
Jaccard!
- الـ Intersection (المشترك) في الحالتين هو كلمة وحدة بس: "march".
- للملف الأول: 1 مشترك / 6 إجمالي (اتحاد) = 0.16.
- للملف الثاني: 1 مشترك / 5 إجمالي (اتحاد) = 0.20.

ليش الـ Jaccard "مش قد المقام"؟ ❌🧐
بالرغم من بساطته، بس الـ Jaccard عنده مشاكل بتخليه ما يزبط للترتيب
الحقيقي في محركات البحث:
- تكرار الكلمات (Term Frequency): ما بهتم إذا الكلمة تكررت مرة أو 100 مرة بالملف! هو بس بشوف موجودة أو لأ.
- الكلمات النادرة (Rare terms): إحنا بنعرف إن الكلمة النادرة مفيدة أكثر بالبحث (Informative)، بس Jaccard بعامل كل الكلمات نفس الإشي.
- طول الملف: محتاجين طريقة أحسن وأكثر تطوراً لعمل Normalization للطول بدال مجرد "الاتحاد".

كيف بدنا نحسب الـ Score الصح؟ ⚖️
بدنا طريقة تعطينا علامة منطقية لكل ملف بالنسبة لأي استعلام (Query-document matching).
المبادئ الأساسية للموضوع:
ركز خالي، هاي هي البداية عشان نطور أنظمة أوزان وبدائل (Alternatives) أحسن بكثير من الـ Jaccard.
- لو الاستعلام فيه كلمة وحدة، والملف ما فيه هاي الكلمة -> الـ Score لازم يكون 0.
- كل ما تكررت الكلمة أكثر بالملف، لازم الـ Score يزيد (منطقياً يعني).
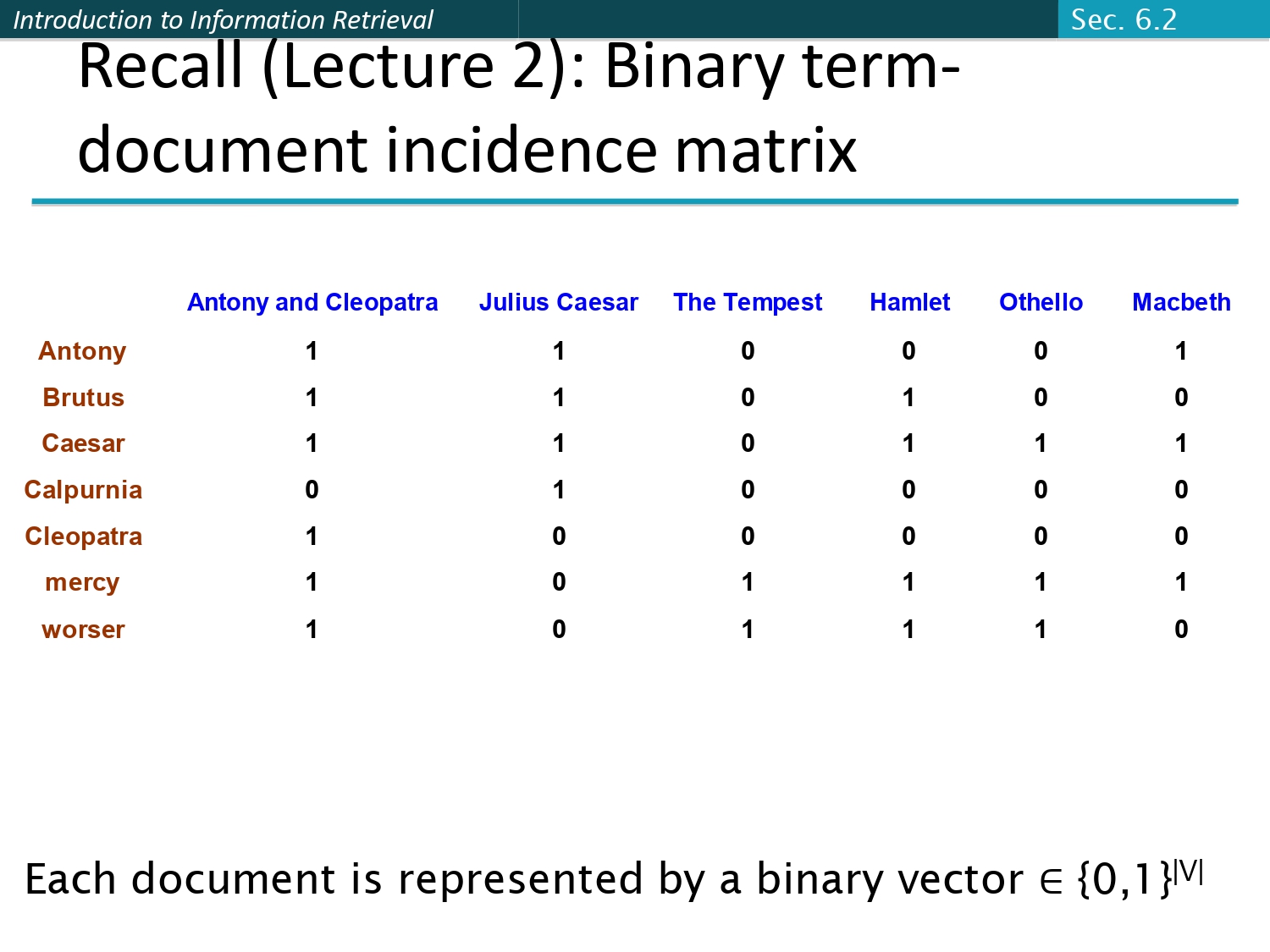
تذكير بالماضي.. المصفوفة الثنائية (Binary Matrix) 💾
تذكروا لما كنا نمثل الملفات كأصفار وواحدات في المحاضرات الأولى؟
في الـ Binary term-document incidence matrix، كل ملف كان عبارة
عن Binary Vector من الأصفار والواحدات.
المثال: كلمة "Antony" موجودة في مسرحية "Antony and Cleopatra"
بنحط 1، مش موجودة في "The Tempest" بنحط 0. هاض النظام كان مريح بس ما بعطينا "تكرار".

النقلة النوعية.. مصفوفة التعداد (Count Matrix) 🔢🚀
بدال ما نسجل "موجود أو لأ"، هون صرنا نسجل "قديش مرة موجود" في كل ملف.
هون بنتعامل مع Count vector لكل ملف، وهو عبارة عن عمود في
المصفوفة.
بالمثال: كلمة "Antony" تكررت 157 مرة في أول ملف، بينما كلمة "Brutus" تكررت 4 مرات بس. هاض التكرار هو الأساس اللي رح نبني عليه الأوزان.

نموذج "كيس الكلمات" (Bag of Words Model) 👜
ركز في تمثيل الـ Vectors إحنا بنرمي "ترتيب" الكلمات وراء
ظهرنا تماماً.
المبدأ:
النظام بعتبر إن الملف عبارة عن "كيس" مليان كلمات بدون ترتيب.
مشكلة الترتيب: جملة "John is quicker than Mary" وجملة "Mary is quicker than John" الهن نفس الـ Vector بالظبط!
ملاحظة: هاض بعتبر "خطوة لورا" مقارنة بالـ Positional index اللي كان بعرف الترتيب والمكان، بس للترتيب العام
والـ Scoring، هاض الموديل شغال زي الحلاوة وممتاز جداً.
مشكلة الترتيب: جملة "John is quicker than Mary" وجملة "Mary is quicker than John" الهن نفس الـ Vector بالظبط!

الـ Term Frequency (tf).. قديش تكررت؟ 🔢
هون دخلنا بالعمق. الـ tf هو ببساطة "عدد مرات تكرار الكلمة داخل
الملف الواحد".
ليش الـ Raw tf مش كويسة؟
القاعدة: العلاقة بين "الرابط" (Relevance) و "التكرار" مش خطية
(Not proportional). يعني الزيادة في الأهمية بتهدا وما بتزيد بنفس
سرعة التكرار الضخم، وعشان هيك لازم نحل "طمع" الأرقام الكبيرة.
- إذا ملف فيه الكلمة 10 مرات، أكيد هو أهم من ملف فيه الكلمة مرة وحدة.
- بس: هل هو أهم بـ 10 أضعاف؟ طبعاً لأ!

وزن اللوغاريتم (Log-frequency Weighting) 📉
عشان نحل مشكلة التكرار الضخم وما نخلي ملف "يطغى" عالثاني بس بسبب التكرار، بنستخدم اللوغاريتم.
المعادلة الذهبية:
w = 1 + log10(tf) (إذا التكرار أكبر من صفر، وإلا بكون الوزن
صفر).
شوف كيف الأرقام بتهدا (أمثلة):
الـ Score النهائي لأي ملف هو عبارة عن "مجموع" أوزان الكلمات
المشتركة ببن الاستعلام والملف. وإذا ما في مشترك، النتيجة صفر.
- تكرار 1 -> وزن 1 | تكرار 2 -> وزن 1.3
- تكرار 10 -> وزن 2 | تكرار 1000 -> وزن 4 بس!

الكلمات النادرة.. كنز المعلومات! 💎
مش كل الكلمات "ولاد تسعة" بالبحث. الكلمات النادرة إلها هيبة وقوة تمييز عالية جداً!
القصد: إحنا بدنا نعطي وزن عالي جداً للكلمة اللي "نادرة"
في كل المجموعة، لأنها لما تظهر في ملف، بكون هاض الملف هو المطلب الحقيقي لليوزر.
- الكلمات العادية (Frequent terms) زي كلمات الستوب ووردز (الـ، من، في) ما بتميز ملف عن الثاني.
- الكلمات النادرة (Rare terms) زي كلمة "arachnocentric" هي اللي بتدلك على الملفات الصح فوراً.

الـ Collection vs Document Frequency 📊
هون بدنا نفرق بين مصطلحين بيلخبطوا بس الفرق بينهم هو اللي بطلع الـ Weight الصح:
مثال ذكي من السلايد: كلمة "insurance" تكررت 10440 مرة بـ 3997
ملف. بينما كلمة "try" تكررت 10422 مرة بس بـ 8760 ملف!
مين أحسن للبحث؟ بالرغم من تقارب التكرار الكلي (cf)، إلا أن "insurance" أفضل لأن الـ df تبعها أقل، فبتوزن الملفات بطريقة أميز.
- Collection Frequency (cf): عدد مرات ظهور الكلمة "بكل" المجموعة بكل ملفاتها.
- Document Frequency (df): عدد "الملفات" اللي ظهرت فيها الكلمة (لو مرة وحدة على الأقل).
مين أحسن للبحث؟ بالرغم من تقارب التكرار الكلي (cf)، إلا أن "insurance" أفضل لأن الـ df تبعها أقل، فبتوزن الملفات بطريقة أميز.

وزن الـ idf.. ميزان الندرة ⚖️
عشان نحسب وزن الندرة، بنستخدم الـ Inverse Document Frequency
(idf).
المعادلة:
idf = log10(N/df)
حيث N هو عدد الملفات الكلية، و df هو كم ملف فيه هاي الكلمة.
حيث N هو عدد الملفات الكلية، و df هو كم ملف فيه هاي الكلمة.
ليش بنعمل هيك؟
عشان الكلمة اللي الـ df تبعها صغير (نادرة)، تطلع قيمة الـ
idf تبعها كبيرة. وبنستخدم الـ log عشان "نخمّد" الزيادة ونخليها
منطقية بدال ما تكون جبارة.

مثال الـ idf.. بالأرقام بنفهم! 🔢🔦
تخيل عندنا مليون ملف (N = 1,000,000)، شوف كيف الـ idf بتغير حسب كم ملف ظهرت فيه الكلمة (df):
خلاصة: كل كلمة في المجموعة إلها قيمة idf وحدة بتمثل "قوتها" الثابتة في المجموعة.
- calpurnia (موجودة بملف 1): الـ idf = 6 (نادرة جداً).
- animal (بـ 100 ملف): الـ idf = 4.
- sunday (بـ 1000 ملف): الـ idf = 3.
- the (بكل المليون ملف): الـ idf = 0 (ما إلها فايدة بالتمييز).

أثر الـ idf على الترتيب.. متى بحكي كلمته؟ 🗣️
ركز خالي، الـ idf مش دايماً بغير النتيجة ولازم تعرف ليش عشان ما
تنعجق بالامتحان.
ملاحظة صاعقة:
لو بحثت عن كلمة وحدة بس (زي "iPhone")، الـ idf ما إله أي
أثر على ترتيب الملفات! ليش؟ لأنه رقم ثابت رح ينضرب بكل الملفات اللي فيها الكلمة،
فما رح يغير ترتيب مين قبل مين في القائمة النهائية.
متى بصير "وحش"؟
لما يكون عندك كلمتين أو أكثر. مثلاً استعلام "capricious
person": الـ idf رح يخلي كلمة "capricious" (لأنها نادرة) وزنها أثقل بكثير من كلمة
"person" (لأنها شائعة). هيك الملف اللي فيه الكلمة النادرة بطلع للأول فوراً بفضل قوة الـ idf.

خلطة الـ tf-idf.. سر المهنة! 🍲🔥
هون دمجنا القوتين مع بعض عشان نطلع الوزن النهائي والمثالي (tf-idf
weight).
تنبيه: الـ "-" في tf-idf هي مجرد شحطة مش علامة طرح! وممكن
نسميها كمان tf.idf أو tf x idf. وهي
أشهر طريقة وزن في الـ IR.
المكونات:
هو حاصل ضرب وزن التكرار (tf) في وزن الندرة (idf).
المعادلة: w = log(1+tf) × log10(N/df)
المعادلة: w = log(1+tf) × log10(N/df)
- بزيد كل ما زاد تكرار الكلمة داخل الملف الواحد (tf).
- بزيد كل ما كانت الكلمة نادرة وصعبة في المجموعة كاملة (idf).

الـ Score النهائي.. إجماع الأوزان ⚖️🏆
كيف بنحسب العلامة النهائية للملف بالنسبة للاستعلام اللي كتبه اليوزر؟
القاعدة: نجمع وزن الـ tf-idf
لكل الكلمات المشتركة بين الـ Query والـ Doc.
المعادلة العامة: Score(q, d) = Σ tf.idf_t,d
المعادلة العامة: Score(q, d) = Σ tf.idf_t,d
فيه "موديلات" واختلافات (Variants) كثيرة في طريقة الحسبة:
- طريقة حساب الـ tf (بلوغاريتم أو بدون).
- هل بنطبق أوزان على كلمات الاستعلام (Query terms) كمان ولا لأ؟ .. وغيرها من التفاصيل.

التطور الطبيعي للمصفوفة.. من 0 لـ Weight 📈
شوف كيف تطور تفكيرنا التقني من بداية المادة لحد هسا:
هيك صار كل ملف عبارة عن متجه من القيم الحقيقية (Real-valued
vector) بيمثل هويته الحقيقية.
- بدأنا بـ Binary Matrix (أه موجود أو لأ - 0 و 1).
- بعدين رحنا للـ Count Matrix (قديش مرة تكرر - أرقام صحيحة).
- وهسا وصلنا للصفوة: Weight Matrix (أوزان دقيقة بتمثل أهمية كل كلمة في الملف).

الملفات كمتجهات في الفضاء 🌌🚀
تخيل الملف عبارة عن "نقطة" أو "سهم" في فضاء ضخم جداً بنسميه Vector
Space.
حقيقة تقنية: هاي الـ Vectors
هي Sparse، لأن الملف الواحد مستحيل يحتوي كل كلمات الدنيا، فأغلب
خاناته أصفار.
- الأبعاد (Axes): كل كلمة فريدة في القاموس هي عبارة عن "محور" في هاض الفضاء.
- حجم الفضاء: بنحكي عن فضاء عالي الأبعاد (High-dimensional)، بوصل مئات الآلاف أو الملايين في محركات البحث.

الاستعلام كمان صار Vector! 🏹🎯
السر الكبير في الـ Vector Space Model هو إننا بنعامل كل إشي بنفس
الطريقة.
الفكرة 1: بنمثل الـ Query كـ
Vector في نفس الفضاء تبع الملفات.
الفكرة 2: بنرتب الملفات حسب قربها (Proximity) من متجه الاستعلام.
الفكرة 2: بنرتب الملفات حسب قربها (Proximity) من متجه الاستعلام.
القرب = التشابه. وكل ما كان الملف "أقرب" هندسياً
للاستعلام، بكون هو الملف الأنسب لليوزر. القرب هو عكس المسافة هندسياً.

قياس القرب.. هل نستخدم المسافة؟ 📏🤔
هون بلشنا الجد! بدنا نحول كلمة "قرب" أو "تشابه" لكلام رياضي نقدر نحسبه برمجياً.
السبب الجوهري: المسافة الإقليدية بتكون كبيرة (large) لما يكون عندك ملفات بأطوال مختلفة (different lengths)، حتى لو كانت بتحكي عن نفس الموضوع بالظبط. هيك بنكون ظلمنا الملفات لمجرد إنها طويلة!
أول فكرة بتخطر عبال أي حد (First cut) هي إننا نقيس المسافة بين
رؤوس المتجهات، وبنسميها الـ Euclidean distance.
بس ركز خالي: السلايد بقولك إنها فكرة سيئة (bad idea)!
السبب الجوهري: المسافة الإقليدية بتكون كبيرة (large) لما يكون عندك ملفات بأطوال مختلفة (different lengths)، حتى لو كانت بتحكي عن نفس الموضوع بالظبط. هيك بنكون ظلمنا الملفات لمجرد إنها طويلة!

ليش المسافة بتخدعنا؟ 🕵️♂️❌
شوف الرسمة عندك الملف d1 والملف d2.
هيك النظام رح يعتبرهم بعاد عن بعض بسبب الطول، وهاض غلط شنيع في أنظمة البحث الحقيقية.
- الاثنين بطلعوا بنفس الاتجاه تقريباً، يعني بحكوا عن نفس المواضيع (Gossip).
- بس لأن d2 أطول بكثير، المسافة بين "رأس السهم" تبع d1 و d2 طلعت كبيرة جداً.

الحل في الزاوية.. مش المسافة! 📐💡
تخيل عندي ملف d وجبت نفس الملف ونسخته ولصقته تحته صار اسمه
d'.
الفكرة العبقرية: رتب الملفات حسب "الزاوية" اللي بصنعوها مع
الاستعلام، هيك بنضمن إننا بنقيس "المعنى" مش "الطول".
- من ناحية المعنى: هم نفس المحتوى بالظبط (Semantically identical).
- المسافة: رح تطلع كبيرة لن المسافة الإقليدية بتزيد بزيادة الطول.
- الزاوية: الزاوية بينهم صفر! يعني تطابق تام 100%.

من الزاوية للـ Cosine.. الرياضيات بتدخل! 📈⚖️
الحكي عن الزوايا حلو، بس برمجياً أسهل بكثير نحسب الـ Cosine
للزاوية بدال الزاوية نفسها.
الـ Cosine similarity بكون محصور بين [0, 1] في حالتنا (لأن الأوزان
كلها موجبة)، وكل ما قرب ع الـ 1 بكون التشابه توب.
- لما الزاوية "تقل"، الـ Cosine "بزيد".
- يعني: الترتيب حسب الزاوية (بشكل تنازلي) هو نفسه الترتيب حسب الـ Cosine (بشكل تصاعدي).
هاي الرسمة للي بحبوا الرياضيات والهندسة.
السؤال القوي: كيف نحسب الـ Cosine بين الاستعلام والملفات برمجياً وبسرعة؟
قاعدة ذهبية: لما الزاوية تكون 0 (الملفات منطبقة على بعض)، الـ Cosine بكون 1 (أعلى تشابه ممكن). وكل ما كبرت الزاوية، القيمة بتنزل.
إحنا بهمنا الجزء الأول من المنحنى؛ لأن أغلب الزوايا في الـ IR بتكون بين الـ 0 والـ 90 (لأنه
الأوزان كلها موجبة).
السؤال القوي: كيف نحسب الـ Cosine بين الاستعلام والملفات برمجياً وبسرعة؟

توحيد الأطوال (Length Normalization) 📏⚖️
عشان نخلي الملف الطويل والقصير "ولاد تسعة" بالوزن، لازم نوحد أطوال ملفاتنا كلها.
الـ L2 norm: هي معادلة بتحسب "طول السهم" الحقيقي في الفضاء:
||x||_2 = sqrt(Σ x_i^2)
الحل: بنقسم كل وزن في الـ Vector على طوله الإجمالي.
هيك بنحول كل الأسهم لأسهم طولها "1" بالظبط، وبصيروا كلهم موجودين على سطح "كره" وحدة.
بهاي الحركة، الملفات الطويلة والقصيرة بصير أوزانها قابلة للمقارنة والعدل.

معادلة الـ Cosine similarity 🧪🔢
هاي هي المعادلة اللي بنستخدمها في عالم الـ IR (وهي من أهم معادلات الشابتر):
cos(q, d) = (q • d) / (|q| |d|)
شو بصير جوا المعادلة؟
- البسط: هو الـ Dot Product (ضرب كل وزن باللي بقابله وجمع الناتج النهائي).
- المقام: هو حاصل ضرب أطوال المتجهات عشان نلغي أثر الطول ونطلّع الـ Cosine الصافي.

الـ Cosine للمتجهات الموحدة ⚡🏹
شو بصير لو إحنا أصلاً قررنا نعمل Normalization للملفات والاستعلام
من البداية؟
cos(q, d) = q • d = Σ q_i d_i
الروعة في الموضوع: الحسبة بتصير سريعة جداً؛ بس بنعمل
Dot Product السادة (ضرب وجمع) بدون ما نقسم على أي أطوال، لأن
المقام صار قيمته "1" وما اله داعي.
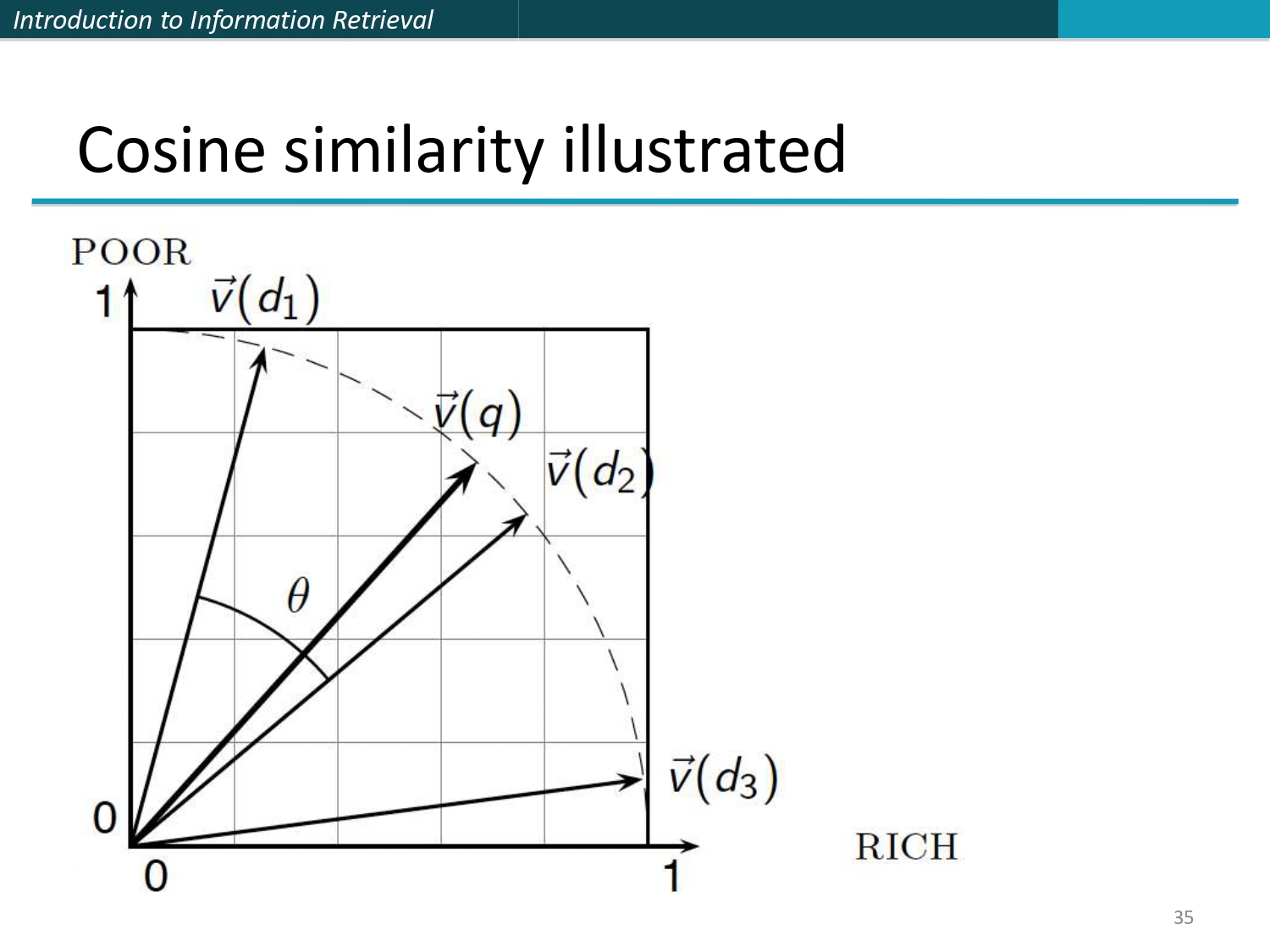
رسمة الـ Cosine.. الصورة وضحت! 🖼️🎯
شوف خالي كيف الملفات d1, d2, d3 صاروا كلهم "مصفطين" على نفس
القوس (لأن طولهم صار 1).
هيك محرك البحث بطل ينخدع بحجم الملف، وصار يركز بالظبط على "المعنى" والكلمات المشتركة.
- الزاوية θ هي اللي بتقرر مين الأقرب للاستعلام q.
- الملفات اللي بتقرب من اتجاه q بكون الـ Cosine تبعها قريب من الـ 1، يعني هي الأهم.

مثال التشابه بين 3 روايات.. بالأرقام! 📚🔢
هون عنا مثال حقيقي لنفهم كيف بنطبق الـ Cosine Similarity على 3
روايات مشهورة:
- SaS: Sense and Sensibility
- PaP: Pride and Prejudice
- WH: Wuthering Heights
الجدول الأول: بوضح تكرار كلمات معينة (affection, jealous,
gossip, wuthering) في كل رواية.
ملاحظة: هون رح نستخدم الـ Counts (التعداد الخام) فقط وبدون idf عشان نبسط الفكرة في البداية.
ملاحظة: هون رح نستخدم الـ Counts (التعداد الخام) فقط وبدون idf عشان نبسط الفكرة في البداية.

من التكرار للأوزان والتوحيد 📏⚖️
ركز بالحسبة هون لأنها "لب" الموضوع وكيف بنحول الأرقام لنتائج منطقية:
الهدف: التخلص من أثر طول الملف والتركيز فقط على "اتجاه" وتوزيع
الكلمات فيه.
- Log frequency weighting: حولنا الأرقام الكبيرة لقيم أصغر باستخدام اللوغاريتم 1 + log(tf).
- Length Normalization: حسبنا طول المتجه (تربيع القيم، جمعهم، أخذ الجذر) وقسمنا كل وزن عليه. مثلاً رواية SaS طولها طلع 3.87.
- النتيجة النهائية (Cosine):
- تشابه SaS و PaP هو 0.94 (جداً قريبين)!
- بينما WH بعيدة عنهم بنسب 0.79 و 0.69.

خوارزمية حساب الـ Cosine Score 💻🛠️
هاي هي الخطوات البرمجية (Algorithm) اللي بمشي عليها محرك البحث
عشان يفرز النتائج:
- ١. بنصفر مصفوفة العلامات Scores لكل الملفات.
- ٢. لكل كلمة في الاستعلام (query term)، بنحسب وزنها وبنفتح الـ Postings List تبعتها.
- ٣. لكل ملف موجود في القائمة، بنزيد على علامته حاصل ضرب وزنه بوزن الكلمة في الاستعلام: Scores[d] += w_t,d × w_t,q.
- ٤. في النهاية بنقسم كل علامة على طول الملف Length[d] لضمان العدل.
- ٥. بنرجع أعلى K نتائج (مثلاً أول 10) لليوزر.

ملاحظات تقنية على الحساب ⚡🚀
محركات البحث لازم تكون سريعة جداً، وعشان هيك بنطبق شوية تكتيكات:
- TAAT vs DAAT: الخوارزمية السابقة بتعالج "كلمة كلمة" (Term-at-a-time)، وممكن نعدلها لتعالج "ملف ملف" (Document-at-a-time).
- توفير المساحة: تخزين الوزن كـ float في كل "Posting" مكلف جداً، الأحسن نخزن الـ tf بس، ونخلي الـ idf في رأس القائمة.
- الفرز السريع: بدال ما نرتب كل ملفات الدنيا، بنستخدم Priority Queue (زي الـ Heap) عشان نطلع أعلى K ملفات بسرعة البرق.

عالم الـ SMART Notation.. خيارات لا تنتهي! 🔠📋
الـ tf-idf مش مجرد معادلة وحدة، هو "نظام" كامل فيه تنويعات كثيرة
بنسميها الـ SMART Notation:
الاسم بكون مكون من 3 أحرف (مثلاً lnc.ltn):
هيك بنقدر نوصف "خلطة" الوزن المستخدمة للاستعلام وللملفات بدقة وسهولة.
- الحرف الأول لـ Term Frequency (طبيعي، لوغاريتم، بولين..).
- الحرف الثاني لـ Document Frequency (بدون، idf، احتمالي..).
- الحرف الثالث لـ Normalization (بدون، Cosine، حجم الملف..).

الفرق بين وزن الاستعلام ووزن الملف 🏹⚖️
كثير من محركات البحث بتستخدم طريقة وزن للملفات مختلفة عن الطريقة اللي بتوزن فيها الاستعلام.
SMART Notation: هي الطريقة اللي بنوصف فيها هاض التوليف
(ddd.qqq).
مثلاً في نظام Inc.ltc المشهور جداً:
- للملف (Inc): بنستخدم logarithmic tf، وبدون idf، مع cosine normalization.
- للاستعلام (ltc): بنستخدم لوغاريتم، مع idf، ومع normalization.
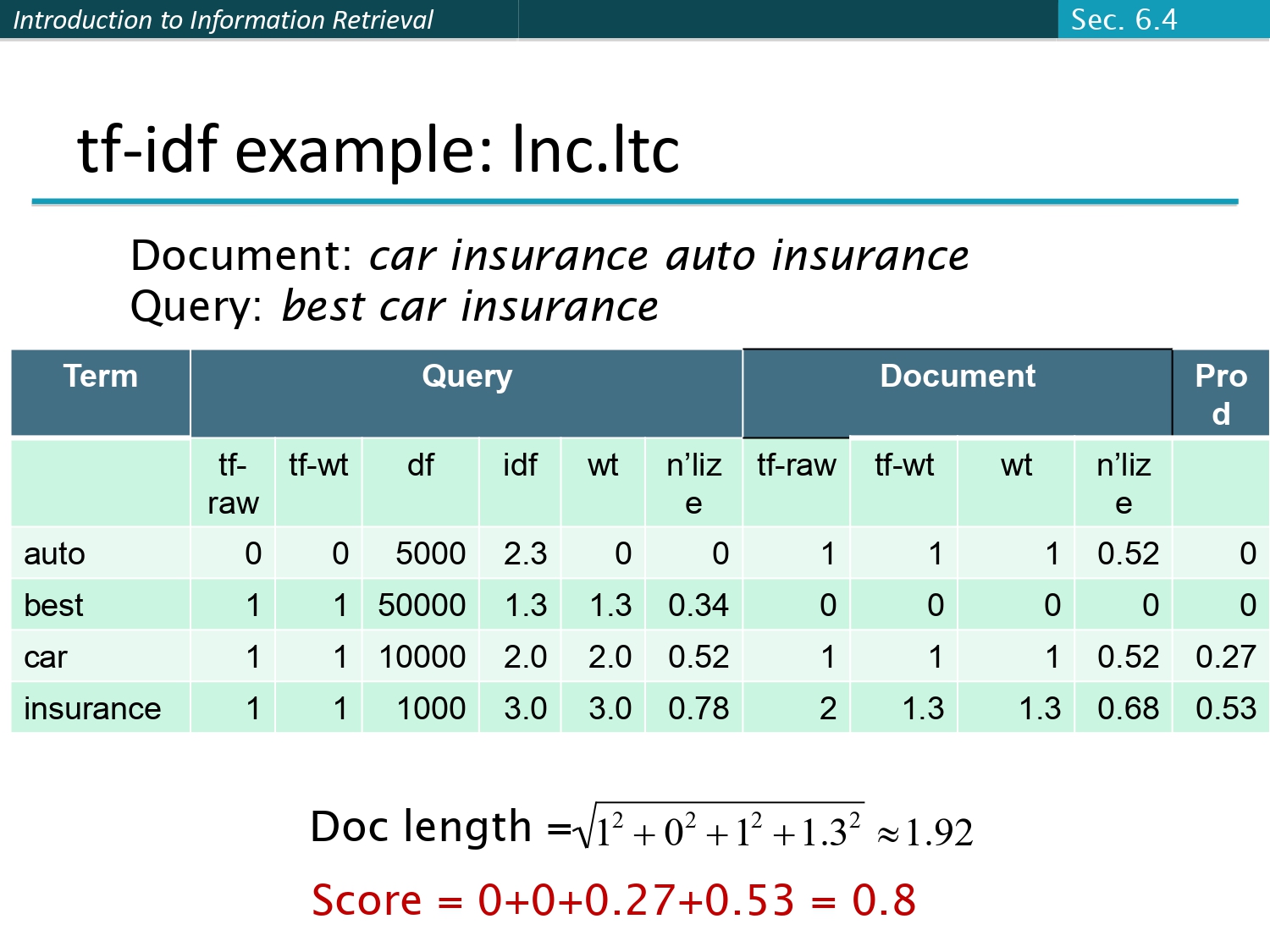
مثال تطبيقي شامل (Inc.ltc) 🚗📉
شوف خالي كيف الأرقام بتتحرك في نظام حقيقي. الجدول بفرجينا الحسابات لكل كلمة (auto, best, car,
insurance).
لاحظ كيف بنحسب الـ tf-wt والـ idf، وبعدين بنعمل Normalization
لكل واحد لحاله.
الحسبة النهائية: ضربنا أوزان الاستعلام بأوزان الملف
وجمعناهم: 0 + 0 + 0.27 + 0.53 = 0.8. هاض الـ Score النهائي
للملف.

خلاصة الرحلة في الـ Vector Space
- مثل الاستعلام كـ weighted tf-idf vector.
- مثل كل ملف كـ weighted tf-idf vector.
- احسب الـ cosine similarity بينهم.
- رتب الملفات حسب الـ Score ورجّع التوب للمستخدم.